So, for the last two posts in this series, I've got a couple languages unlike the ones already discussed (at least with respect to case). This post's topic is Finnish, a language different in that it relies much less on prepositions than any of the languages mentioned so far. This is possible due to a large number of cases that fill the role that would otherwise be filled using prepositions.
Finnish declines its nouns, pronouns and adjectives, and a number of disputed cases exist, where it is debatable whether they are actual cases, or merely forms of creating adverbs from adjectives or nouns.
The definitive cases in Finnish are *takes a deep breath*: nominative, genitive, accusative, partitive, inessive, elative, illative, adessive, ablative, allative, essive, translative, translative, abessive, and comitative.
The accusative case is slightly different in meaning than the accusative of the other languages we have examined. In Finnish, the accusative case refers to the direct object, where the entirety of the direct object is involved in the action. This is in contrast to the partitive case, which refers either to a portion of a single object, to a number of objects which are a portion of a greater number of objects, or to an incomplete action.
The inessive case of an object (or even a point in time) refers to something else being contained inside that object (think of "in"; or "at" or "on", with respect to a point in time). Similarly but distinctly, the adessive case refers to existence near some object, such as "on", "near", or "around".
The elative case implies movement out of an object or a point in time (think of "out of", "from", or "since"). The illative indicates just the opposite: movement into an object or a point in time (such as "into" or "until").
Similarly, the ablative case conveys movement off the surface of an object, such as "off of" or "from". The allative is the opposite, indicating movement onto an object, such as "onto", "to", and "for". Both may be used to also indicate a change in possession.
The essive case seems to indicate a temporary state, or partition of time in which some action occurs (think "as", "when", "on", "in", etc.); looking at some examples of the essive case, it is not wholly clear to me how this differs from some of the other cases. The translative case indicates a change in state, property, or composition, corresponding to "into" or "to". The abessive case seems to be dying out in the language, and indicates the lack of something (essentially "without"). Finally, the instructive case indicates a means of action, such as "with", "by", or "using".
15 in all. Man, that's way too many cases. I'm tired out just from writing about them :P Note also that I've tried to give a description of the cases in an intuitive manner, reducing each to a single concept, perhaps applied in different ways. But some cases also have uses that aren't intuitive (at least not to me).
Saturday, June 24, 2006
& Linguistcs - Case - Finnish
Friday, June 23, 2006
& Linguistics - Case - Spanish/Portuguese
Last post we looked at the decline of the English language (pun intended, I'm afraid); this post we'll look at the decline of the Latin language. What exactly do I mean by 'decline'? Well, exactly what I mentioned at the end of the last post: the simplification of grammar in languages over time.
Now, Latin is a dead language, but its derivatives live on. The flavor of the day: Portuguese and Spanish. Very much like English, Spanish and Portuguese have almost entirely given up the system of declension. Adjectives have completely lost the system of declension (although, unlike English, adjectives are still inflected based on gender and number of the noun they modify), as have nouns (an even more radical decline than English, which retains two distinct cases for nouns).
Spanish and Portuguese pronouns come in six cases: nominative (e.g. yo/eu), genitive (e.g. mi/meu), accusative (e.g. me/me), dative (e.g. me/me), ablative (e.g. mí/mim), and comitative (e.g. migo/migo). The first five are roughly equivalent to the same cases in Latin (the ablative is only different in that it can't imply pronouns as the ablative case in Latin can), but the last one is a bit more interesting.
That's the accepted explanation, anyway; and perhaps the correct one. But while I was doing my research, I came across something very interesting. The comitative case also exists in Estonian, an east-European language. In Estonian, the comitative case is formed by adding the suffix -ga to either the genitive or the partitive case. Maybe that's just coincidence, but you've got to admit the probability of two languages using very similar form for the same function by pure chance is rather low; enough to be intriguing.
Freakin' Awesome
Researchers led by the Institute of Cognitive Science and Technology in Italy are developing robots that evolve their own language, bypassing the limits of imposing human rule-based communication.
...The most important aspect is how it learns to communicate and interact. Whereas we humans use the word ‘ball’ to refer to a ball, the AIBO dogs start from scratch to develop common agreement on a word to use to refer the ball. They also develop the language structures to express, for instance, that the ball is rolling to the left. The researchers achieved this through instilling their robots with a sense of ‘curiosity.’
Initially programmed to merely recognise stimuli from their sensors, the AIBOs learnt to distinguish between objects and how to interact with them over the course of several hours or days. The curiosity system, or ‘metabrain,’ continually forced the AIBOs to look for new and more challenging tasks, and to give up on activities that did not appear to lead anywhere. This in turn led them to learn how to perform more complex tasks, an indication of an open-ended learning capability much like that of human children.
Also like children, the AIBOs initially started babbling aimlessly until two or more settled on a sound to describe an object or aspect of their environment, gradually building a lexicon and grammatical rules through which to communicate.
That is absolutely godly. I want a litter of those.
Tuesday, June 20, 2006
& Linguistics - Case - English
Pronouns are the most vivid artifact of old English declension, having three cases: subjective, objective, and possessive. The subjective, corresponding to the Latin nominative, refers to the subject of the sentence (e.g. "I still believe that you can call out my name"); the possessive, corresponding to the Latin genitive, refers to the possessor of some other noun (e.g. "in my dearest memories"); finally, the objective, corresponding to the Latin accusative, dative, and ablative, refers to anything not a part of the other two cases (e.g. "I see you reaching out to me"). If you think about it for a minute, you'll realize that some distinct cases of the same pronoun are identical (e.g. the subjective and objective forms of "you").
For nouns, the subjective and objective cases are identical (e.g. "Kaity"). The possessive case, however, remains distinct (e.g. "Kaity's).
Interestingly, Old English used to have five cases: nominative, accusative, dative, genitive, and instrumental; as well, not only pronouns and common nouns, but also adjectives were declined. The instrumental case refers to the means by which the action of the sentence is performed. If Latin had had an instrumental case, "with burning truth" would probably have used it (but not "until the fated day", despite the fact that both use the ablative case in Latin). Interestingly, Old English lacked an ablative case; presumably the reason for this is that it relied on propositions to fill this role, as does modern English.
And for a few tangentially related bonus topics. I looked it up today, and vizzini (who is actually my boss) is right: proper nouns are declined in Latin. Also, I just had a question pop into my head: if we're evolving from simple to complex, why are languages evolving in the exact opposite way - English, Greek, etc.?
Monday, June 19, 2006
& Linguistics - Case - Latin
Today I'm going to go into a bit of a different topic - linguistics. Why? Because I feel like it. Specifically, I'm going to talk about case *ahem*
Case refers to alterations ("declension") of nouns and possibly adjectives, based not on what the nouns/adjectives refer to (though they usually do that, too), but in what manner they are used in the sentence in which they appear (phrased differently, what grammatical role they play).
The stereotypical declined language is Latin. All common (as opposed to proper) nouns and adjectives are declined - the exact word used depends on the case, in addition to other things like gender and number. Latin has six distinct cases: nominative, genitive, accusative, dative, ablative, and vocative. The nominative case refers to the subject of the sentence ("somnus non est" - "the sleep is no more"); the genitive case refers to the possessive ("invenite hortum veritatis" - "find the garden of truth"); the accusative case refers to the direct object ("urite mala mundi") "burn the evil of this world"); the dative case refers to the indirect object (e.g. "dona nobis pacem" - "give us peace" *); the ablative case being like the object of a preposition ("ardente veritate" - "with burning truth"); finally, the vocative case is used when speaking to someone ("exitate vos e somno, liberi fatali" - "arise from your sleep, fated children"). There's also a locative case, but that's rare, and sometimes omitted from dictionaries (and, more importantly, I'm not familiar with it).
If you were particularly alert, you might have noticed some things in those examples. Like the difference between "veritatis" and "veritate", "somnus" and "somno" (different cases of the same nouns); or the similarity between "ardente" and "veritate", "liberi" and "fatali" (paired adjectives and nouns in the same case). Or you might have even noticed in "ardente veritate" or "diebus fatalibus" ("until the fated day" - not shown previously), examples of the ablative case, that there is no proposition at all ("with" and "until", in English).
The use of a moderate set of cases in Latin (and the fact that nouns and adjectives are declined) make it a language that lends itself to poetry. Similar suffixes provide natural rhyming of similar thought patterns; the fact that sentence structure is determined by word form rather than word order allows free arranging of words in a sentence (within reason) while retaining meaning. The ablative case lends itself to poetic use, as well, but not in an immediately obvious manner. As the use of the ablative can imply the existence of a preposition without ever stating it (though there are also prepositions which may be explicitly used), it serves to reduce the precision of the language (as it's possible that more than one preposition would be appropriate in a given context), and lends itself to poetic metaphorical constructs.
* Sorry, there is no use of the dative case in Liberi Fatali, so I had to borrow one from Salva Nos
Thursday, June 08, 2006
Day One
10 or 15 minutes later, back at my computer, I decide to venture into the company's product. Double-click and... it fails to start with some vague error message. I call over Skywing, who spends half an hour or so debugging it and looking through the debug logs, to locate the cause. His first attempt to debug it used some debugger I'm not familiar with ("SD"). This resulted in the debugger crashing... repeatedly. Highly amused (it was pretty funny), Skywing ran over to the boss to tell him "Hey, Justin crashed SD!" The boss responded with something along the lines of "He what?!". "I'm not touching your LibQ!" followed closely, from another cubicle.
Despite the fact that he was joking (and it was actually pretty funny), LibQ ended up having the last laugh. Later in the day, I was randomly looking through the source code for their program (I figured that would be helpful when I, you know, actually have some work to do). After not too long, I found a piece of code that immediately set off red lights in my head. While it apparently works on Linux (that's what their server platform is), it will break on some versions of Unix (like OS X), should they ever decide to offer the program for other Unixes (which our boss, who's half coder, is actually working on, in whatever time he doesn't spend doing managerish stuff). So I filed my first bug report, in which I explained the problem, and referred them to the solution I used in LibQ (yes, I actually mentioned LibQ in the bug report).
Ding dong, the witch is dead!
Abu Musab al-Zarqawi, the al-Qaida leader in Iraq who waged a bloody campaign ofhttp://msnbc.msn.com/id/13195017/
suicide bombings and beheadings of hostages, has been killed in a precision
airstrike, U.S. and Iraqi officials said Thursday. It was a long-sought victory
in the war in Iraq.
Wednesday, June 07, 2006
Toto, I've a feeling we're not in California, anymore
Anyway, I'm too sleepy to think straight, and these phantom flight sensations are getting on my nerves. I think it's time for bed.
...and this laptop they're letting me borrow just started making an odd noise.
Sunday, June 04, 2006
So I Was Bored and...
Comparing runtime, space consumption, and virtual memory footprints over a range of benchmarks, we show that the runtime performance of the best-performing garbage collector is competitive with explicit memory management when given enough memory. In particular, when garbage collection has five times as much memory as required, its runtime performance matches or slightly exceeds that of explicit memory management. However, garbage collection’s performance degrades substantially when it must use smaller heaps. With three times as much memory, it runs 17% slower on average, and with twice as much memory, it runs 70% slower. Garbage collection also is more susceptible to paging when physical memory is scarce. In such conditions, all of the garbage collectors we examine here suffer order-of-magnitude performance penalties relative to explicit memory management.
So, garbage collection doesn't sound so good for practical applications. Interestingly, this apparently debunks my belief that garbage collection was the optimal memory allocation strategy to use for embedded systems that are very tight on memory. Well, maybe, maybe not. I was thinking in terms of memory usage. Garbage collection allows blocks to be relocated in memory, allowing new allocations of arbitrary size to get around fragmentation problems (assuming there's enough free memory, period). But this report shows that doing so would come at a hefty performance cost, which may or may not be tolerable.
GNUPlot Update
Saturday, June 03, 2006
Another Random Factoid
Random Factoid
I suspect the Windows Low-Fragmentation Heap also functions like this, as well. Sometime I should reverse-engineer it to see if it's lock-free or has multiple locks (MSDN says it's multi-processor friendly, so it must at least have multiple zone locks).
On Vectors and Lists
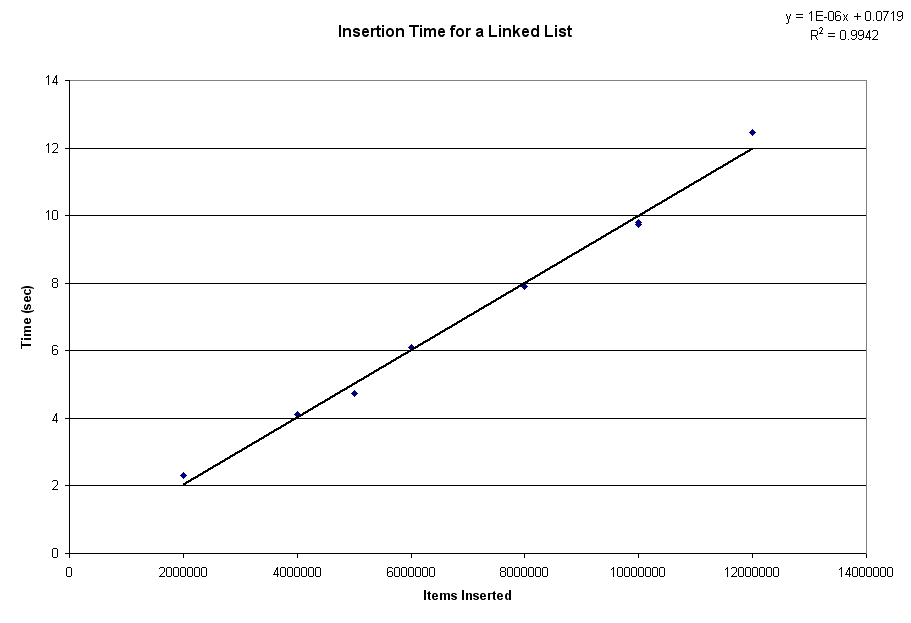
Your basic list is very simple: each item is allocated from the heap, and does not require copying of any existing data items at any time. Insertions take O(1), and a string of insertions take O(N), as illustrated by this benchmark:
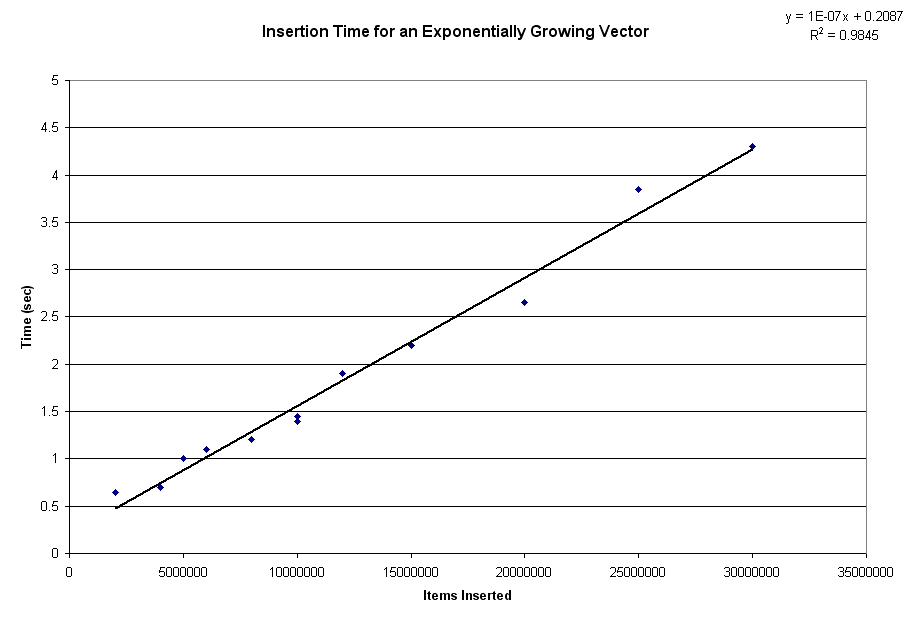
A vector is an array that gets resized whenever it gets full. When items are merely added to the end of an existing array, additions are O(1), and a series of additions are O(N). However, the process of resizing the array, which requires all existing items be copied, is O(N). This means that if you resize an array after a constant number of additions, additions to a vector will take O(N), and a string of additions will take O(N^2), as illustrated by this benchmark (the two series represent how much additional space was allocated each time the array was resized; 10 is the actual number GNUPlot uses when it reallocates its data array during file loading):

This is the WRONG way to use a vector. The correct way is to increase the size of the vector exponentially. In my benchmark I used a factor of 2 - every time the array became filled, its size was doubled. Since it's growing exponentially, the number of allocations that must be done (each taking O(N)) will be O(1/2^N); O(N * 1/2^N) = 0. Thus the time to reallocate the array is negligible, and the complexity is determined strictly by the time to add each new elements to the already allocated array: O(1) per element, and O(N) for a series of elements. This is shown in the following graph:
Thursday, June 01, 2006
Regression: The Storm Strikes Back
Well, after messing with GNUPlot for most of the day, I believe I've obtained one of the results I sought: the regression equations for the different allocators. I cut off data points above 100,000 cycles based on looking at a couple plots; nearly all of the points were below 100,000 cycles, but some were significantly above that, and I wanted to minimize skewing due to outlier points. Nevertheless, there was a very large amount of variance in the data set (especially in the case of SMem), so you can expect a fair margin of imprecision. As well, I used the non-linear least-squares algorithm supplied in GNUPlot, which is somewhat susceptible to outlier points; at some point I may try recomputing the regression values using a robust regression method (something less susceptible to outlier points).
I suppose I should be getting used to the results of various experiments in this project surprising me, but I'm not; and this set of data came as one of the biggest surprises, after all the previously collected data. All regressions were performed using the general form m*(N^xp) + b, where m, xp, and b were solved for by the regression algorithm. I performed the graphs of the regression lines as log-log to maximize visibility of differences over the greatest range of points; you should not mistake these for linear graphs (for example, every single regression line was O(N^x), where x was less than 1, usually around 0.5; the log-log graphs, however, seem to suggest x is always greater than 1).
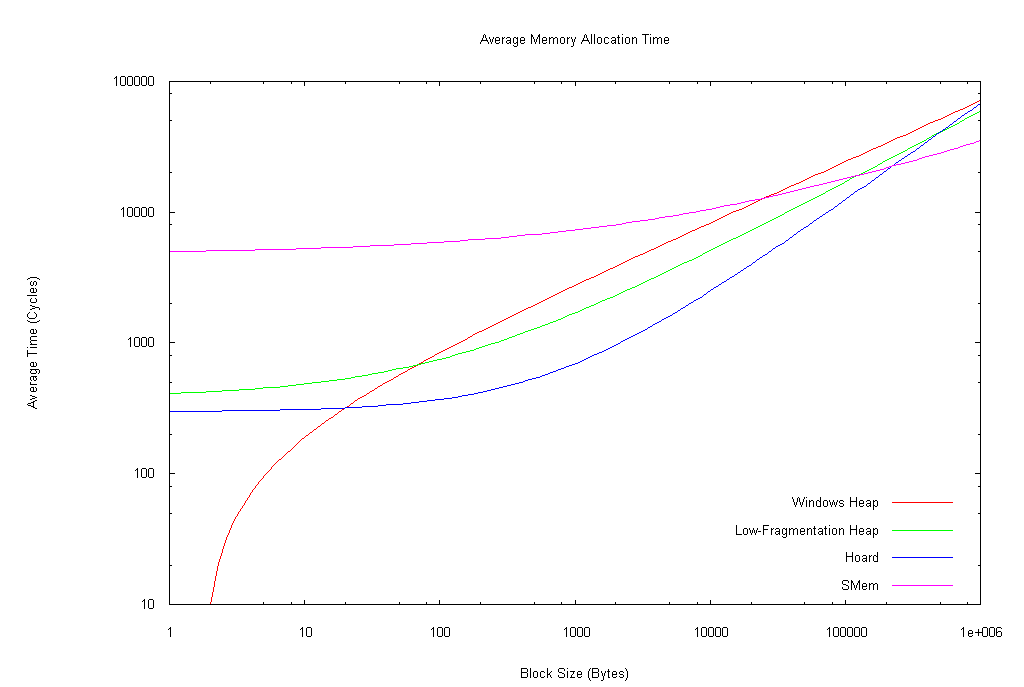
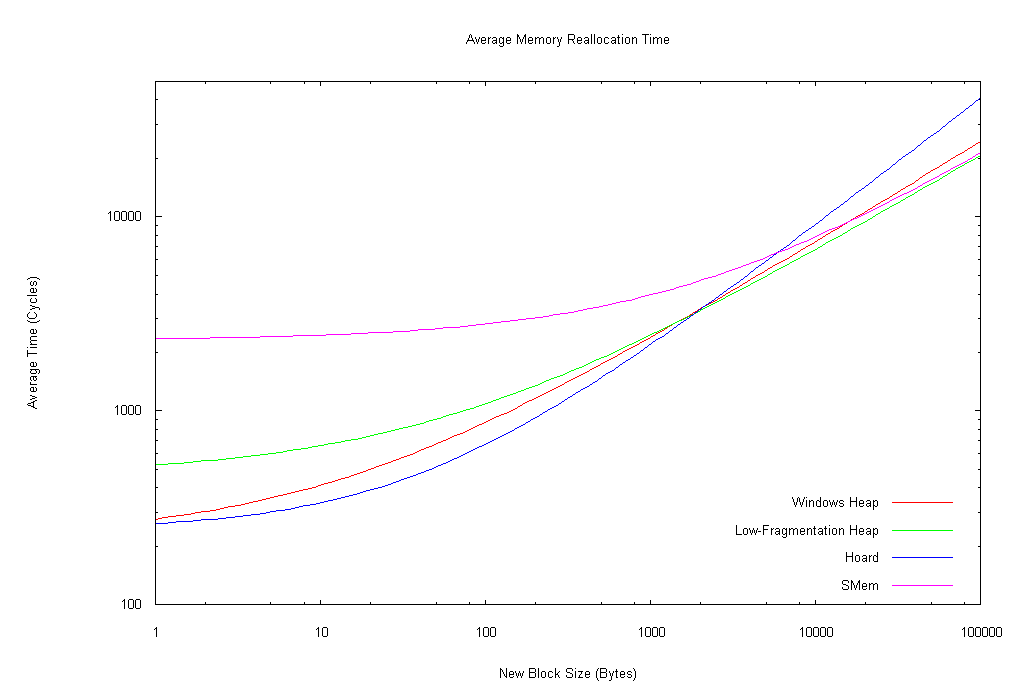
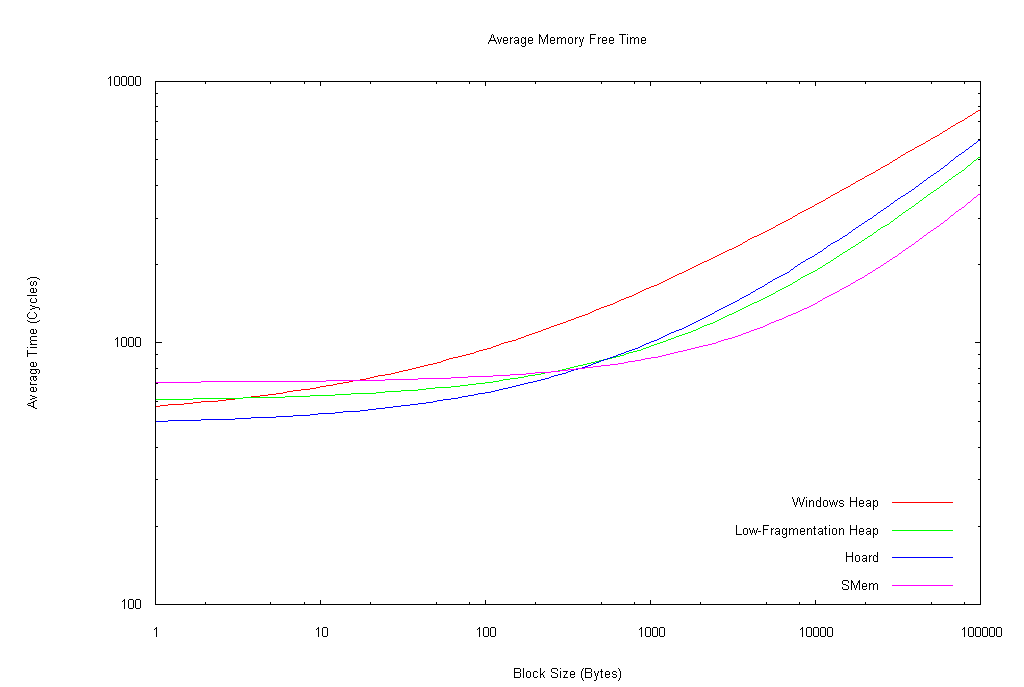
Most notably, SMem (Storm) takes a substantial lead at upper block sizes for allocations and frees (above 220 KB and 371 bytes, respectively); as well, it's not significantly worse than the other heaps at reallocations above about 5 KB. And no, the Windows heap doesn't really get down to negative cycles for allocations approaching 0 bytes; that's just an artifact of the regression calculation.
So, why did Storm perform so poorly in the bar charts? Well, that's relatively easy to offer an explanation for: it's probably because most of the allocations were smaller than Storm is optimal for. Though this does make me think that I should do some real-world tests, like replace all of SMem in Warcraft III with the other allocators, and see how long things like starting up, loading a map, and completing a map take (in other words, looking at clusters of operations that naturally occur together, which my benchmark is unable to take into consideration).
GNUPlot Fun
So, I tried repeating the graph, telling it to graph every 20th data point, to see if the graph quality would be acceptable, while rendering in a reasonable amount of time (66 minutes / 20 = 3 minutes and 18 seconds, right?), using the handy stopwatch on my cell phone. This took 15 seconds. After a brief "OMGWTFBBQ" moment, the solution came to me: it was executing in exponential time. Gathering a few more times (1/17, 1/15, 1/12, 1/10, 1/8, and 1/5) confirmed this hypothesis: it was executing in O(N^2) time.
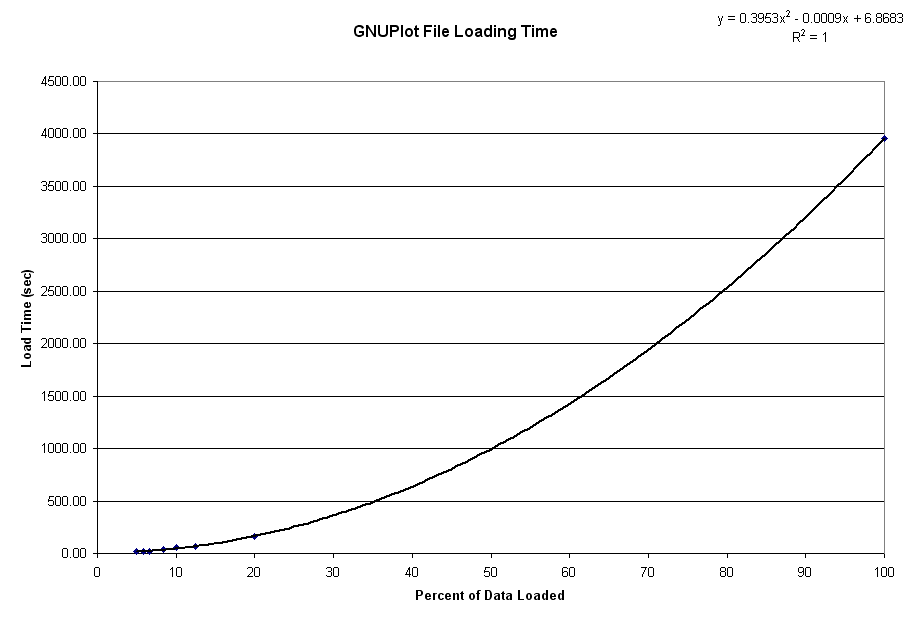
I can think of one "good" reason why it might be doing that: it's probably storing the data in a vector - a dynamically resizing array. Every time it gets resized, it has to copy the entire data set (which is almost 500 megs, by the end). This would produce the observed O(N^2) time. It also explains an odd behavior I observed while watching the GNUPlot execute in task manager. While loading the file, the memory usage increases over time. But the physical memory usage was ping-ponging all over the freakin place, varying at times by hundreds of megs (up and down) from second to second. I couldn't figure that one out, either; it was way too fast to be due to paging (my first thought). But it makes perfect sense if it's continually reallocating its buffer, copying the contents, and then freeing the old buffer.
*sigh* It seems like lately every program I've used I've needed to debug some catastrophic flaw in it. I have enough to do with debugging my own programs; you people need to leave me alone :P

