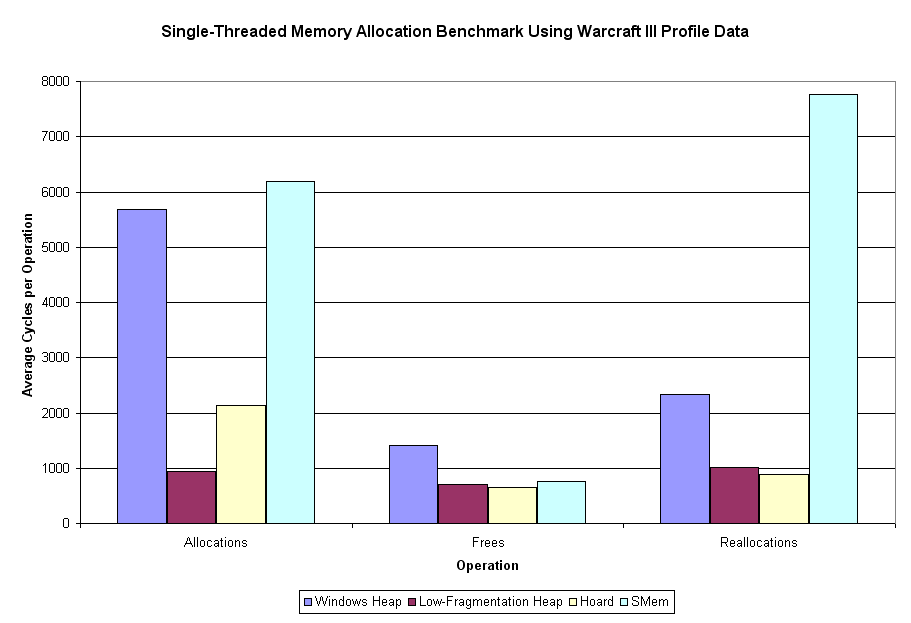
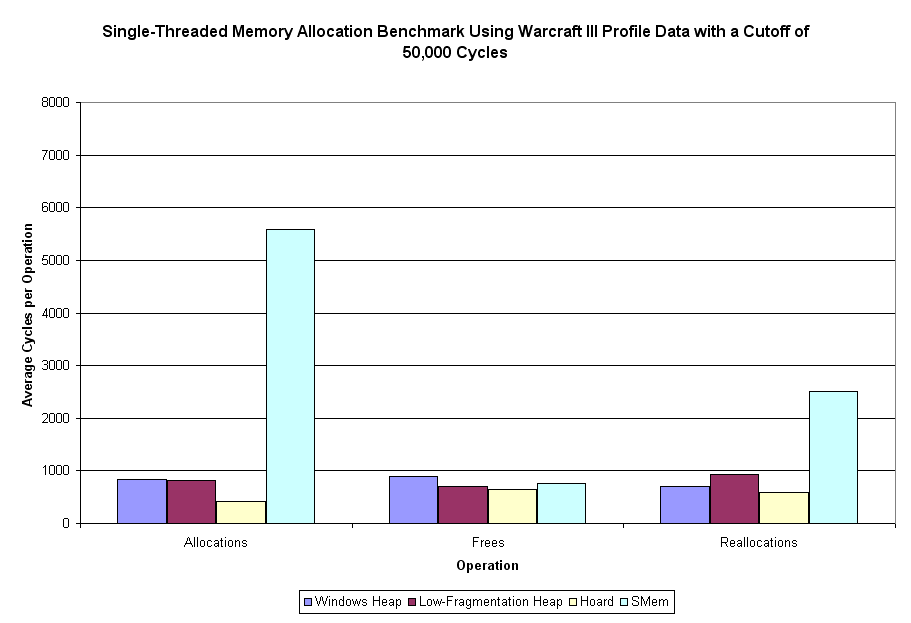
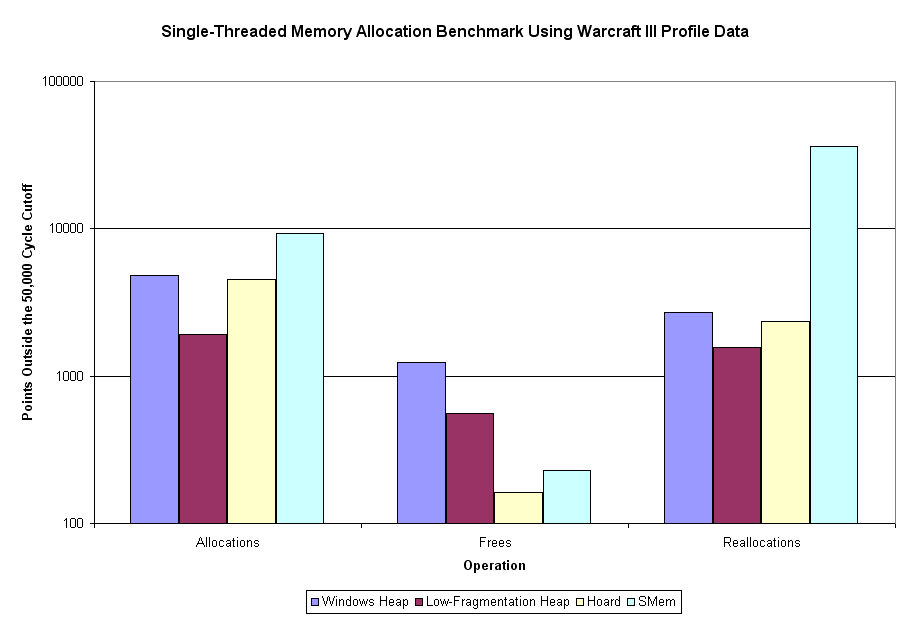
Sweet mother of Kaity - that's more than a little bit different than the first time around. The Windows heap is 7x, 1.5x, and 3x as fast as it was before the cutoff. Other than that, the Hoard allocation speed is about 5x what is was, and SMem reallocation speed is about 3x what it was. All the other categories are no more than 10% different (faster) than what they were originally.
What this tells us is that some operations (the ones just listed) on some allocators have dramatically greater variance in operation time. Exactly which of these two versions is the more accurate, I couldn't really tell you. I'd tend to think the first one (the one including outlier points) would be the more representative of actual usage, although it's more susceptible to outlier points skewing the averages.


No comments:
Post a Comment