Hey, does anybody remember the days when I actually wrote stuff on this blog? Those were good times.
Well, in case anybody actually remembers that far back, one of the things I'm known for is my topic du jour manner of self-education. I hear about some topic (or it comes up in some thought process), I research it for anywhere from a few days to a few months (however long it holds my interest), then I move on to some other topic. This week's topic du jour is
cache-oblivious algorithms.
To explain what cache-oblivious algorithms are and why they're good, let's work through an example.
Suppose we've got a sorted array of 2^24 32-bit values, for a total size of 64 MB, and we need to determine if it contains a given value (if not, to find the nearest values). As we know that the list is sorted, binary search is the obvious choice, as it's known to be O(log N) complexity; note also that a sorted array is effectively an
implicit binary search tree with items stored in-order, and the binary search is just a traversal of that tree. This complexity dictates that the search will require approximately log2(2^24) = 24 comparisons, each by definition involving a memory access (obviously, as the array is stored in memory).
Now consider a similar array containing 2^8 32-bit values (total size of 1 KB). According to the
big O, a search through this array will take about 8 comparisons - 1/3 as many as the 2^24 array. Now, while these two numbers are accurate, they're highly misleading. By that measure, you'd expect it to take three times as long to perform the 2^24 search as the 2^8. It doesn't. In fact, the difference is well over an order of magnitude.
The reason for this discrepancy is the assumption that all memory accesses are equal. This is invalidated by the existence of processor (and other) caching, where cache hits are significantly faster than cache misses, as well as
Non-Uniform Memory Architectures, where different memory banks have different access times for different processors. The 1 KB array can easily be held entirely in the processor's L1 cache, and in theory all accesses will be cache hits. The 64 MB array, on the other hand, can't even be held in L2 or L3 cache, so most memory accesses will be cache misses, and must go all the way to main memory.
Of course, main memory isn't that extreme of an example, as it isn't
too much slower than processor cache. The real killer is when you have something (e.g. a database) that can't be held entirely in memory, and must be read from disk as needed (or worse, accessed over the internet at a speed that makes hard disks look fast). Hard drives are about a million times slower than RAM, meaning that each and every disk access is an excruciating performance hit, and the internet can be an order of magnitude worse.
Unsurprisingly, a massive amount of research effort over the last half a century has been in minimizing that amount that must be read from disk, especially in the class of cache-aware algorithms. Cache-aware algorithms are algorithms that are tuned (typically parametrized) for a specific system configuration (e.g. cache size) to achieve performance superior to algorithms that don't take such configuration into consideration.
One of the most common cache-aware algorithms, used in most file systems and database structures, is the
B-tree (and family members), an upside-down (non-binary) search tree designed to minimize the number of disk accesses in searching data sets too large to fit entirely into memory. The B-tree is cache-aware because the block size can be adjusted to perform optimally on a given system configuration through either abstract math or actual benchmarks, and the optimal size for one configuration may perform poorly on another configuration.
Surprisingly, only in the last decade have people seriously investigated whether it is possible to create algorithms that make optimal use of a system configuration regardless of what exactly that configuration is, with no parametrization. This type of algorithm is called cache-oblivious algorithms.
Sometimes this is easy. A sequential scan of an array that does something on every element in order is cache-oblivious because it produces the provably minimum number of cache misses regardless of how the cache works. Divide and conquer algorithms that access each item in an array are also generally cache-oblivious and provably optimal because they ultimately divide enough to operate only on what's in a single cache line, regardless of what size the cache line is, before moving on to the next cache line (assuming, of course, that the size of each element is small in relation to the size of a cache line); in other words, they have a more or less linear scanning memory access pattern.
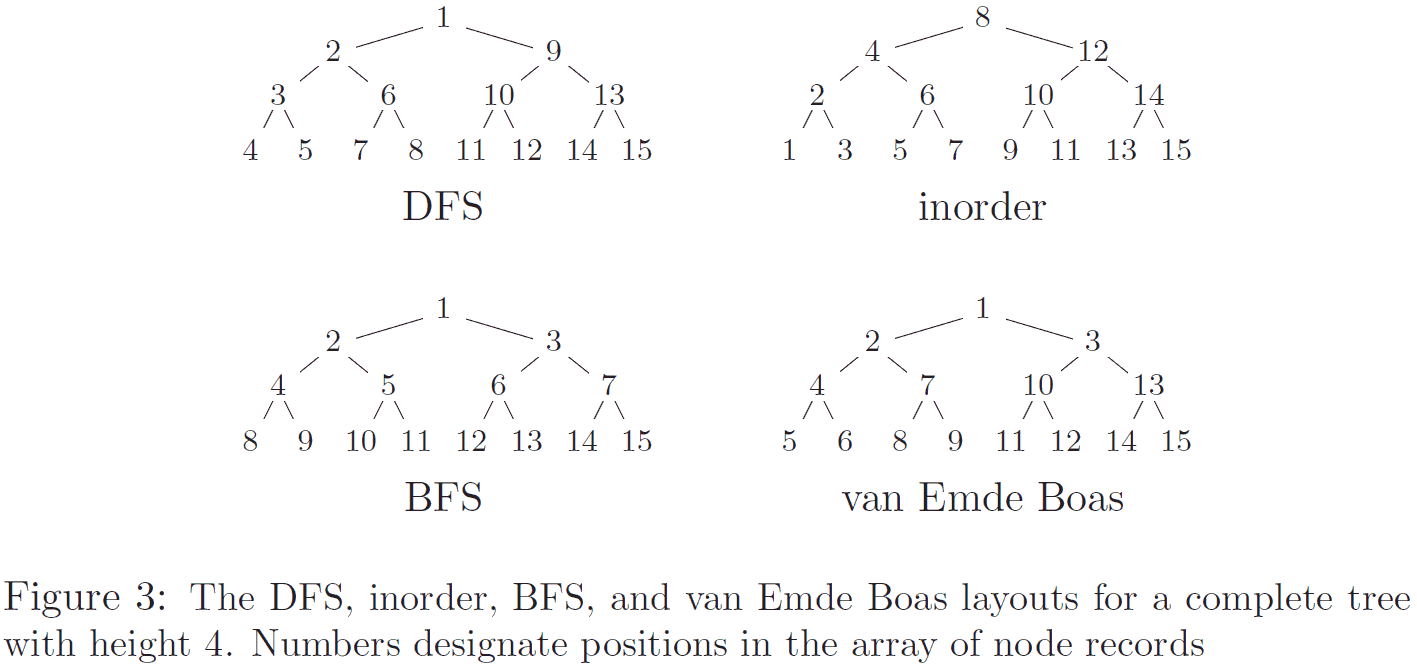
Binary search, however, is not cache-oblivious, as it's not a true divide and conquer algorithm in the sense that matters to us; specifically, it does not access all elements, and therefore does not get to take advantage of the predominant locality in the array. However, we can make a cache-oblivious implicit binary search tree by changing the ordering of items. To maximize performance, we want to lay out the nodes of the binary tree such that child nodes are as close as possible to their parents as often as possible, resulting in a minimal number of cache misses.
The key here is what's called the
van Emde Boas layout (VEB) (you can tell I use
HTTPS Everywhere because my Wikipedia links are all HTTPS). The basic idea is that the (triangular when drawn on paper) tree is divided recursively into (triangular) subtrees, with all nodes in each subtree being clustered together. This gives it a fractal structure with child and parent nodes being as close as possible to each other, maximizing cache locality during searches without needing to know the details of the cache system. A short tree in this form is shown below; below that is a comparison with trees in in-order,
breadth-first (BFS), and
depth-first search (DFS):


It's worth noting that cache-oblivious structures may or may not be as fast/faster than the simpler forms when the entire data set is in the same level of cache (whether you're talking about L1, RAM, etc.). One of the papers (the same
one the images are from) examined the performance of static (non-changing) binary trees stored in in-order, BFS (an order that gives some cache locality while still being trivial to calculate child positions for), DFS, and VEB order, as well as two cache-aware search tree formats. In this experiment, the tree was stored in memory and cached in the processor cache - cache hits stay in the processor, cache misses go to main memory.
In the case of VEB, the complex fractal structure makes it nontrivial to calculate the position of a node's children in the array. As a result, when the entire data structure is in cache, calculation of child position takes longer than memory accesses, and VEB is about 40% slower than the standard in-order ordering. VEB begins to outperform in-order ordering once about half of the tree does not fit into cache; this calculation complexity problem can be overcome by storing child pointers with each node, but this is rather self-defeating, as this only multiplies the amount of data that has to be fit into the limited cache. In almost all cases, the cache-aware algorithms were superior to the others, but obviously require tuning to the particular cache, which is exactly what we're trying to avoid. BFS also performed admirably, always at least 15% faster than in-order ordering, and superior to VEB when more than ~1.5% of the data was able to fit into cache.
Another article compared a cache-oblivious binary heap based on VEB ordering with a
standard binary heap using BFS ordering, in the context of a real-world internet page cache in actual use. Here, the heap is stored on (solid state) disk and cached in memory - cache hits go to memory while cache misses go to the disk. As in the previous benchmark, VEB performed 30% worse than the standard BFS when the entire tree could be stored in cache, but outperformed BFS when more than 0.2% of the tree was not stored in memory (I would guess this threshold is so low due to the many order of magnitude difference between memory and disk performance). At the other end, VEB peaked at 10x the speed of BFS when most of the tree was not cached. I imagine the reason this wasn't much higher was that in this real-world benchmark the priority queue was very small relative to the other data that is being accessed, and as such performance was dominated by other operations.
In the ~10 years researchers have been working on this, an array of cache-oblivious algorithms have been described, such as searching, sorting, linked lists, heaps, matrix multiplication and transposition, and various geometric algorithms such as 3D bounding volumes. The list of stuff I've seen so far (though not necessarily read through completely) is shown below, though I'm certain there are other things out there as well.
Cache-Efficient Layouts of Bounding Volume Hierarchies [and space partitioning]Cache-Oblivious Algorithms (overview and survey)
Cache-Oblivious Algorithms and Data Structures (overview and survey)
Cache Oblivious Distribution Sweeping (sorting and various geometric algorithms)Cache-Oblivious Dynamic Search TreesCache-Oblivious Priority Queue and Graph Algorithm ApplicationsCache Oblivious Search Trees via Binary Trees of Small Height
You're Doing It Wrong (overview and heap algorithm applied to a real-life internet cache program)