So, I'm playing around with code for the asynchronous I/O system. In a number of ways I'm finding that doing things "the right way" (fully thread safe, fully error checked and tolerant, etc.) is both cumbersome to code and slow/bloated when compiled (if you haven't figured it out by now, I step through most new code in release build, to see what the generated assembly looks like). Both of these are very much in opposition to the entire LibQ paradigm; so, I've decided to use a lazy model for the design of this thing.
What that means is that it's sensitive to how you use it. If you follow the rules (particularly with respect to call orders, and what operations you do from different threads simultaneously), nobody gets hurt; if you don't, you can expect that sometime, somewhere, anything ranging from subtle errors to spectacular crashes will slink into your program.
For a couple examples, calling CFile::Open (on the same CFile variable) at the same time from two different threads means death. Closing a file from one thread while another thread is doing a read/write on that file means death. Trying to use the same CAsyncStatus for an operation before the last operation using that CAsyncStatus has completed means death. Get the picture? Most of it's just common sense, but some of it I'll have to explicitly document.
Sunday, October 30, 2005
Saturday, October 29, 2005
Positional Operations vs. the File Pointer
Traditionally, file I/O was sequential. You read (or wrote) from the beginning of the file to the end. While my history of operating systems isn't sufficient to say that it was the first, Unix was (and still is) particularly fond of this model, because it allows for piping (that is, redirecting the output of one program to the input of another, etc.).
Traditional I/O APIs reflect this behavior, in that they feature a file pointer associated with each file. Reads and writes always begin at the current file pointer, and advance the file pointer on completion (assuming the operation succeeded). If you wanted to do random access on a file (that is, read or write nonsequentially in the file), you had to call a seek function. On Windows, these functions are ReadFile, WriteFile, and SetFilePointer; on Unix, there's read, write, and lseek; and in the C standard library, there's fread, fwrite, and fseek. These functions work perfectly for sequential file access, and work sufficiently for random file access from a single thread (remember that DOS, Win16, and Unix were single-threaded operating systems, although Win16 and Unix could run multiple single thread processes simultaneously).
Then came NT and later editions of Unix (actually, it would hardly surprise me if other OS supported this earlier; I just don't know of them), which introduced multithreaded apps. This introduced the possibility that multiple threads could share access to a single file handle (Unix always allowed multiple programs to share access to files; but in this case each process had its own file handle, with its own file pointer, so this wasn't a problem.
This is a good thing, certainly, but it created problems. Since it was not possible to atomically set the file pointer and perform the file operation (and it would probably even require two trips to kernel mode), the entire procedure was fundamentally thread-unsafe. If two threads tried to perform random file access on the same file at the same time, it would be impossible to tell exactly where each operation would take place.
The simplest solution to this problem would be to protect each file with a mutex. By ensuring mutually exclusive access to the file, you ensure that you will always know exactly where the file pointer is. However, by definition it also causes all threads to wait if more than one thread attempts a file operation at the same time. While this might be acceptable when file I/O occupies a very small portion of the thread's time, this is a distinctly sub-optimal solution.
This is where positional operations come in. Positional operations are read/write functions which explicitly specify where the operation is supposed to occur, and do not alter the file pointer. Windows NT was originally created with this ability (in fact, as previously mentioned, all I/O on NT is internally performed asynchronously, which mandates positional operations) - the very same ReadFile and WriteFile, only used in a different way - but I don't know when exactly the POSIX positional file functions were introduced - pread and pwrite. Windows 9x, again bearing more resemblance to Windows 3.1 than to Windows NT, and again the most primitive of the three, does not support the use of positional operations.
The merit of truly simultaneous operations on the same file may not immediately be obvious. If this is a disk, or some other type of secondary storage, the nature of the device dictates that it can only perform one operation at any point in time; so what benefit is the OS being able to accept multiple operation requests on the same file simultaneously? It is because when the OS supports this in the kernel (as opposed to funneled kernels, or kernels that emulate this with per-file mutexes), neat optimizations can be done. For example, if thread A wants to read 10 bytes from offset 0 in a file, and thread B wants to read 10 bytes from offset 10 in the file, the operations can be combined into one physical disk operation (reading 20 bytes from offset 0), and the OS can then copy the data into the two output buffers.
But even if it isn't the case that the operations can be combined, there are still optimizations that can be done. For example, if thread A wants to read 10 bytes from the file at offset 50, and thread B wants to read 10 bytes from the file at offset 150, does it matter which of these reads gets physically performed first? It does, actually, because the hard drive has a "file pointer" of its own - the head location. If the head location is at offset 0 in the file, it will probably (I say probably because in reality things are a lot more complicated than I've described here; this is just a simple illustration) be faster to perform thread A's read first, then thread B's, because the total distance the head will move in this order is 160 bytes (50 + 10 + 90 + 10); if it did the reads in the opposite order, it would have to move the head forward 160 bytes, then back 110 bytes (150 + 10 - 50), and finally forward 10 bytes, totalling 280 bytes - almost twice as far.
Conclusion: positional file I/O is a Good Thing (tm).
Traditional I/O APIs reflect this behavior, in that they feature a file pointer associated with each file. Reads and writes always begin at the current file pointer, and advance the file pointer on completion (assuming the operation succeeded). If you wanted to do random access on a file (that is, read or write nonsequentially in the file), you had to call a seek function. On Windows, these functions are ReadFile, WriteFile, and SetFilePointer; on Unix, there's read, write, and lseek; and in the C standard library, there's fread, fwrite, and fseek. These functions work perfectly for sequential file access, and work sufficiently for random file access from a single thread (remember that DOS, Win16, and Unix were single-threaded operating systems, although Win16 and Unix could run multiple single thread processes simultaneously).
Then came NT and later editions of Unix (actually, it would hardly surprise me if other OS supported this earlier; I just don't know of them), which introduced multithreaded apps. This introduced the possibility that multiple threads could share access to a single file handle (Unix always allowed multiple programs to share access to files; but in this case each process had its own file handle, with its own file pointer, so this wasn't a problem.
This is a good thing, certainly, but it created problems. Since it was not possible to atomically set the file pointer and perform the file operation (and it would probably even require two trips to kernel mode), the entire procedure was fundamentally thread-unsafe. If two threads tried to perform random file access on the same file at the same time, it would be impossible to tell exactly where each operation would take place.
The simplest solution to this problem would be to protect each file with a mutex. By ensuring mutually exclusive access to the file, you ensure that you will always know exactly where the file pointer is. However, by definition it also causes all threads to wait if more than one thread attempts a file operation at the same time. While this might be acceptable when file I/O occupies a very small portion of the thread's time, this is a distinctly sub-optimal solution.
This is where positional operations come in. Positional operations are read/write functions which explicitly specify where the operation is supposed to occur, and do not alter the file pointer. Windows NT was originally created with this ability (in fact, as previously mentioned, all I/O on NT is internally performed asynchronously, which mandates positional operations) - the very same ReadFile and WriteFile, only used in a different way - but I don't know when exactly the POSIX positional file functions were introduced - pread and pwrite. Windows 9x, again bearing more resemblance to Windows 3.1 than to Windows NT, and again the most primitive of the three, does not support the use of positional operations.
The merit of truly simultaneous operations on the same file may not immediately be obvious. If this is a disk, or some other type of secondary storage, the nature of the device dictates that it can only perform one operation at any point in time; so what benefit is the OS being able to accept multiple operation requests on the same file simultaneously? It is because when the OS supports this in the kernel (as opposed to funneled kernels, or kernels that emulate this with per-file mutexes), neat optimizations can be done. For example, if thread A wants to read 10 bytes from offset 0 in a file, and thread B wants to read 10 bytes from offset 10 in the file, the operations can be combined into one physical disk operation (reading 20 bytes from offset 0), and the OS can then copy the data into the two output buffers.
But even if it isn't the case that the operations can be combined, there are still optimizations that can be done. For example, if thread A wants to read 10 bytes from the file at offset 50, and thread B wants to read 10 bytes from the file at offset 150, does it matter which of these reads gets physically performed first? It does, actually, because the hard drive has a "file pointer" of its own - the head location. If the head location is at offset 0 in the file, it will probably (I say probably because in reality things are a lot more complicated than I've described here; this is just a simple illustration) be faster to perform thread A's read first, then thread B's, because the total distance the head will move in this order is 160 bytes (50 + 10 + 90 + 10); if it did the reads in the opposite order, it would have to move the head forward 160 bytes, then back 110 bytes (150 + 10 - 50), and finally forward 10 bytes, totalling 280 bytes - almost twice as far.
Conclusion: positional file I/O is a Good Thing (tm).
Friday, October 28, 2005
R.I.P. Slinky
So, now we're down by two. Last year (like 53 weeks ago) we lost Kaity, and Tuesday we lost Slinky. Slinky, for those not already acquainted with him, was one of our (formerly) three cats: Poguita ('Dorkess'), Ping Pong ('Slinky'), and Kaity ('Squishy Fat').
Slinky and Dorkess, the twins, were born in 1992, and we've had them ever since then. Slinky was given the official name Ping Pong, due to the white spot on his chin. He was later nicknamed Slinky because of his skinniness and the slinky way he walked. In addition to those, he was known for his perpetually gigantic yellow eyes, his long tail that twitched incessantly, and his constant meowing with his Spanish rolled rrs.
He seemed to have some sort of metabolic disorder, as he remained thin and slinky, despite eating enormous amounts of food (more than any of the other cats). However, this got much worse in the last year or so, as his body seemed to progressively deteriorate in the amount of food it absorbed. Ultimately, he starved to death.
So, I'm writing this post for a couple reasons. First, a number of my friends have heard of Slinky, Dorkess, and Kaity a lot, but so far almost all the pictures I've put online have been of Kaity. As well, this post is to be a tribute to the memory of Slinky, as I believe that instead of grieving someone's death, it's better to be happy about their life.

The twins - Poguita on the left, Pong on the right




Rest in peace, Slinky.
Friday, October 21, 2005
Asynchronous I/O - APCs - Windows Implementation
So, I just wrote the Windows version of the APC system (the NT 4+ one). It was, as expected, trivial. The code is very straightforward, although I should mention one thing: I use WaitForSingleObjectEx rather than SleepEx. See, SleepEx(0, TRUE) has an undesirable behavior: if no APCs are executed, even with a timeout of 0 MS, SleepEx WILL sleep; specifically, it will surrender the rest of the thread's time slice. This can conceivably take hundreds of milliseconds, which is NOT what we want DispatchAsyncCalls to be doing.
To work around this, I used WaitForSingleObjectEx, waiting on an object that will never become signaled (at least not before the function returns) - the current thread. Unlike SleepEx, WaitForSingleObjectEx with a timeout of 0 MS will indeed return immediately.
However, there was a significant problem: by definition LibQ can't use any platform-specific definitions in the interface exposed to the user. PAPCFUNC, however, is a Win32 definition: the prototype for the APC function that Windows calls directly. So, we have what appears to be a paradox: we can't make the client use PAPCFUNC, yet we have no choice but to use PAPCFUNC. The solution: a bit of black magic; you know, the kind of thing that makes other programmers call you (or me, as is often the case) a pervert.
Three potential solutions occurred to me. After some time thinking about it, I decided one was significantly better than the alternatives. Specifically, this one (note that the typedef is platform-independent, while the two defines are the Windows versions of platform-independent macros):
This method works by generating proxy functions that conform to the OS APC prototype, while calling the user's APC function using the platform-independent prototype. Of course, all this is handled by two easy to use macros.
So, this was tested, and confirmed to work. But for me, the ultimate acid test of success with anything LibQ-related was efficiency of code generated. So, into release build we go, to look at the assembly generated in calls to these functions. Take a look:
CThread &thread = CThread::GetCurrentThread();
004018A0 mov eax,dword ptr [Q::CThread::s_curThread (40ECC8h)]
004018A5 push eax
004018A6 call dword ptr [__imp__TlsGetValue@4 (40B034h)]
thread.QueueAsyncCall(MAKE_ASYNC_CALL_PROC(AsyncFunc), 0);
004018AC mov ecx,dword ptr [eax+0Ch]
004018AF push 0
004018B1 push ecx
004018B2 push offset APCProxy_AsyncFunc (401860h)
004018B7 call dword ptr [__imp__QueueUserAPC@12 (40B038h)]
CThread::DispatchAsyncCalls(0);
004018BD push 1
004018BF push 0
004018C1 call dword ptr [__imp__GetCurrentThread@0 (40B040h)]
004018C7 push eax
004018C8 call dword ptr [__imp__WaitForSingleObjectEx@12 (40B03Ch)]
Isn't that pretty? The only way you can tell that this wasn't native Win32 API C code is that the program has to resort to thread-local storage to hold a pointer to the CThread, whereas a Win32 program would just call GetCurrentThread; but I'm quite pleased with the results, and this is a prime example of the LibQ philosophy of incurring the absolute minimum possible amount of overhead.
To work around this, I used WaitForSingleObjectEx, waiting on an object that will never become signaled (at least not before the function returns) - the current thread. Unlike SleepEx, WaitForSingleObjectEx with a timeout of 0 MS will indeed return immediately.
inline bool QueueAsyncCall(PAPCFUNC lpCallProc, uword param)
{
assert(lpCallProc);
return (QueueUserAPC(lpCallProc, m_hThread, (ULONG_PTR)param) != 0);
}
// Returns true if APCs were dispatched before the timeout expired, otherwise false
static inline bool DispatchAsyncCalls(unsigned int nTimeoutMS)
{ return (WaitForSingleObjectEx(::GetCurrentThread(), nTimeoutMS, TRUE) == WAIT_IO_COMPLETION); }
// Returns true if APCs were dispatched, false if an error occurred
static inline bool DispatchAsyncCalls()
{ return (WaitForSingleObjectEx(::GetCurrentThread(), INFINITE, TRUE) == WAIT_IO_COMPLETION); }
{
assert(lpCallProc);
return (QueueUserAPC(lpCallProc, m_hThread, (ULONG_PTR)param) != 0);
}
// Returns true if APCs were dispatched before the timeout expired, otherwise false
static inline bool DispatchAsyncCalls(unsigned int nTimeoutMS)
{ return (WaitForSingleObjectEx(::GetCurrentThread(), nTimeoutMS, TRUE) == WAIT_IO_COMPLETION); }
// Returns true if APCs were dispatched, false if an error occurred
static inline bool DispatchAsyncCalls()
{ return (WaitForSingleObjectEx(::GetCurrentThread(), INFINITE, TRUE) == WAIT_IO_COMPLETION); }
However, there was a significant problem: by definition LibQ can't use any platform-specific definitions in the interface exposed to the user. PAPCFUNC, however, is a Win32 definition: the prototype for the APC function that Windows calls directly. So, we have what appears to be a paradox: we can't make the client use PAPCFUNC, yet we have no choice but to use PAPCFUNC. The solution: a bit of black magic; you know, the kind of thing that makes other programmers call you (or me, as is often the case) a pervert.
Three potential solutions occurred to me. After some time thinking about it, I decided one was significantly better than the alternatives. Specifically, this one (note that the typedef is platform-independent, while the two defines are the Windows versions of platform-independent macros):
// Prototype for asynchronous call functions
typedef void (*TAsyncCallPtr)(uword param);
// Windows macros for APC proxy generation and use. Must be used in the same module as the APC is queued.
#define DECLARE_ASYNC_CALL_PROC(function) static VOID CALLBACK APCProxy_##function(ULONG_PTR lpParam) { function ((uword)lpParam); }
#define MAKE_ASYNC_CALL_PROC(function) (PAPCFUNC)APCProxy_##function
typedef void (*TAsyncCallPtr)(uword param);
// Windows macros for APC proxy generation and use. Must be used in the same module as the APC is queued.
#define DECLARE_ASYNC_CALL_PROC(function) static VOID CALLBACK APCProxy_##function(ULONG_PTR lpParam) { function ((uword)lpParam); }
#define MAKE_ASYNC_CALL_PROC(function) (PAPCFUNC)APCProxy_##function
This method works by generating proxy functions that conform to the OS APC prototype, while calling the user's APC function using the platform-independent prototype. Of course, all this is handled by two easy to use macros.
So, this was tested, and confirmed to work. But for me, the ultimate acid test of success with anything LibQ-related was efficiency of code generated. So, into release build we go, to look at the assembly generated in calls to these functions. Take a look:
CThread &thread = CThread::GetCurrentThread();
004018A0 mov eax,dword ptr [Q::CThread::s_curThread (40ECC8h)]
004018A5 push eax
004018A6 call dword ptr [__imp__TlsGetValue@4 (40B034h)]
thread.QueueAsyncCall(MAKE_ASYNC_CALL_PROC(AsyncFunc), 0);
004018AC mov ecx,dword ptr [eax+0Ch]
004018AF push 0
004018B1 push ecx
004018B2 push offset APCProxy_AsyncFunc (401860h)
004018B7 call dword ptr [__imp__QueueUserAPC@12 (40B038h)]
CThread::DispatchAsyncCalls(0);
004018BD push 1
004018BF push 0
004018C1 call dword ptr [__imp__GetCurrentThread@0 (40B040h)]
004018C7 push eax
004018C8 call dword ptr [__imp__WaitForSingleObjectEx@12 (40B03Ch)]
Isn't that pretty? The only way you can tell that this wasn't native Win32 API C code is that the program has to resort to thread-local storage to hold a pointer to the CThread, whereas a Win32 program would just call GetCurrentThread; but I'm quite pleased with the results, and this is a prime example of the LibQ philosophy of incurring the absolute minimum possible amount of overhead.
Asynchronous I/O - APCs - Updated
So, supporting asynchronous I/O uniformly on a variety of platforms while making full use of OS specific features provides us (or me, at least) with a challenge. However, with a bit of clever object-oriented magic, the challenge is significantly reduced.
Apart from the classes I've already mentioned, two other classes form the core of LibQ's asynchronous I/O system. While I could have (and was originally planning on) making the features applicable to the asynchronous I/O system for internal use only, I ultimately decided they would be useful enough for public use that I'd put some extra care into them and make them part of the public API.
The first of these important features is asynchronous procedure calls (APCs). APCs can be queued to any thread via CThread::QueueAsyncCall, and will be held until the thread calls CThread::DispatchAsyncCalls to dispatch them; at that point, each queued APC function for that thread will be called, before the function returns.
Win32 (both Windows NT and 9x) supports this mechanism natively. APCs are queued to the specified thread with the QueueUserAPC function, and dispatched at any indeterminate point while the thread is in an alertable wait state. An alertable wait state is when the thread is suspended (i.e. sleeping or waiting on an object) but is flagged as alertable (this can only be specified in SleepEx, WaitForSingleObjectEx, and WaitForMultipleObjectsEx). All of those functions will sleep until one of three things happens: the object being waited on becomes signaled (not applicable to SleepEx), the timeout expires, or APCs are executed. CThread uses Win32 APCs on Windows.
Unfortunately, we do not have the luxury of the same decadence in a uniform cross-platform library. POSIX does not natively support APCs (at least not in a form that resembles the Win32 method); the closest thing to Win32 APCs that POSIX supports is message queues, which I chose not to use for the reason that there is no qualitative benefit (and a performance penalty) for using kernel-mode message queues over a user-mode implementation.
The POSIX implementation consists simply of a linked list (a queue) protected by a mutex, and a condition, for each thread. This allows us to approximate the Win32 APC by allowing waits - either timed or indefinite - for APCs. However, it still won't be possible to process APCs while waiting on a synchronization object (although you can simulate this by queuing APCs that do some particular task that would otherwise have been executed when a synchronization object became signaled).
UPDATE: I've just heard some very grave (and unexpected) news. NT pre-4.0 does NOT support QueueUserAPC. This puts a rather sizeable hurdle in the way of this thing, as it leaves two options.
First, I could drop support for NT before 4.0. While I wouldn't hesitate to drop support for NT 3.1 (back from 1993), NT 3.5 was around until 1996 or 1997, making it not THAT old. Of course, it could be argued that new programs will require the Explorer interface that wasn't introduced until NT 4 (it was first released in Windows 95, which preceded NT 4). While it's safe to assume that no new GUI program would use the Windows 3.1 GUI (which NT 3.1 and 3.5 had), this isn't the case for programs (or libraries) that don't have a GUI.
The other alternative is to create a hybrid list/APC system. NT has always supported APCs for asynchronous I/O notification; however, it wasn't until 4.0 that you could send your own APCs. In order to pull this off, I'd have to implement a hybrid condition variable-type-thingy that waits on the condition in an alertable state (and perhaps even throw a timeout in there for good measure). This would be messy, to say the least, and it could take 2 kernel mode transitions just to be sure all bases are covered (if WaitForSingleObjectEx returns WAIT_OBJECT_0 you can't be sure that there weren't APCs that didn't get executed, and if it returns WAIT_IO_COMPLETION you can't be sure that the object wasn't signaled), making it slower.
I'm leaning towards requiring NT 4.
Apart from the classes I've already mentioned, two other classes form the core of LibQ's asynchronous I/O system. While I could have (and was originally planning on) making the features applicable to the asynchronous I/O system for internal use only, I ultimately decided they would be useful enough for public use that I'd put some extra care into them and make them part of the public API.
The first of these important features is asynchronous procedure calls (APCs). APCs can be queued to any thread via CThread::QueueAsyncCall, and will be held until the thread calls CThread::DispatchAsyncCalls to dispatch them; at that point, each queued APC function for that thread will be called, before the function returns.
Win32 (both Windows NT and 9x) supports this mechanism natively. APCs are queued to the specified thread with the QueueUserAPC function, and dispatched at any indeterminate point while the thread is in an alertable wait state. An alertable wait state is when the thread is suspended (i.e. sleeping or waiting on an object) but is flagged as alertable (this can only be specified in SleepEx, WaitForSingleObjectEx, and WaitForMultipleObjectsEx). All of those functions will sleep until one of three things happens: the object being waited on becomes signaled (not applicable to SleepEx), the timeout expires, or APCs are executed. CThread uses Win32 APCs on Windows.
Unfortunately, we do not have the luxury of the same decadence in a uniform cross-platform library. POSIX does not natively support APCs (at least not in a form that resembles the Win32 method); the closest thing to Win32 APCs that POSIX supports is message queues, which I chose not to use for the reason that there is no qualitative benefit (and a performance penalty) for using kernel-mode message queues over a user-mode implementation.
The POSIX implementation consists simply of a linked list (a queue) protected by a mutex, and a condition, for each thread. This allows us to approximate the Win32 APC by allowing waits - either timed or indefinite - for APCs. However, it still won't be possible to process APCs while waiting on a synchronization object (although you can simulate this by queuing APCs that do some particular task that would otherwise have been executed when a synchronization object became signaled).
UPDATE: I've just heard some very grave (and unexpected) news. NT pre-4.0 does NOT support QueueUserAPC. This puts a rather sizeable hurdle in the way of this thing, as it leaves two options.
First, I could drop support for NT before 4.0. While I wouldn't hesitate to drop support for NT 3.1 (back from 1993), NT 3.5 was around until 1996 or 1997, making it not THAT old. Of course, it could be argued that new programs will require the Explorer interface that wasn't introduced until NT 4 (it was first released in Windows 95, which preceded NT 4). While it's safe to assume that no new GUI program would use the Windows 3.1 GUI (which NT 3.1 and 3.5 had), this isn't the case for programs (or libraries) that don't have a GUI.
The other alternative is to create a hybrid list/APC system. NT has always supported APCs for asynchronous I/O notification; however, it wasn't until 4.0 that you could send your own APCs. In order to pull this off, I'd have to implement a hybrid condition variable-type-thingy that waits on the condition in an alertable state (and perhaps even throw a timeout in there for good measure). This would be messy, to say the least, and it could take 2 kernel mode transitions just to be sure all bases are covered (if WaitForSingleObjectEx returns WAIT_OBJECT_0 you can't be sure that there weren't APCs that didn't get executed, and if it returns WAIT_IO_COMPLETION you can't be sure that the object wasn't signaled), making it slower.
I'm leaning towards requiring NT 4.
Thursday, October 20, 2005
Watch Where You Poke
So, today I had an interesting (and awkward) experience. If you've ever seen me play air hockey, you know I'm pretty good, despite the fact that I play maybe once a year. I think one of the main reasons for that is that I'm pretty good with my peripheral vision. This shows up in my daily life, as I'll often not look directly at what I'm "looking at" unless there's a particular reason to do so (i.e. being able to see it very clearly).
Well, this can be taken too far, it appears. So, my social psychology class just ended (my last class for the day, and I wanted to get out of there as much as everyone else did), and I was picking up my backpack to go (I was sitting in the front row). So, I pick up the backpack, sling it over my right shoulder, and insert left arm through the strap. In my usual manner, I was spotting the location of the strap with my peripheral vision - I only needed to see the location of the strap, I didn't need to focus on it.
So, insert the left arm and... *squish* Uh oh, that can't be a good thing. Now aware that there was somebody much closer to me than I was aware of (less than 18 inches), I looked to see who this was. Given the 50:50 chance, it was only a surprise in these particular circumstances that it was a girl. That's right, I'd just felt some girl up. Fortunately, she either comprehended exactly what had happened, or was too polite to say anything while I quickly apologized and slinked out of the building.
So, the moral of the story: watch where you're sticking your hands when there are other people present.
Well, this can be taken too far, it appears. So, my social psychology class just ended (my last class for the day, and I wanted to get out of there as much as everyone else did), and I was picking up my backpack to go (I was sitting in the front row). So, I pick up the backpack, sling it over my right shoulder, and insert left arm through the strap. In my usual manner, I was spotting the location of the strap with my peripheral vision - I only needed to see the location of the strap, I didn't need to focus on it.
So, insert the left arm and... *squish* Uh oh, that can't be a good thing. Now aware that there was somebody much closer to me than I was aware of (less than 18 inches), I looked to see who this was. Given the 50:50 chance, it was only a surprise in these particular circumstances that it was a girl. That's right, I'd just felt some girl up. Fortunately, she either comprehended exactly what had happened, or was too polite to say anything while I quickly apologized and slinked out of the building.
So, the moral of the story: watch where you're sticking your hands when there are other people present.
Friday, October 14, 2005
Asynchronous I/O - The LibQ Way
Okay, so now that I've talked about the challenges in asynchronous I/O, let me explain my solution (the interface, at least; will discuss the implementation later). First of all let me state that this is the working draft of the interface; function names in particular are not final, and the interface may change somewhat.
LibQ supports asynchronous I/O on all OS, and supports all three notifications methods: event notification, completion callbacks, and completion ports.
CAsyncStatus
The object-oriented state of an asynchronous I/O operation. May be either unused, pending, or completed. When completed, contains the information such as the success/failure status of the operation and the number of bytes transferred, as well as the original information about the I/O offset, file, etc. Allocated and freed by the caller, and may be inherited to add caller-owned data associated with the operation.
CCompletionPort
An I/O completion port. Can be associated with one or more files that it should receive completion notifications for. Can be used to retrieve a queued completion (in the form of a CAsyncStatus) or waited on until the next notification is queued (if none are already queued).
CAsyncFile
The class for a file opened for asynchronous I/O. Synchronous I/O is done using Read and Write; asynchronous I/O is done using RequestRead and RequestWrite, both taking a CAsyncStatus for the operation, as well as a CEvent to set or a callback function to call on completion (if neither is specified, the completion notification will be queued on the file's CCompletionPort). The CAsyncStatus must remain valid until the operation is complete.
Completion callbacks are queued to the thread that called RequestRead/RequestWrite, and are not actually called until DispatchNotifications is called from that thread, when all queued notification callbacks are called for that thread.
Uncompleted I/O requests can be cancelled for a file in all threads by calling CAsyncFile::CancelAllIo for that file.
LibQ supports asynchronous I/O on all OS, and supports all three notifications methods: event notification, completion callbacks, and completion ports.
CAsyncStatus
The object-oriented state of an asynchronous I/O operation. May be either unused, pending, or completed. When completed, contains the information such as the success/failure status of the operation and the number of bytes transferred, as well as the original information about the I/O offset, file, etc. Allocated and freed by the caller, and may be inherited to add caller-owned data associated with the operation.
CCompletionPort
An I/O completion port. Can be associated with one or more files that it should receive completion notifications for. Can be used to retrieve a queued completion (in the form of a CAsyncStatus) or waited on until the next notification is queued (if none are already queued).
CAsyncFile
The class for a file opened for asynchronous I/O. Synchronous I/O is done using Read and Write; asynchronous I/O is done using RequestRead and RequestWrite, both taking a CAsyncStatus for the operation, as well as a CEvent to set or a callback function to call on completion (if neither is specified, the completion notification will be queued on the file's CCompletionPort). The CAsyncStatus must remain valid until the operation is complete.
Completion callbacks are queued to the thread that called RequestRead/RequestWrite, and are not actually called until DispatchNotifications is called from that thread, when all queued notification callbacks are called for that thread.
Uncompleted I/O requests can be cancelled for a file in all threads by calling CAsyncFile::CancelAllIo for that file.
Thursday, October 13, 2005
Very Clever
So, I was writing a little helper class to use in later projects. It's a chain link class to be used in the construction of circular linked lists. So, I wanted to see what the optimized assembly VC++ would generate would look like. The class and the test function are shown below:
Well, VC++ really pulled a fast one on me. In the end, I didn't learn what I was looking for, but I did see VC++ do some clever optimization. Have a look at the assembly it generated:
CChainLink A, B, C, D, E;
A.SpliceNext(B);
00401868 8D 4C 24 24 lea ecx,[esp+24h]
0040186C 89 4C 24 20 mov dword ptr [esp+20h],ecx
B.SpliceNext(C);
00401870 8D 54 24 14 lea edx,[esp+14h]
00401874 89 54 24 1C mov dword ptr [esp+1Ch],edx
00401878 8D 44 24 1C lea eax,[esp+1Ch]
D.SpliceNext(E);
0040187C 8D 4C 24 04 lea ecx,[esp+4]
00401880 8D 54 24 0C lea edx,[esp+0Ch]
00401884 89 4C 24 0C mov dword ptr [esp+0Ch],ecx
C.SpliceNext(D);
00401888 8B CA mov ecx,edx
0040188A 89 44 24 24 mov dword ptr [esp+24h],eax
0040188E 89 44 24 18 mov dword ptr [esp+18h],eax
00401892 8D 44 24 24 lea eax,[esp+24h]
00401896 89 4C 24 14 mov dword ptr [esp+14h],ecx
0040189A 89 54 24 08 mov dword ptr [esp+8],edx
0040189E 89 44 24 04 mov dword ptr [esp+4],eax
SLIST_HEADER asdfgh;
SLIST_ENTRY lkjhg;
InitializeSListHead(&asdfgh);
004018A2 8D 4C 24 2C lea ecx,[esp+2Ch]
004018A6 8D 54 24 04 lea edx,[esp+4]
004018AA 8D 44 24 14 lea eax,[esp+14h]
004018AE 51 push ecx
004018AF C7 44 24 40 04 00 00 00 mov dword ptr [esp+40h],4
004018B7 89 54 24 2C mov dword ptr [esp+2Ch],edx
004018BB 89 44 24 14 mov dword ptr [esp+14h],eax
004018BF FF 15 38 B0 40 00 call dword ptr [__imp__InitializeSListHead@4 (40B038h)]
class CChainLink
{
protected:
CChainLink *m_pNext;
CChainLink *m_pPrev;
// Swap pointers to links
inline static void SwapLinks(CChainLink **ppFirst, CChainLink **ppSecond)
{
assert(ppFirst);
assert(*ppFirst);
assert(ppSecond);
assert(*ppSecond);
CChainLink *pTemp = *ppFirst;
*ppFirst = *ppSecond;
*ppSecond = pTemp;
}
public:
inline CChainLink()
{
m_pNext = m_pPrev = this;
}
inline ~CChainLink()
{
SpliceOut();
}
// Removes self from the chain
inline void SpliceOut()
{
CChainLink &prev = *m_pPrev, &next = *m_pNext;
SwapLinks(&prev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &m_pPrev);
}
// Inserts the chain beginning with link between the current link and the next link
inline void SpliceNext(CChainLink &link)
{
assert(&link != this);
CChainLink &linkPrev = *link.m_pPrev, &next = *m_pNext;
SwapLinks(&linkPrev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &link.m_pPrev);
}
// Inserts the chain beginning with link between the previous link and the current link
inline void SplicePrev(CChainLink &link)
{
m_pPrev->SpliceNext(link);
}
// Replaces self with the chain beginning with link
inline void SpliceOver(CChainLink &link)
{
assert(&link != this);
SpliceNext(link);
SpliceOut();
}
};
int main(int argc, char* argv[])
{
CChainLink A, B, C, D, E;
A.SpliceNext(B);
B.SpliceNext(C);
D.SpliceNext(E);
C.SpliceNext(D);
// There's actually more test code down here, but I've omitted it since it has nothing to do with the chain class
}
{
protected:
CChainLink *m_pNext;
CChainLink *m_pPrev;
// Swap pointers to links
inline static void SwapLinks(CChainLink **ppFirst, CChainLink **ppSecond)
{
assert(ppFirst);
assert(*ppFirst);
assert(ppSecond);
assert(*ppSecond);
CChainLink *pTemp = *ppFirst;
*ppFirst = *ppSecond;
*ppSecond = pTemp;
}
public:
inline CChainLink()
{
m_pNext = m_pPrev = this;
}
inline ~CChainLink()
{
SpliceOut();
}
// Removes self from the chain
inline void SpliceOut()
{
CChainLink &prev = *m_pPrev, &next = *m_pNext;
SwapLinks(&prev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &m_pPrev);
}
// Inserts the chain beginning with link between the current link and the next link
inline void SpliceNext(CChainLink &link)
{
assert(&link != this);
CChainLink &linkPrev = *link.m_pPrev, &next = *m_pNext;
SwapLinks(&linkPrev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &link.m_pPrev);
}
// Inserts the chain beginning with link between the previous link and the current link
inline void SplicePrev(CChainLink &link)
{
m_pPrev->SpliceNext(link);
}
// Replaces self with the chain beginning with link
inline void SpliceOver(CChainLink &link)
{
assert(&link != this);
SpliceNext(link);
SpliceOut();
}
};
int main(int argc, char* argv[])
{
CChainLink A, B, C, D, E;
A.SpliceNext(B);
B.SpliceNext(C);
D.SpliceNext(E);
C.SpliceNext(D);
// There's actually more test code down here, but I've omitted it since it has nothing to do with the chain class
}
Well, VC++ really pulled a fast one on me. In the end, I didn't learn what I was looking for, but I did see VC++ do some clever optimization. Have a look at the assembly it generated:
CChainLink A, B, C, D, E;
A.SpliceNext(B);
00401868 8D 4C 24 24 lea ecx,[esp+24h]
0040186C 89 4C 24 20 mov dword ptr [esp+20h],ecx
B.SpliceNext(C);
00401870 8D 54 24 14 lea edx,[esp+14h]
00401874 89 54 24 1C mov dword ptr [esp+1Ch],edx
00401878 8D 44 24 1C lea eax,[esp+1Ch]
D.SpliceNext(E);
0040187C 8D 4C 24 04 lea ecx,[esp+4]
00401880 8D 54 24 0C lea edx,[esp+0Ch]
00401884 89 4C 24 0C mov dword ptr [esp+0Ch],ecx
C.SpliceNext(D);
00401888 8B CA mov ecx,edx
0040188A 89 44 24 24 mov dword ptr [esp+24h],eax
0040188E 89 44 24 18 mov dword ptr [esp+18h],eax
00401892 8D 44 24 24 lea eax,[esp+24h]
00401896 89 4C 24 14 mov dword ptr [esp+14h],ecx
0040189A 89 54 24 08 mov dword ptr [esp+8],edx
0040189E 89 44 24 04 mov dword ptr [esp+4],eax
SLIST_HEADER asdfgh;
SLIST_ENTRY lkjhg;
InitializeSListHead(&asdfgh);
004018A2 8D 4C 24 2C lea ecx,[esp+2Ch]
004018A6 8D 54 24 04 lea edx,[esp+4]
004018AA 8D 44 24 14 lea eax,[esp+14h]
004018AE 51 push ecx
004018AF C7 44 24 40 04 00 00 00 mov dword ptr [esp+40h],4
004018B7 89 54 24 2C mov dword ptr [esp+2Ch],edx
004018BB 89 44 24 14 mov dword ptr [esp+14h],eax
004018BF FF 15 38 B0 40 00 call dword ptr [__imp__InitializeSListHead@4 (40B038h)]
Asynchronous I/O - Taking Inventory
At some point in the distant past, I discussed the three basic methods of asynchronous I/O completion notification: events, callback functions, and notification ports. Now I want to talk about the difficulties in implementing a single cross-platform asynchronous I/O API; phrased differently, I want to explain what OS implement what.
To me, there are four major OS - Windows NT, Windows 9x, Linux, and OS X - separated into three platforms (as far as LibQ is concerned) - Windows NT, Windows 9x, and POSIX. While 9x is getting up there in age, I'm still not comfortable dropping support for it yet.
To varying extents, Windows (both NT and 9x) supports asynchronous I/O and both event and callback-based notifications. Callbacks are handled in somewhat of a novel way: when the I/O operation completes or fails, a callback notification is queued for that operation as a user-mode asynchronous procedure call (APC) to the thread that started the operation. When the thread goes into an alertable waitstate (that is, using WaitForSingleObjectEx and kin) the APCs for that thread are executed, and the callback is called. This has some interesting (and actually pretty nice) properties. First, it ensures that callbacks will only be called when the program wants them to be called. It also has the advantage that the callbacks will always be called from the thread that initiated the I/O; in the best cases, this means that no cross-thread data protection must be done. Furthermore, calls to cancel pending I/O affect I/O operations issued by that thread, only.
Windows 9x is possibly the most primitive of the three platforms - it's something of a cross between Windows 3.1 (16-bit Windows) and NT (32-bit Windows). Although it supports both event and callback-based notifications, 9x supports asynchronous I/O only on sockets (and a couple other minor items you're not likely to ever use).
Windows NT is the true 32-bit Windows. It's a completely new code-base to go with a new archetecture (although Microsoft attempted to make it as backward compatible as possible). In the NT kernel, all I/O is asynchronous, and synchronous I/O is nothing more than suspending threads while their I/O gets processed. NT is the only platform that supports all three modes of asynchronous notifications (although the very first version of NT - 3.1 - did not support notification ports).
POSIX is quite another beast altogether. To begin with, unlike Windows NT and 9x, POSIX is a vague standard, rather than an actual platform. Furthermore, asynchronous I/O is considered an option in POSIX, which does not need to be supported by any POSIX-compliant OS; this fact is illustrated in many places. Linux did not support asynchronous I/O in the kernel until version 2.6 (the current version; it was actually added in 2.5, but that was an unstable developer version); OS X did not support the POSIX asynchronous I/O functions until version 10.4 (the current version). And even those platforms that do support the POSIX functions remain limited by the standard itself; of our three methods of completion notification, POSIX only supports callback functions. As well, what features it does provide are wholly incompatible with the Windows feature set. There is no guarantee when or in what thread completion callbacks will arrive. Even more problematic is that POSIX provides no way to cancel pending I/O for a single thread; only a method to cancel all I/O for a file.
So, all in all, it's a huge mess. This is perhaps the area of LibQ that I'm most excited about, and put the most thought into (and I haven't even started to code it, yet). Some of the solutions I've come up with are very elegant, and I take pride in them; others are simply the best of the possible bad options, and I'd rather forget that I have to go with them.
To me, there are four major OS - Windows NT, Windows 9x, Linux, and OS X - separated into three platforms (as far as LibQ is concerned) - Windows NT, Windows 9x, and POSIX. While 9x is getting up there in age, I'm still not comfortable dropping support for it yet.
To varying extents, Windows (both NT and 9x) supports asynchronous I/O and both event and callback-based notifications. Callbacks are handled in somewhat of a novel way: when the I/O operation completes or fails, a callback notification is queued for that operation as a user-mode asynchronous procedure call (APC) to the thread that started the operation. When the thread goes into an alertable waitstate (that is, using WaitForSingleObjectEx and kin) the APCs for that thread are executed, and the callback is called. This has some interesting (and actually pretty nice) properties. First, it ensures that callbacks will only be called when the program wants them to be called. It also has the advantage that the callbacks will always be called from the thread that initiated the I/O; in the best cases, this means that no cross-thread data protection must be done. Furthermore, calls to cancel pending I/O affect I/O operations issued by that thread, only.
Windows 9x is possibly the most primitive of the three platforms - it's something of a cross between Windows 3.1 (16-bit Windows) and NT (32-bit Windows). Although it supports both event and callback-based notifications, 9x supports asynchronous I/O only on sockets (and a couple other minor items you're not likely to ever use).
Windows NT is the true 32-bit Windows. It's a completely new code-base to go with a new archetecture (although Microsoft attempted to make it as backward compatible as possible). In the NT kernel, all I/O is asynchronous, and synchronous I/O is nothing more than suspending threads while their I/O gets processed. NT is the only platform that supports all three modes of asynchronous notifications (although the very first version of NT - 3.1 - did not support notification ports).
POSIX is quite another beast altogether. To begin with, unlike Windows NT and 9x, POSIX is a vague standard, rather than an actual platform. Furthermore, asynchronous I/O is considered an option in POSIX, which does not need to be supported by any POSIX-compliant OS; this fact is illustrated in many places. Linux did not support asynchronous I/O in the kernel until version 2.6 (the current version; it was actually added in 2.5, but that was an unstable developer version); OS X did not support the POSIX asynchronous I/O functions until version 10.4 (the current version). And even those platforms that do support the POSIX functions remain limited by the standard itself; of our three methods of completion notification, POSIX only supports callback functions. As well, what features it does provide are wholly incompatible with the Windows feature set. There is no guarantee when or in what thread completion callbacks will arrive. Even more problematic is that POSIX provides no way to cancel pending I/O for a single thread; only a method to cancel all I/O for a file.
So, all in all, it's a huge mess. This is perhaps the area of LibQ that I'm most excited about, and put the most thought into (and I haven't even started to code it, yet). Some of the solutions I've come up with are very elegant, and I take pride in them; others are simply the best of the possible bad options, and I'd rather forget that I have to go with them.
Wednesday, October 12, 2005
& Too Much Stuff
So many things to work on, so little time. Just to name a few:
- experiment more with Java, C#, and JavaScript
- make many posts about my CPU archetecture
- get back to posting about reader-writer locks
- post about things I learned about the first amendment this semester in world history
- get up to date with the progress on the room we're building here over the last 4 or 5 weeks
- post a series about endians and endian conversion functions
- get back to working on LibQ (I'd particularly like to work on the I/O portion, especially the asynchronous I/O classes)
- finish the paper for social psychology due tomorrow
- study for my history test tomorrow
But I suspect I'll just play WoW instead :P
Incidentally, an old friend of mine that I haven't talked to in quite a while (he's a console programmer) is working on some interesting programming projects (the kind of thing I might do). One of the projects is a converter that takes an XML data file and schema and compiles it to a memory image file that can be loaded directly into memory without parsing (although some pointer fixups may be needed). This is kinda like what Diablo II does, using data files compiled from SYLK spreadsheets, although more general.
- experiment more with Java, C#, and JavaScript
- make many posts about my CPU archetecture
- get back to posting about reader-writer locks
- post about things I learned about the first amendment this semester in world history
- get up to date with the progress on the room we're building here over the last 4 or 5 weeks
- post a series about endians and endian conversion functions
- get back to working on LibQ (I'd particularly like to work on the I/O portion, especially the asynchronous I/O classes)
- finish the paper for social psychology due tomorrow
- study for my history test tomorrow
But I suspect I'll just play WoW instead :P
Incidentally, an old friend of mine that I haven't talked to in quite a while (he's a console programmer) is working on some interesting programming projects (the kind of thing I might do). One of the projects is a converter that takes an XML data file and schema and compiles it to a memory image file that can be loaded directly into memory without parsing (although some pointer fixups may be needed). This is kinda like what Diablo II does, using data files compiled from SYLK spreadsheets, although more general.
Tuesday, October 11, 2005
& The Tides of Darkness
So, yesterday was Monday. And for me that often means it's time to find a new music CD to stick in my car (I usually change the CD every week or two). The flavor of the week is Warcraft II. As I have at least 50 soundtracks to choose from, it takes a couple years for me to stick in the same CD twice; this is one of those times. Well, the same thing happened as the last time I put it in: I was awe-struck by how awesome the music is, and why it remains on my list of favorite soundtracks. It was composed by Glenn Stafford, who also did some music on Starcraft, Warcraft III, and Diablo II; however, the Warcraft II music remains his best work.
Here are a couple tracks ripped from the CD (although only 128 kbps MP3):
Human Track 3
Orc Track 2
The legendary Title Theme
Unfortunately, acquiring this music (legally) is rather difficult. The original Warcraft II: Tides of Darkness and Beyond the Dark Portal (the expansion, which contains 3 tracks the original does not) contain the music in beautiful CD audio (what I play in my car) quality; these DOS versions, however, are almost a decade old, and no longer for sale. Warcraft II: Battle.Net Edition (the updated Windows version), contains the music in butchered, 22 khz, lossy ADPCM (and low quality, at that), which would only be acceptable if you're not a big fan of music, and if there was absolutely no other choice.
In other news, my latest shipment of manga arrived today: Yotsuba &! 3, Trigun Maximum 3 and 4, Ai Yori Aoshi 9, the Madlax OST 1 (2 won't be out in the US till next month), Batman Begins OST, and Harry Potter and the Prisoner of Azkaban OST (both of the last two are movies I've never seen or heard the music to, but they're by composers I like, and rated well).
Also, while I was writing this post up, this amusing exchange occurred in WoW (you'll have to click on the images to bring them to full size):
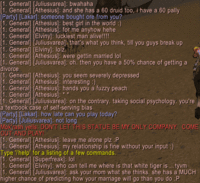
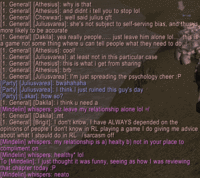
Here are a couple tracks ripped from the CD (although only 128 kbps MP3):
Human Track 3
Orc Track 2
The legendary Title Theme
Unfortunately, acquiring this music (legally) is rather difficult. The original Warcraft II: Tides of Darkness and Beyond the Dark Portal (the expansion, which contains 3 tracks the original does not) contain the music in beautiful CD audio (what I play in my car) quality; these DOS versions, however, are almost a decade old, and no longer for sale. Warcraft II: Battle.Net Edition (the updated Windows version), contains the music in butchered, 22 khz, lossy ADPCM (and low quality, at that), which would only be acceptable if you're not a big fan of music, and if there was absolutely no other choice.
In other news, my latest shipment of manga arrived today: Yotsuba &! 3, Trigun Maximum 3 and 4, Ai Yori Aoshi 9, the Madlax OST 1 (2 won't be out in the US till next month), Batman Begins OST, and Harry Potter and the Prisoner of Azkaban OST (both of the last two are movies I've never seen or heard the music to, but they're by composers I like, and rated well).
Also, while I was writing this post up, this amusing exchange occurred in WoW (you'll have to click on the images to bring them to full size):

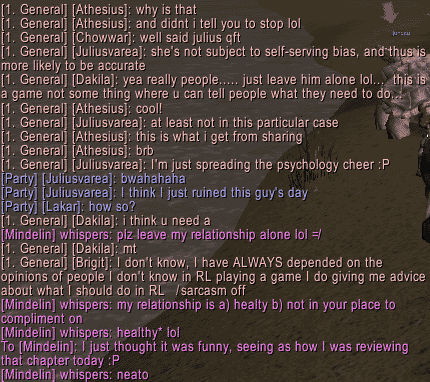
Monday, October 10, 2005
One Language to Rule Them All - Java
For a long time I'd been hoping to add a scripting language to LibQ, to use in any of my (or other people's) projects that needed a scripting language. The ideal scripting language would be well known, portable (that is, the interpreter code should be portable), flexible, and easy to interface with. However, just in the last couple days, I've come up with arguably my most insane idea ever for a programming project. While I don't think I'll discuss the idea here, let's say that one of the staples of this project would be LARGE scripts, making speed a requirement as well.
Given all these criteria, two languages jumped to mind: Java and C#. Both of these languages are well known (although Java significantly more than C#), flexible, portable (again Java more than C#), and fairly easy to interface with (C# more than Java, actually). You'll also notice that these are less than conventional choices for scripting languages... that is, they're NOT scripting languages, but rather compiled languages. This was how I thought would be the best way to meet the speed requirement, as they'll run circles around interpreted languages (probably at least 10x as fast).
So, first we examine Java. Java is perhaps the most well known programming language today (possibly second to C/C++), and Sun makes a virtual machine for all major OSs, as well as the minor OSs. Benchmarks I did a year or two ago showed that Java executed equivalent computational code at about half the speed of native code (that is, it took twice as long to execute). What I really didn't know is how easy it was to interface with. So, I looked up the Java Native Interface on Sun's Java site, and started playing. It turns out that it's quite easy to host a Java virtual machine and interact with it.
Benchmarks showed that it took about 450 cycles to call a native function from Java code, and about 3100 cycles to call a Java function from native code. 450 cycles isn't bad, but 3100 cycles is a bit slow (at least for said programming project). Also, there doesn't appear to be a programmatic interface to the Java compiler (Java code is compiled in two steps; first the source code is compiled to Java "machine language", and this code is what Java programs are usually distributed as; then, at run time, the Java machine language is compiled to true machine language for the machine the program is executed on). This might be okay for some things (i.e. game scripts, where the scripts could be distributed in compiled form), but it's not a good thing for simple scripts (i.e. batch files).
UPDATE: I could have sworn I fixed that "Java makes a virtual machine" mistake this morning, when I was proof-reading it...
Given all these criteria, two languages jumped to mind: Java and C#. Both of these languages are well known (although Java significantly more than C#), flexible, portable (again Java more than C#), and fairly easy to interface with (C# more than Java, actually). You'll also notice that these are less than conventional choices for scripting languages... that is, they're NOT scripting languages, but rather compiled languages. This was how I thought would be the best way to meet the speed requirement, as they'll run circles around interpreted languages (probably at least 10x as fast).
So, first we examine Java. Java is perhaps the most well known programming language today (possibly second to C/C++), and Sun makes a virtual machine for all major OSs, as well as the minor OSs. Benchmarks I did a year or two ago showed that Java executed equivalent computational code at about half the speed of native code (that is, it took twice as long to execute). What I really didn't know is how easy it was to interface with. So, I looked up the Java Native Interface on Sun's Java site, and started playing. It turns out that it's quite easy to host a Java virtual machine and interact with it.
Benchmarks showed that it took about 450 cycles to call a native function from Java code, and about 3100 cycles to call a Java function from native code. 450 cycles isn't bad, but 3100 cycles is a bit slow (at least for said programming project). Also, there doesn't appear to be a programmatic interface to the Java compiler (Java code is compiled in two steps; first the source code is compiled to Java "machine language", and this code is what Java programs are usually distributed as; then, at run time, the Java machine language is compiled to true machine language for the machine the program is executed on). This might be okay for some things (i.e. game scripts, where the scripts could be distributed in compiled form), but it's not a good thing for simple scripts (i.e. batch files).
UPDATE: I could have sworn I fixed that "Java makes a virtual machine" mistake this morning, when I was proof-reading it...
Subscribe to:
Comments (Atom)

