While solar panels are dark blue, almost black, they are also reflective. This means that they will likely appear white or some other bright color, which may be a big shock (and a big aesthetic problem) if you have a dark roof and the panels are clearly visible.
My parents are NOT amused.
Update: Actually this is only the case when the sky is cloudy, which it was the day my parents had the panels installed. When the sky is clear they look like they do without the reflection.
Monday, October 18, 2010
Tuesday, September 21, 2010




Wednesday, September 08, 2010
Public Service Announcement
When you call Discover card customer service, the very first thing you have to do is enter the last 4 digits of your Discover card, last 4 digits of "your social security number", and your ZIP code. It's important to note here that "your social security number" and "your ZIP code" do NOT mean "your social security number" and "your ZIP code"; it means the social security number and ZIP code of the primary cardholder, which may or may not be you.
Discover card apologizes for the inconvenience of refusing to even let you talk to a real person without providing something it specifically did not ask for.
Discover card apologizes for the inconvenience of refusing to even let you talk to a real person without providing something it specifically did not ask for.
Wednesday, August 04, 2010
NWScript Stack System
Note: SW has written a new post, talking about NWScript in general, akin to my post yesterday (though possibly in more detail than mine; I haven't actually read it all yet).
So, now we know where we are (the NWScript system), and where we need to go (LLVM assembly). Now, how do we get there?
Well, a lot of things are simple enough, requiring only trivial use of LLVM and a parser. But after investigating the NWScript system for this purpose, I identified several areas that would be nontrivial and would require some thought and effort, which I'll discuss.
The first challenge - that is, a nontrivial design issue - was the stack machine. Stack machines are easy to interpret, but harder to convert to something like LLVM assembly that uses registers (like real assembly languages) and strongly declared and typed variables (unlike real assembly languages). Stack machines use a huge number of stack locations during execution, the vast majority of them (more than 96% of them, in one sample I looked at) temporary copies that last only until the next math (or other) instruction. From the opposite perspective, it's necessary that all accesses of a single variable be mapped to the same memory location, regardless of where the variable is, relative to the top of the stack. It's even possible that multiple separate locations in the code could create a stack location that represents only a single variable, despite being created in multiple places.
To illustrate these problems, a few examples:
Here, we can see two stack locations are created that do not represent variables at all, but rather temporary parameters to the MUL instruction. A third temporary that also is not a real variable is created as the return value to the MUL instruction, which is then used as a parameter to the ADD instruction along with a fourth temporary copied from a variable. Finally, a fifth temporary is created for the return value from the ADD instruction, which is copied down to a result variable and destroyed. The C code for this would be
It may also be possible to use the stack as, well, a stack, building up a variable-length list of things as they're processed in one loop, then popping them in a second loop. I can't think of a practical use for this off the top of my head (something that is both useful and couldn't be accomplished any other way), but it might be possible.
So, the stack system poses challenges related to identifying variables. However, a second, less obvious problem exists, although it's not as specific to stack machines. In this case, the problem relates to functions. In NWScript, a call consists of:
The solution I came up with to this problem (as well as other problems, which I'll talk about in the future), was a two-pass system that performs analysis and intermediate code generation (intermediate code is an expanded form which deals with variable references rather than the stack, making it much easier to work with; this intermediate code would then be converted to the output code type in a third pass). The two passes could have been done in a single pass, but this would have been quite messy and needlessly memory-hungry, as opposed to the more elegant and efficient two-pass system.
First Pass
The first pass through the script file performs a couple tasks. It identifies functions and code flow blocks: the largest groups of instructions that execute as an atomic unit and have only a single execution path from the first to the last instruction in the block. It also determines the number of parameters and return values for each function (in NWScript, functions only have a single return value, but when the bytecode is generated, structs and other complex types are flattened to primitive types, making it look like there are multiple return values).
This pass is quite simple. It proceeds by scanning through the code, beginning with the main function, parsing each instruction as it goes. The current stack pointer (but not an actual stack) is maintained from instruction to instruction. As well, a code flow graph is created by watching for branch instructions and creating new flow blocks and splitting old ones (if a branch jumps into the middle of an existing flow, that flow must be split, as it's not an atomic unit). Finally, entries for functions are created as they're encountered.
The biggest trick here is dealing with function calls. The effect of other operations on the stack can be trivially calculated by decoding the instruction, but we can't step past a call instruction until we know the stack displacement. The same is true for calls to API functions, but we already know exactly what they do to the stack, as those are a closed set.
What I decided to do was to use a task queue. When a new, previously unencountered function is encountered in a call, a new function entry and task queue entry corresponding to the function are created, and the current analysis task is marked as blocking on that function. Conditional branches are handled more or less the same way: a new task is created for one branch, though not blocking on anything, and analysis continues at the other branch. Whenever the current task blocks (e.g. it calls an unanalyzed function), analysis switches to the first task in the queue that is not blocking on anything, and execution continues from there.
Tasks ultimately complete when a return is encountered. When that occurs, the number of parameters for the function is calculated by the difference in stack pointer from the beginning of the function to the end. The function is marked as analyzed, and any tasks blocking on the function are unblocked and may potentially continue analysis. The number of return values is determined by observing the lowest stack address written to within the function. This requires that all paths through a function be evaluated, but as the return value does not affect overall stack displacement, tasks blocking on the function may resume prior to determining the exact number of return values.
While this can potentially generate a large number of blocked tasks in the queue, so long as the script does not contain a loop that has no exit path or a function that calls itself recursively without a path that returns, this is guaranteed to ultimately locate a function that can return. While functions may have multiple paths from beginning to end, and all must eventually be traversed, we need only a single path to return to know the function's displacement, resulting in unblocking of tasks waiting on that function. This discovery process cascades, and analysis of all routes through the script eventually completes.
Second Pass
After the completion of the first pass, we now know all functions, code flows, and the number of parameters and return values for each function. The second pass performs several functions:
The code for this pass resembles a mini-interpreter (well, I suppose it is), including a stack filled with references to the variable objects at that location. A new variable object is created each time some manner of instruction pushes a variable on the stack. To make things simpler during processing and final code generation, variables are explicitly created and destroyed with dedicated instructions in the intermediate code, unlike the implicit generation/destruction in the bytecode.
Because the stack is necessary to determine what variables individual instructions reference, functions must, as in the first pass, be executed in control flow order, rather than simply evaluating each flow in the list in random order (as we do with functions). The stack at the end of each flow is saved until analysis of the function completes, so that successor flows evaluated later can pick up the stack where the previous flow left off (and one other reason I'll explain in a second).
Most of the details of the second phase relate not to the topic of this post, but to later ones. One detail worth mentioning, however, is that after all flows for a function have been evaluated, stack merging occurs. Because it's possible that a stack location might be created in two separate locations that together form a single variable (as in the example above), when multiple flows converge in a single successor flow, the stacks from each of the predecessor flows must be merged: for each offset in the stacks, the variables in each corresponding position are merged, eliminating all but one copy. Because the intermediate code representation is flexible, variable merging is trivial, and requires no modification of the intermediate code itself.
However, for this and other reasons, this compiler does not, as of now, support variable use of the stack: when the stack is extended to a variable length by a loop or some such, as mentioned earlier. There is no way to generate such a structure in NWScript (the scripting language), and manually-written bytecode files are anywhere between incredibly rare and non-existent, so we thought that was a reasonable omission.
One really cool thing about this system, however, is that the host program can be a hybrid of interpretation and compilation. E.g. the compilation of all scripts can be offloaded to a worker thread when a module is loaded to compile in the background, and the host program can use the interpreter for a script until compilation of that script finishes. The interpreter could also be used as a fall-back for scripts the compiler is unable to compile for one reason or another, such as those with evil stack usage.
Below is an example of a random block (a flow, to be precise) of bytecode and its corresponding intermediate code. Note that the addresses differ by 0xD because the bytecode block is generated by a disassembler that includes the file header in the address:
And lastly, perhaps getting ahead of myself, the same segment after running it through my variable optimization pass:
For those keeping score, that's 17 instructions in the original bytecode, 43 in the raw intermediate code (26 that are create or destroy, 9 that are assigns to temporary variables), and 19 in the optimized intermediate code (10 that are create or destroy; if that still sounds like too many, note that all of those variables will be converted to registers in LLVM).
So, now we know where we are (the NWScript system), and where we need to go (LLVM assembly). Now, how do we get there?
Well, a lot of things are simple enough, requiring only trivial use of LLVM and a parser. But after investigating the NWScript system for this purpose, I identified several areas that would be nontrivial and would require some thought and effort, which I'll discuss.
The first challenge - that is, a nontrivial design issue - was the stack machine. Stack machines are easy to interpret, but harder to convert to something like LLVM assembly that uses registers (like real assembly languages) and strongly declared and typed variables (unlike real assembly languages). Stack machines use a huge number of stack locations during execution, the vast majority of them (more than 96% of them, in one sample I looked at) temporary copies that last only until the next math (or other) instruction. From the opposite perspective, it's necessary that all accesses of a single variable be mapped to the same memory location, regardless of where the variable is, relative to the top of the stack. It's even possible that multiple separate locations in the code could create a stack location that represents only a single variable, despite being created in multiple places.
To illustrate these problems, a few examples:
// var1 * 0x1E
CPTOPSP FFFFFFEC, 0004
CONSTI 0000001E
MULII
// + var2
CPTOPSP FFFFFFEC, 0004
ADDII
// var3 =
CPDOWNSP FFFFFFF0, 0004
MOVSP FFFFFFFCHere, we can see two stack locations are created that do not represent variables at all, but rather temporary parameters to the MUL instruction. A third temporary that also is not a real variable is created as the return value to the MUL instruction, which is then used as a parameter to the ADD instruction along with a fourth temporary copied from a variable. Finally, a fifth temporary is created for the return value from the ADD instruction, which is copied down to a result variable and destroyed. The C code for this would be
var3 = (var1 * 0x1E) + var2;// if (3 == 0)
00000045 CONSTI 00000003
0000004B CONSTI 00000000
00000051 EQUALII
00000053 JZ off_00000065
// true: var = 1
00000059 CONSTI 00000001
0000005F JMP off_0000006B
// false: var = 2
00000065 CONSTI 00000002
0000006B
In this second case, we have an optimized variable initialization where a stack location is created in two separate locations (depending on whether a condition is true), but is in reality only a single variable. This is from a script that has int g_i = (3 == 0 ? 1 : 2);It may also be possible to use the stack as, well, a stack, building up a variable-length list of things as they're processed in one loop, then popping them in a second loop. I can't think of a practical use for this off the top of my head (something that is both useful and couldn't be accomplished any other way), but it might be possible.
So, the stack system poses challenges related to identifying variables. However, a second, less obvious problem exists, although it's not as specific to stack machines. In this case, the problem relates to functions. In NWScript, a call consists of:
- Reserve a temporary slot on the stack for the return value
- Push the parameters in reverse order
- Call the function
- Copy and pop the return value
The solution I came up with to this problem (as well as other problems, which I'll talk about in the future), was a two-pass system that performs analysis and intermediate code generation (intermediate code is an expanded form which deals with variable references rather than the stack, making it much easier to work with; this intermediate code would then be converted to the output code type in a third pass). The two passes could have been done in a single pass, but this would have been quite messy and needlessly memory-hungry, as opposed to the more elegant and efficient two-pass system.
First Pass
The first pass through the script file performs a couple tasks. It identifies functions and code flow blocks: the largest groups of instructions that execute as an atomic unit and have only a single execution path from the first to the last instruction in the block. It also determines the number of parameters and return values for each function (in NWScript, functions only have a single return value, but when the bytecode is generated, structs and other complex types are flattened to primitive types, making it look like there are multiple return values).
This pass is quite simple. It proceeds by scanning through the code, beginning with the main function, parsing each instruction as it goes. The current stack pointer (but not an actual stack) is maintained from instruction to instruction. As well, a code flow graph is created by watching for branch instructions and creating new flow blocks and splitting old ones (if a branch jumps into the middle of an existing flow, that flow must be split, as it's not an atomic unit). Finally, entries for functions are created as they're encountered.
The biggest trick here is dealing with function calls. The effect of other operations on the stack can be trivially calculated by decoding the instruction, but we can't step past a call instruction until we know the stack displacement. The same is true for calls to API functions, but we already know exactly what they do to the stack, as those are a closed set.
What I decided to do was to use a task queue. When a new, previously unencountered function is encountered in a call, a new function entry and task queue entry corresponding to the function are created, and the current analysis task is marked as blocking on that function. Conditional branches are handled more or less the same way: a new task is created for one branch, though not blocking on anything, and analysis continues at the other branch. Whenever the current task blocks (e.g. it calls an unanalyzed function), analysis switches to the first task in the queue that is not blocking on anything, and execution continues from there.
Tasks ultimately complete when a return is encountered. When that occurs, the number of parameters for the function is calculated by the difference in stack pointer from the beginning of the function to the end. The function is marked as analyzed, and any tasks blocking on the function are unblocked and may potentially continue analysis. The number of return values is determined by observing the lowest stack address written to within the function. This requires that all paths through a function be evaluated, but as the return value does not affect overall stack displacement, tasks blocking on the function may resume prior to determining the exact number of return values.
While this can potentially generate a large number of blocked tasks in the queue, so long as the script does not contain a loop that has no exit path or a function that calls itself recursively without a path that returns, this is guaranteed to ultimately locate a function that can return. While functions may have multiple paths from beginning to end, and all must eventually be traversed, we need only a single path to return to know the function's displacement, resulting in unblocking of tasks waiting on that function. This discovery process cascades, and analysis of all routes through the script eventually completes.
Second Pass
After the completion of the first pass, we now know all functions, code flows, and the number of parameters and return values for each function. The second pass performs several functions:
- Determine the types and locations of local and global variables and create variable objects for them
- Determine the types of function parameters and return values
- Generate the intermediate code
The code for this pass resembles a mini-interpreter (well, I suppose it is), including a stack filled with references to the variable objects at that location. A new variable object is created each time some manner of instruction pushes a variable on the stack. To make things simpler during processing and final code generation, variables are explicitly created and destroyed with dedicated instructions in the intermediate code, unlike the implicit generation/destruction in the bytecode.
Because the stack is necessary to determine what variables individual instructions reference, functions must, as in the first pass, be executed in control flow order, rather than simply evaluating each flow in the list in random order (as we do with functions). The stack at the end of each flow is saved until analysis of the function completes, so that successor flows evaluated later can pick up the stack where the previous flow left off (and one other reason I'll explain in a second).
Most of the details of the second phase relate not to the topic of this post, but to later ones. One detail worth mentioning, however, is that after all flows for a function have been evaluated, stack merging occurs. Because it's possible that a stack location might be created in two separate locations that together form a single variable (as in the example above), when multiple flows converge in a single successor flow, the stacks from each of the predecessor flows must be merged: for each offset in the stacks, the variables in each corresponding position are merged, eliminating all but one copy. Because the intermediate code representation is flexible, variable merging is trivial, and requires no modification of the intermediate code itself.
However, for this and other reasons, this compiler does not, as of now, support variable use of the stack: when the stack is extended to a variable length by a loop or some such, as mentioned earlier. There is no way to generate such a structure in NWScript (the scripting language), and manually-written bytecode files are anywhere between incredibly rare and non-existent, so we thought that was a reasonable omission.
One really cool thing about this system, however, is that the host program can be a hybrid of interpretation and compilation. E.g. the compilation of all scripts can be offloaded to a worker thread when a module is loaded to compile in the background, and the host program can use the interpreter for a script until compilation of that script finishes. The interpreter could also be used as a fall-back for scripts the compiler is unable to compile for one reason or another, such as those with evil stack usage.
Below is an example of a random block (a flow, to be precise) of bytecode and its corresponding intermediate code. Note that the addresses differ by 0xD because the bytecode block is generated by a disassembler that includes the file header in the address:
00005282 ACTION GetTimeHour(0010), 00
00005287 CPTOPSP FFFFFF34, 0004
0000528F ACTION StringToInt(00E8), 01
00005294 ACTION GetTimeHour(0010), 00
00005299 SUBII
0000529B ADDII
0000529D CPDOWNSP FFFFFF00, 0004
000052A5 MOVSP FFFFFFFC
000052AB CONSTI 00000000
000052B1 CONSTI 00000000
000052B7 CONSTI 00000000
000052BD CPTOPSP FFFFFEF8, 0004
000052C5 ACTION SetTime(000C), 04
000052CA CPTOPSP FFFFFF04, 0004
000052D2 CONSTI 00000000
000052D8 LTII
000052DA JZ off_0000530400005275: CREATE 01F36000 ( temp SSA int )
00005275: ACTION 0010 (0) 01F36000 ( temp SSA int )
0000527A: CREATE 01F36030 ( temp SSA string )
0000527A: ASSIGN 01F36030 ( temp SSA string ), 02102C10 ( string )
00005282: CREATE 01F36060 ( temp SSA int )
00005282: ACTION 00E8 (1) 01F36060 ( temp SSA int ), 01F36030 ( temp SSA string )
00005282: DELETE 01F36030 ( temp SSA string )
00005287: CREATE 01F36090 ( temp SSA int )
00005287: ACTION 0010 (0) 01F36090 ( temp SSA int )
0000528C: CREATE 01F360C0 ( temp SSA int )
0000528C: SUB 01F360C0 ( temp SSA int ), 01F36060 ( temp SSA int ), 01F36090 ( temp SSA int )
0000528C: DELETE 01F36090 ( temp SSA int )
0000528C: DELETE 01F36060 ( temp SSA int )
0000528E: CREATE 01F360F0 ( temp SSA int )
0000528E: ADD 01F360F0 ( temp SSA int ), 01F36000 ( temp SSA int ), 01F360C0 ( temp SSA int )
0000528E: DELETE 01F360C0 ( temp SSA int )
0000528E: DELETE 01F36000 ( temp SSA int )
00005290: ASSIGN 02102910 ( int ), 01F360F0 ( temp SSA int )
00005298: DELETE 01F360F0 ( temp SSA int )
0000529E: CREATE 01F36150 ( temp SSA int )
0000529E: ASSIGN 01F36150 ( temp SSA int ), 01F36120 ( const int )
000052A4: CREATE 01F361B0 ( temp SSA int )
000052A4: ASSIGN 01F361B0 ( temp SSA int ), 01F36180 ( const int )
000052AA: CREATE 01F36210 ( temp SSA int )
000052AA: ASSIGN 01F36210 ( temp SSA int ), 01F361E0 ( const int )
000052B0: CREATE 01F36240 ( temp SSA int )
000052B0: ASSIGN 01F36240 ( temp SSA int ), 02102910 ( int )
000052B8: ACTION 000C (4) 01F36240 ( temp SSA int ), 01F36210 ( temp SSA int ), 01F361B0 ( temp SSA int ), 01F36150 ( temp SSA int )
000052B8: DELETE 01F36240 ( temp SSA int )
000052B8: DELETE 01F36210 ( temp SSA int )
000052B8: DELETE 01F361B0 ( temp SSA int )
000052B8: DELETE 01F36150 ( temp SSA int )
000052BD: CREATE 01F36270 ( temp SSA int )
000052BD: ASSIGN 01F36270 ( temp SSA int ), 02102910 ( int )
000052C5: CREATE 01F362D0 ( temp SSA int )
000052C5: ASSIGN 01F362D0 ( temp SSA int ), 01F362A0 ( const int )
000052CB: CREATE 01F36300 ( temp SSA int )
000052CB: LT 01F36300 ( temp SSA int ), 01F36270 ( temp SSA int ), 01F362D0 ( temp SSA int )
000052CB: DELETE 01F362D0 ( temp SSA int )
000052CB: DELETE 01F36270 ( temp SSA int )
000052CD: TEST 01F36300 ( temp SSA int )
000052CD: DELETE 01F36300 ( temp SSA int )
000052CD: JZ 000052F7And lastly, perhaps getting ahead of myself, the same segment after running it through my variable optimization pass:
00005275: CREATE 01F36000 ( temp SSA int )
00005275: ACTION 0010 (0) 01F36000 ( temp SSA int )
00005282: CREATE 01F36060 ( temp SSA int )
00005282: ACTION 00E8 (1) 01F36060 ( temp SSA int ), 02102C10 ( merged string )
00005287: CREATE 01F36090 ( temp SSA int )
00005287: ACTION 0010 (0) 01F36090 ( temp SSA int )
0000528C: CREATE 01F360C0 ( temp SSA int )
0000528C: SUB 01F360C0 ( temp SSA int ), 01F36060 ( temp SSA int ), 01F36090 ( temp SSA int )
0000528C: DELETE 01F36090 ( temp SSA int )
0000528C: DELETE 01F36060 ( temp SSA int )
0000528E: ADD 02102910 ( merged int ), 01F36000 ( temp SSA int ), 01F360C0 ( temp SSA int )
0000528E: DELETE 01F360C0 ( temp SSA int )
0000528E: DELETE 01F36000 ( temp SSA int )
000052B8: ACTION 000C (4) 02102910 ( merged int ), 01F361E0 ( merged const int ), 01F36180 ( merged const int ), 01F36120 ( merged const int )
000052CB: CREATE 01F36300 ( temp SSA int )
000052CB: LT 01F36300 ( temp SSA int ), 02102910 ( merged int ), 01F362A0 ( merged const int )
000052CD: TEST 01F36300 ( temp SSA int )
000052CD: DELETE 01F36300 ( temp SSA int )
000052CD: JZ 000052F7For those keeping score, that's 17 instructions in the original bytecode, 43 in the raw intermediate code (26 that are create or destroy, 9 that are assigns to temporary variables), and 19 in the optimized intermediate code (10 that are create or destroy; if that still sounds like too many, note that all of those variables will be converted to registers in LLVM).
Monday, August 02, 2010
& NWScript
The attentive might have wondered why I bothered to spend a moderate amount of timewriting about a topic I'd already moved past, which is kind of uncharacteristic of me. As I said before, I had looked at LLVM for a couple days a couple weeks prior to the corresponding blog post, then moved on (I can't recall if there was anything in between LLVM and cache-oblivious algorithms).
Well, part of the reason I didn't spend too much time on LLVM was because while it's neat, I didn't have an immediate use for it. However, a few days before I wrote said post Skywing randomly came up to me and asked if I wanted to write a native code compiler for NWScript, the scripting language in NeverWinter Nights 1 and 2, for the client and server he's been writing. Suddenly I had an immediate and interesting use for LLVM.
NWScript (for more information see this) is a language based on C, and supports a subset of the features. It supports only a small number of data types: int, float, string, and a number of opaque types that are more or less handles to game structures accessed solely via APIs. It also supports user-defined structures, including the built-in type vector (consisting of 3 floats), though it does not support arrays, pointers, etc. All variables and functions are strongly typed, although some game objects - those referred to with handles, such as the "object" type - may not be fully described by their scripting type. NWScript has a special kind of callback pointer called an action (a term which, confusingly, has at least two additional meanings in NWScript), which is more or less a deferred function call that may be invoked in the future - specifically, by the engine - and consists of a function pointer and the set of arguments to pass to that function (a call to an action takes no parameters from the caller itself).
NWScript is compiled by the level editor into a bytecode that is interpreted by a virtual machine within the games. Like the Java and .NET VMs, the VM for NWScript is a stack system, where a strongly-typed stack is used for opcode and function parameters and return values. Parameters to assembly instructions, as with function calls, are pushed on the top of the stack, and instructions and function calls pop the parameters and, if there is one, push the result/return value onto the top of the stack. Data down the stack is copied to the top of the stack with load operations, and copied from the top of the stack to locations further down by store operations.
Unlike those VMs, however, NWScript uses a pure, integrated stack system, implementing global and local variables through the stack, as well. Global variables are accessed through instructions that load/store values at indices relative to the global variable pointer BP, which is an index into the stack. Normally, global variables are at the very bottom of the stack, pushed in a wrapper function called #globals before the script's main function is called; there are opcodes to alter BP, though this is not known to ever be used. Local variables are accessed by loads and stores relative to the top of the stack, just as with the x86 (ignoring the CPU registers). Unlike the x86, however, return addresses are not kept on the stack, but like Itanium are maintained in a separate, program-inaccessible stack.
Oh, and for those wondering, the Java and .NET VMs have separate mechanisms for global and local variables that do not use the stack. This is actually rather surprising - you would expect them to use the stack at least for local variables, as actual processor architectures do (when they run out of registers to assign).
The following show a couple random pieces of NWScript bytecode with some comments:
You might notice that Skywing has started a series of his own on the project, today. I actually wrote this post several weeks ago, but was waiting until the project was done to post about it. But now that it looks like he's gonna cover it, I need to start posting or I'll end up posting after him despite starting before him.
Well, part of the reason I didn't spend too much time on LLVM was because while it's neat, I didn't have an immediate use for it. However, a few days before I wrote said post Skywing randomly came up to me and asked if I wanted to write a native code compiler for NWScript, the scripting language in NeverWinter Nights 1 and 2, for the client and server he's been writing. Suddenly I had an immediate and interesting use for LLVM.
NWScript (for more information see this) is a language based on C, and supports a subset of the features. It supports only a small number of data types: int, float, string, and a number of opaque types that are more or less handles to game structures accessed solely via APIs. It also supports user-defined structures, including the built-in type vector (consisting of 3 floats), though it does not support arrays, pointers, etc. All variables and functions are strongly typed, although some game objects - those referred to with handles, such as the "object" type - may not be fully described by their scripting type. NWScript has a special kind of callback pointer called an action (a term which, confusingly, has at least two additional meanings in NWScript), which is more or less a deferred function call that may be invoked in the future - specifically, by the engine - and consists of a function pointer and the set of arguments to pass to that function (a call to an action takes no parameters from the caller itself).
NWScript is compiled by the level editor into a bytecode that is interpreted by a virtual machine within the games. Like the Java and .NET VMs, the VM for NWScript is a stack system, where a strongly-typed stack is used for opcode and function parameters and return values. Parameters to assembly instructions, as with function calls, are pushed on the top of the stack, and instructions and function calls pop the parameters and, if there is one, push the result/return value onto the top of the stack. Data down the stack is copied to the top of the stack with load operations, and copied from the top of the stack to locations further down by store operations.
Unlike those VMs, however, NWScript uses a pure, integrated stack system, implementing global and local variables through the stack, as well. Global variables are accessed through instructions that load/store values at indices relative to the global variable pointer BP, which is an index into the stack. Normally, global variables are at the very bottom of the stack, pushed in a wrapper function called #globals before the script's main function is called; there are opcodes to alter BP, though this is not known to ever be used. Local variables are accessed by loads and stores relative to the top of the stack, just as with the x86 (ignoring the CPU registers). Unlike the x86, however, return addresses are not kept on the stack, but like Itanium are maintained in a separate, program-inaccessible stack.
Oh, and for those wondering, the Java and .NET VMs have separate mechanisms for global and local variables that do not use the stack. This is actually rather surprising - you would expect them to use the stack at least for local variables, as actual processor architectures do (when they run out of registers to assign).
The following show a couple random pieces of NWScript bytecode with some comments:
; Allocate int and object local variables on the stackStack systems - especially this one, where everything is held on the stack - make for VMs that are very simple and easy to implement, and Merlin told me in the past that they're easy to compile to native code, as well. So it's not surprising that the developers used this architecture for NWScript.
0000007F 02 03 RSADDI
00000081 02 06 RSADDO
; Push parameter 0
00000083 04 06 00000000 CONSTO 00000000
; Call game API function
00000089 05 00 0360 01 ACTION GetControlledCharacter(0360), 01
; Copy return value to the object local variable
0000008E 01 01 FFFFFFF8 0004 CPDOWNSP FFFFFFF8, 0004
; Pop the return value
00000096 1B 00 FFFFFFFC MOVSP FFFFFFFC
; Allocate float on stack
00000015 02 04 RSADDF
; Incredibly stupid way of setting the float to 3.0f
00000017 04 04 40400000 CONSTF 3.000000
0000001D 01 01 FFFFFFF8 0004 CPDOWNSP FFFFFFF8, 0004
00000025 1B 00 FFFFFFFC MOVSP FFFFFFFC
; Assign the current stack frame to BP
0000002B 2A 00 SAVEBP
; Call main()
0000002D 1E 00 00000010 JSR fn_0000003D
; Restore BP to what it was before (not that it was anything)
00000033 2B 00 RESTOREBP
; Clean up the global variables
00000035 1B 00 FFFFFFFC MOVSP FFFFFFFC
0000003B 20 00 RETN
; Push last two parameters to FloatToString
0000043C 04 03 00000009 CONSTI 00000009
00000442 04 03 00000012 CONSTI 00000012
; Divide 5.0f by 2.0f
00000448 04 04 40A00000 CONSTF 5.000000
0000044E 04 04 40000000 CONSTF 2.000000
00000454 17 21 DIVFF
; Return value of DIVFF is the first parameter to FloatToString
00000456 05 00 0003 03 ACTION FloatToString(0003), 03
; Return value is second parameter to SendMessageToPC. Push first parameter.
0000045B 04 06 00000000 CONSTO 00000000
00000461 05 00 0176 02 ACTION SendMessageToPC(0176), 02
You might notice that Skywing has started a series of his own on the project, today. I actually wrote this post several weeks ago, but was waiting until the project was done to post about it. But now that it looks like he's gonna cover it, I need to start posting or I'll end up posting after him despite starting before him.
Monday, June 28, 2010
Sunday, June 27, 2010
& LLVM
A few weeks ago - before I got into cache-oblivious algorithms - I briefly had a different topic du jour. In particular, I had just learned about Low-Level Virtual Machine, and spent a couple days researching that.
LLVM is a bit hard to explain, because the boundary around what it is is rather fuzzy. To sum it up in a noun phrase, I'd say that LLVM is a modular compilation system and virtual machine. I say "compilation system" because it doesn't really consist of an actual compiler, and there's a lot of it that is outside the definition of a compiler.
The core idea is that you have a program in some programming language which is compiled into a platform and language independent intermediate format. From there, the program is translated into some machine code (whatever type is used on the machine it's being run on) at a later time, either during execution (just-in-time compiling) or prior to execution (e.g. an installer converting the application to native code when the program is installed), and executed. In that sense there's some similarity to the .NET platform and Java platform, though it isn't totally analogous to those.
LLVM is a collection of modules that makes the various parts of the process possible. These components form a redundant superset of a full system, so you can choose which you want for a particular purpose and leave the rest.
Going chronologically through that process, the first module in LLVM is its assembler. LLVM does not directly parse and compile any particular programming language. When creating a working compiler, you must create a language parser that processes a program and performs any language-specific optimizations. LLVM takes as its input a program in LLVM assembly plus various metadata that could be useful later in the process, and assembles them into language and platform independent LLVM intermediate bytecode. A few of the open-source parsers already available for LLVM include C, C++, Objective-C, and many others; there are even parsers under development that take .NET and Java bytecodes as input.
The LLVM assembly language differs substantially from the Java and .NET bytecode languages, and bears some resemblance to RISC assembly languages such as MIPS and PPC. LLVM assembly consists of an infinite set of Single Static Assignment (SSA) registers; each register can be assigned only once, and a new register must be allocated for the result of every computation. However, LLVM also stores a significant amount of metadata, such as call graphs and other things at a higher level than a simple assembly language, in the bytecode (language-dependent metadata provided by the compiler is also stored for later use by language-dependent modules, e.g. if a particular language has a runtime environment that needs more information than just the native code). This combination of the assembly language design and rich metadata allows the optimizer and native code generator to act much more effectively, in a language-independent manner, than if they were working on a bare assembly language. Yet they are compact enough to not be significantly larger than the equivalent native code alone.
The next step in the process is global optimization. LLVM implements a substantial number of language-independent optimization algorithms, and compiler writers can use some or all of them as they like. Because of the metadata stored with the assembly language, LLVM is not limited to dealing simply with assembly, and the effectiveness of it's optimization algorithms resembles that of a standalone compiler (e.g. Visual C++). Even better, because optimization occurs after the entire program has been assembled, LLVM can do whole-program optimizations (known as link-time code generation in VC++ and others) that are outside the ability of simple compilers that only look at a function or a source module at a time.
After optimization comes native code generation (or, alternately, you could interpret the bytecode without producing native code). This step takes the assembly and metadata that has undergone language and platform independent optimization and creates executable machine code, usually after performing platform-specific optimizations, and the code is then executed. Native code generators are language-independent, interchangeable modules invoked by LLVM and, given a program in LLVM bytecode, native code can be generated for any platform that a native code generation module exists for (x86 and PPC are a couple that are already supported with open-source implementations).
Finally, LLVM provides a runtime system that allows for various runtime tasks to be performed. We'll get to the other tasks later, but one to mention here is that this runtime system allows language or platform specific runtime environments to interface with LLVM-generated native code, as well as interfacing with system or dynamic link libraries. Language-dependent metadata provided by the language compiler in the distant past is also available for use here.
So, that's the basic process. However, as I've been describing the logical process and not the details, this description is much more linear than reality. As was mentioned, LLVM provides a number of modules that may be optionally used, and some are redundant. As well, there's also flexibility in how the modules interact.
LLVM especially provides a great deal of flexibility in the timing of optimization and native code generation. While LLVM can be used like a normal compiler, taking in LLVM assembly and generating an executable with native code that can be directly executed on the target platform, it does not need to be. It's equally possible to store the LLVM bytecode in a platform-independent "executable" and optimize it and compile it to native code at a later point, either on execution or prior to execution. LLVM can even compile individual functions to native code the first time they are called, allowing some portions of the program to potentially never be compiled at all.
Finally, LLVM also supports profiling and dynamic recompilation of a program. The LLVM runtime is capable of profiling the native code of the program at runtime, determining where the program spends most of its time, what functions are executed most often, etc. based on actual usage. It can then recompile the program from bytecode, either between executions or during idle time, using this profile data to perform optimizations based on actual usage.
So, that's squishy. But why should you care? Well, a few reasons. Probably the most attractive is that you can make a full, optimizing compiler for a language that will generate native code for many platforms simply by writing a parser and LLVM assembly generator - thousands of lines of code compared to hundreds of thousands or millions (see here for one example of this). Alternately, if you're designing a processor for some reason (work, school, or hobby), you can write a native code generator and instantly support all the languages parsers already exist for. And then there are some less obvious uses, such as using the metadata generated by LLVM to perform complex analysis of source code for the purpose of searching for bugs, security holes, etc.
LLVM is a free open-source project that may be used in free or commercial projects, open-source or proprietary. Its largest benefactor is Apple, who uses it extensively. Other companies such as Adobe also use it in various ways. For more information, see this brief summary of the LLVM system, and the LLVM web page.
LLVM is a bit hard to explain, because the boundary around what it is is rather fuzzy. To sum it up in a noun phrase, I'd say that LLVM is a modular compilation system and virtual machine. I say "compilation system" because it doesn't really consist of an actual compiler, and there's a lot of it that is outside the definition of a compiler.
The core idea is that you have a program in some programming language which is compiled into a platform and language independent intermediate format. From there, the program is translated into some machine code (whatever type is used on the machine it's being run on) at a later time, either during execution (just-in-time compiling) or prior to execution (e.g. an installer converting the application to native code when the program is installed), and executed. In that sense there's some similarity to the .NET platform and Java platform, though it isn't totally analogous to those.
LLVM is a collection of modules that makes the various parts of the process possible. These components form a redundant superset of a full system, so you can choose which you want for a particular purpose and leave the rest.
Going chronologically through that process, the first module in LLVM is its assembler. LLVM does not directly parse and compile any particular programming language. When creating a working compiler, you must create a language parser that processes a program and performs any language-specific optimizations. LLVM takes as its input a program in LLVM assembly plus various metadata that could be useful later in the process, and assembles them into language and platform independent LLVM intermediate bytecode. A few of the open-source parsers already available for LLVM include C, C++, Objective-C, and many others; there are even parsers under development that take .NET and Java bytecodes as input.
The LLVM assembly language differs substantially from the Java and .NET bytecode languages, and bears some resemblance to RISC assembly languages such as MIPS and PPC. LLVM assembly consists of an infinite set of Single Static Assignment (SSA) registers; each register can be assigned only once, and a new register must be allocated for the result of every computation. However, LLVM also stores a significant amount of metadata, such as call graphs and other things at a higher level than a simple assembly language, in the bytecode (language-dependent metadata provided by the compiler is also stored for later use by language-dependent modules, e.g. if a particular language has a runtime environment that needs more information than just the native code). This combination of the assembly language design and rich metadata allows the optimizer and native code generator to act much more effectively, in a language-independent manner, than if they were working on a bare assembly language. Yet they are compact enough to not be significantly larger than the equivalent native code alone.
The next step in the process is global optimization. LLVM implements a substantial number of language-independent optimization algorithms, and compiler writers can use some or all of them as they like. Because of the metadata stored with the assembly language, LLVM is not limited to dealing simply with assembly, and the effectiveness of it's optimization algorithms resembles that of a standalone compiler (e.g. Visual C++). Even better, because optimization occurs after the entire program has been assembled, LLVM can do whole-program optimizations (known as link-time code generation in VC++ and others) that are outside the ability of simple compilers that only look at a function or a source module at a time.
After optimization comes native code generation (or, alternately, you could interpret the bytecode without producing native code). This step takes the assembly and metadata that has undergone language and platform independent optimization and creates executable machine code, usually after performing platform-specific optimizations, and the code is then executed. Native code generators are language-independent, interchangeable modules invoked by LLVM and, given a program in LLVM bytecode, native code can be generated for any platform that a native code generation module exists for (x86 and PPC are a couple that are already supported with open-source implementations).
Finally, LLVM provides a runtime system that allows for various runtime tasks to be performed. We'll get to the other tasks later, but one to mention here is that this runtime system allows language or platform specific runtime environments to interface with LLVM-generated native code, as well as interfacing with system or dynamic link libraries. Language-dependent metadata provided by the language compiler in the distant past is also available for use here.
So, that's the basic process. However, as I've been describing the logical process and not the details, this description is much more linear than reality. As was mentioned, LLVM provides a number of modules that may be optionally used, and some are redundant. As well, there's also flexibility in how the modules interact.
LLVM especially provides a great deal of flexibility in the timing of optimization and native code generation. While LLVM can be used like a normal compiler, taking in LLVM assembly and generating an executable with native code that can be directly executed on the target platform, it does not need to be. It's equally possible to store the LLVM bytecode in a platform-independent "executable" and optimize it and compile it to native code at a later point, either on execution or prior to execution. LLVM can even compile individual functions to native code the first time they are called, allowing some portions of the program to potentially never be compiled at all.
Finally, LLVM also supports profiling and dynamic recompilation of a program. The LLVM runtime is capable of profiling the native code of the program at runtime, determining where the program spends most of its time, what functions are executed most often, etc. based on actual usage. It can then recompile the program from bytecode, either between executions or during idle time, using this profile data to perform optimizations based on actual usage.
So, that's squishy. But why should you care? Well, a few reasons. Probably the most attractive is that you can make a full, optimizing compiler for a language that will generate native code for many platforms simply by writing a parser and LLVM assembly generator - thousands of lines of code compared to hundreds of thousands or millions (see here for one example of this). Alternately, if you're designing a processor for some reason (work, school, or hobby), you can write a native code generator and instantly support all the languages parsers already exist for. And then there are some less obvious uses, such as using the metadata generated by LLVM to perform complex analysis of source code for the purpose of searching for bugs, security holes, etc.
LLVM is a free open-source project that may be used in free or commercial projects, open-source or proprietary. Its largest benefactor is Apple, who uses it extensively. Other companies such as Adobe also use it in various ways. For more information, see this brief summary of the LLVM system, and the LLVM web page.
Wednesday, June 23, 2010
& Cache-Oblivious Algorithms (Updated)
Hey, does anybody remember the days when I actually wrote stuff on this blog? Those were good times.
Well, in case anybody actually remembers that far back, one of the things I'm known for is my topic du jour manner of self-education. I hear about some topic (or it comes up in some thought process), I research it for anywhere from a few days to a few months (however long it holds my interest), then I move on to some other topic. This week's topic du jour is cache-oblivious algorithms.
To explain what cache-oblivious algorithms are and why they're good, let's work through an example.
Suppose we've got a sorted array of 2^24 32-bit values, for a total size of 64 MB, and we need to determine if it contains a given value (if not, to find the nearest values). As we know that the list is sorted, binary search is the obvious choice, as it's known to be O(log N) complexity; note also that a sorted array is effectively an implicit binary search tree with items stored in-order, and the binary search is just a traversal of that tree. This complexity dictates that the search will require approximately log2(2^24) = 24 comparisons, each by definition involving a memory access (obviously, as the array is stored in memory).
Now consider a similar array containing 2^8 32-bit values (total size of 1 KB). According to the big O, a search through this array will take about 8 comparisons - 1/3 as many as the 2^24 array. Now, while these two numbers are accurate, they're highly misleading. By that measure, you'd expect it to take three times as long to perform the 2^24 search as the 2^8. It doesn't. In fact, the difference is well over an order of magnitude.
The reason for this discrepancy is the assumption that all memory accesses are equal. This is invalidated by the existence of processor (and other) caching, where cache hits are significantly faster than cache misses, as well as Non-Uniform Memory Architectures, where different memory banks have different access times for different processors. The 1 KB array can easily be held entirely in the processor's L1 cache, and in theory all accesses will be cache hits. The 64 MB array, on the other hand, can't even be held in L2 or L3 cache, so most memory accesses will be cache misses, and must go all the way to main memory.
Of course, main memory isn't that extreme of an example, as it isn't too much slower than processor cache. The real killer is when you have something (e.g. a database) that can't be held entirely in memory, and must be read from disk as needed (or worse, accessed over the internet at a speed that makes hard disks look fast). Hard drives are about a million times slower than RAM, meaning that each and every disk access is an excruciating performance hit, and the internet can be an order of magnitude worse.
Unsurprisingly, a massive amount of research effort over the last half a century has been in minimizing that amount that must be read from disk, especially in the class of cache-aware algorithms. Cache-aware algorithms are algorithms that are tuned (typically parametrized) for a specific system configuration (e.g. cache size) to achieve performance superior to algorithms that don't take such configuration into consideration.
One of the most common cache-aware algorithms, used in most file systems and database structures, is the B-tree (and family members), an upside-down (non-binary) search tree designed to minimize the number of disk accesses in searching data sets too large to fit entirely into memory. The B-tree is cache-aware because the block size can be adjusted to perform optimally on a given system configuration through either abstract math or actual benchmarks, and the optimal size for one configuration may perform poorly on another configuration.
Surprisingly, only in the last decade have people seriously investigated whether it is possible to create algorithms that make optimal use of a system configuration regardless of what exactly that configuration is, with no parametrization. This type of algorithm is called cache-oblivious algorithms.
Sometimes this is easy. A sequential scan of an array that does something on every element in order is cache-oblivious because it produces the provably minimum number of cache misses regardless of how the cache works. Divide and conquer algorithms that access each item in an array are also generally cache-oblivious and provably optimal because they ultimately divide enough to operate only on what's in a single cache line, regardless of what size the cache line is, before moving on to the next cache line (assuming, of course, that the size of each element is small in relation to the size of a cache line); in other words, they have a more or less linear scanning memory access pattern.
Binary search, however, is not cache-oblivious, as it's not a true divide and conquer algorithm in the sense that matters to us; specifically, it does not access all elements, and therefore does not get to take advantage of the predominant locality in the array. However, we can make a cache-oblivious implicit binary search tree by changing the ordering of items. To maximize performance, we want to lay out the nodes of the binary tree such that child nodes are as close as possible to their parents as often as possible, resulting in a minimal number of cache misses.
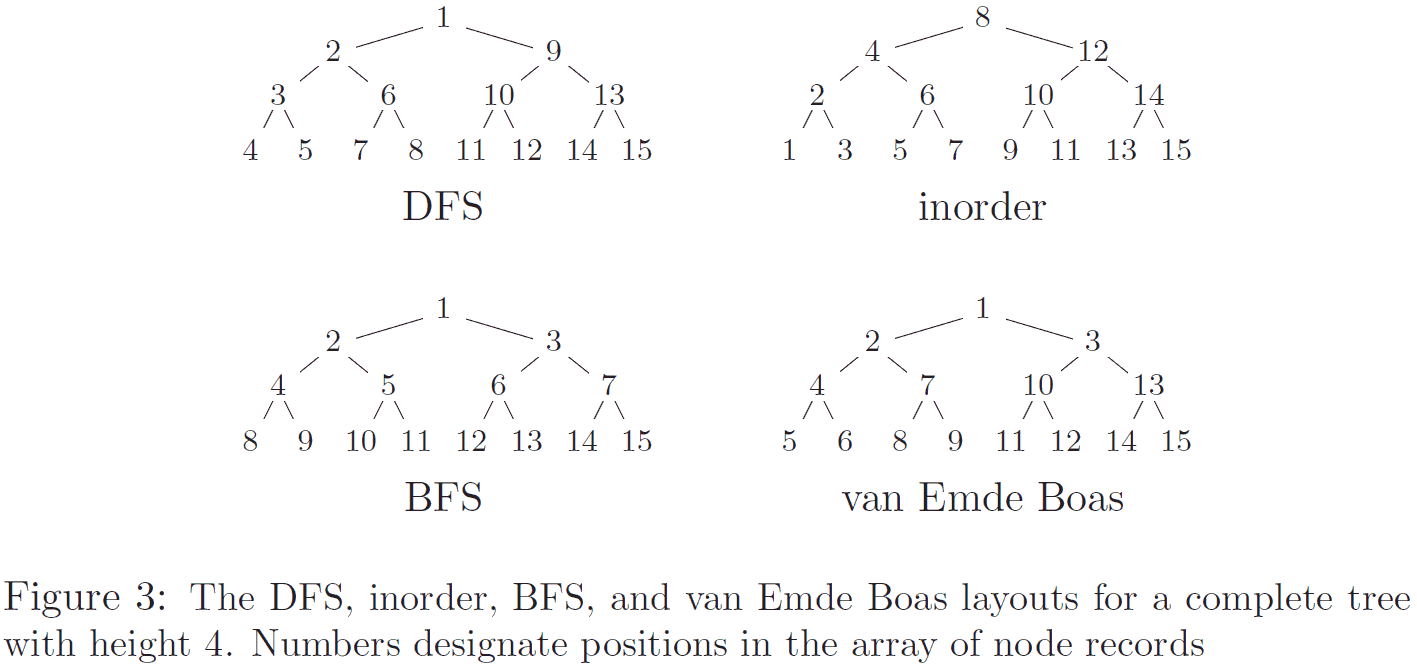
The key here is what's called the van Emde Boas layout (VEB) (you can tell I use HTTPS Everywhere because my Wikipedia links are all HTTPS). The basic idea is that the (triangular when drawn on paper) tree is divided recursively into (triangular) subtrees, with all nodes in each subtree being clustered together. This gives it a fractal structure with child and parent nodes being as close as possible to each other, maximizing cache locality during searches without needing to know the details of the cache system. A short tree in this form is shown below; below that is a comparison with trees in in-order, breadth-first (BFS), and depth-first search (DFS):


It's worth noting that cache-oblivious structures may or may not be as fast/faster than the simpler forms when the entire data set is in the same level of cache (whether you're talking about L1, RAM, etc.). One of the papers (the same one the images are from) examined the performance of static (non-changing) binary trees stored in in-order, BFS (an order that gives some cache locality while still being trivial to calculate child positions for), DFS, and VEB order, as well as two cache-aware search tree formats. In this experiment, the tree was stored in memory and cached in the processor cache - cache hits stay in the processor, cache misses go to main memory.
In the case of VEB, the complex fractal structure makes it nontrivial to calculate the position of a node's children in the array. As a result, when the entire data structure is in cache, calculation of child position takes longer than memory accesses, and VEB is about 40% slower than the standard in-order ordering. VEB begins to outperform in-order ordering once about half of the tree does not fit into cache; this calculation complexity problem can be overcome by storing child pointers with each node, but this is rather self-defeating, as this only multiplies the amount of data that has to be fit into the limited cache. In almost all cases, the cache-aware algorithms were superior to the others, but obviously require tuning to the particular cache, which is exactly what we're trying to avoid. BFS also performed admirably, always at least 15% faster than in-order ordering, and superior to VEB when more than ~1.5% of the data was able to fit into cache.
Another article compared a cache-oblivious binary heap based on VEB ordering with a standard binary heap using BFS ordering, in the context of a real-world internet page cache in actual use. Here, the heap is stored on (solid state) disk and cached in memory - cache hits go to memory while cache misses go to the disk. As in the previous benchmark, VEB performed 30% worse than the standard BFS when the entire tree could be stored in cache, but outperformed BFS when more than 0.2% of the tree was not stored in memory (I would guess this threshold is so low due to the many order of magnitude difference between memory and disk performance). At the other end, VEB peaked at 10x the speed of BFS when most of the tree was not cached. I imagine the reason this wasn't much higher was that in this real-world benchmark the priority queue was very small relative to the other data that is being accessed, and as such performance was dominated by other operations.
In the ~10 years researchers have been working on this, an array of cache-oblivious algorithms have been described, such as searching, sorting, linked lists, heaps, matrix multiplication and transposition, and various geometric algorithms such as 3D bounding volumes. The list of stuff I've seen so far (though not necessarily read through completely) is shown below, though I'm certain there are other things out there as well.
Cache-Efficient Layouts of Bounding Volume Hierarchies [and space partitioning]
Cache-Oblivious Algorithms (overview and survey)
Cache-Oblivious Algorithms and Data Structures (overview and survey)
Cache Oblivious Distribution Sweeping (sorting and various geometric algorithms)
Cache-Oblivious Dynamic Search Trees
Cache-Oblivious Priority Queue and Graph Algorithm Applications
Cache Oblivious Search Trees via Binary Trees of Small Height
You're Doing It Wrong (overview and heap algorithm applied to a real-life internet cache program)
Well, in case anybody actually remembers that far back, one of the things I'm known for is my topic du jour manner of self-education. I hear about some topic (or it comes up in some thought process), I research it for anywhere from a few days to a few months (however long it holds my interest), then I move on to some other topic. This week's topic du jour is cache-oblivious algorithms.
To explain what cache-oblivious algorithms are and why they're good, let's work through an example.
Suppose we've got a sorted array of 2^24 32-bit values, for a total size of 64 MB, and we need to determine if it contains a given value (if not, to find the nearest values). As we know that the list is sorted, binary search is the obvious choice, as it's known to be O(log N) complexity; note also that a sorted array is effectively an implicit binary search tree with items stored in-order, and the binary search is just a traversal of that tree. This complexity dictates that the search will require approximately log2(2^24) = 24 comparisons, each by definition involving a memory access (obviously, as the array is stored in memory).
Now consider a similar array containing 2^8 32-bit values (total size of 1 KB). According to the big O, a search through this array will take about 8 comparisons - 1/3 as many as the 2^24 array. Now, while these two numbers are accurate, they're highly misleading. By that measure, you'd expect it to take three times as long to perform the 2^24 search as the 2^8. It doesn't. In fact, the difference is well over an order of magnitude.
The reason for this discrepancy is the assumption that all memory accesses are equal. This is invalidated by the existence of processor (and other) caching, where cache hits are significantly faster than cache misses, as well as Non-Uniform Memory Architectures, where different memory banks have different access times for different processors. The 1 KB array can easily be held entirely in the processor's L1 cache, and in theory all accesses will be cache hits. The 64 MB array, on the other hand, can't even be held in L2 or L3 cache, so most memory accesses will be cache misses, and must go all the way to main memory.
Of course, main memory isn't that extreme of an example, as it isn't too much slower than processor cache. The real killer is when you have something (e.g. a database) that can't be held entirely in memory, and must be read from disk as needed (or worse, accessed over the internet at a speed that makes hard disks look fast). Hard drives are about a million times slower than RAM, meaning that each and every disk access is an excruciating performance hit, and the internet can be an order of magnitude worse.
Unsurprisingly, a massive amount of research effort over the last half a century has been in minimizing that amount that must be read from disk, especially in the class of cache-aware algorithms. Cache-aware algorithms are algorithms that are tuned (typically parametrized) for a specific system configuration (e.g. cache size) to achieve performance superior to algorithms that don't take such configuration into consideration.
One of the most common cache-aware algorithms, used in most file systems and database structures, is the B-tree (and family members), an upside-down (non-binary) search tree designed to minimize the number of disk accesses in searching data sets too large to fit entirely into memory. The B-tree is cache-aware because the block size can be adjusted to perform optimally on a given system configuration through either abstract math or actual benchmarks, and the optimal size for one configuration may perform poorly on another configuration.
Surprisingly, only in the last decade have people seriously investigated whether it is possible to create algorithms that make optimal use of a system configuration regardless of what exactly that configuration is, with no parametrization. This type of algorithm is called cache-oblivious algorithms.
Sometimes this is easy. A sequential scan of an array that does something on every element in order is cache-oblivious because it produces the provably minimum number of cache misses regardless of how the cache works. Divide and conquer algorithms that access each item in an array are also generally cache-oblivious and provably optimal because they ultimately divide enough to operate only on what's in a single cache line, regardless of what size the cache line is, before moving on to the next cache line (assuming, of course, that the size of each element is small in relation to the size of a cache line); in other words, they have a more or less linear scanning memory access pattern.
Binary search, however, is not cache-oblivious, as it's not a true divide and conquer algorithm in the sense that matters to us; specifically, it does not access all elements, and therefore does not get to take advantage of the predominant locality in the array. However, we can make a cache-oblivious implicit binary search tree by changing the ordering of items. To maximize performance, we want to lay out the nodes of the binary tree such that child nodes are as close as possible to their parents as often as possible, resulting in a minimal number of cache misses.
The key here is what's called the van Emde Boas layout (VEB) (you can tell I use HTTPS Everywhere because my Wikipedia links are all HTTPS). The basic idea is that the (triangular when drawn on paper) tree is divided recursively into (triangular) subtrees, with all nodes in each subtree being clustered together. This gives it a fractal structure with child and parent nodes being as close as possible to each other, maximizing cache locality during searches without needing to know the details of the cache system. A short tree in this form is shown below; below that is a comparison with trees in in-order, breadth-first (BFS), and depth-first search (DFS):

It's worth noting that cache-oblivious structures may or may not be as fast/faster than the simpler forms when the entire data set is in the same level of cache (whether you're talking about L1, RAM, etc.). One of the papers (the same one the images are from) examined the performance of static (non-changing) binary trees stored in in-order, BFS (an order that gives some cache locality while still being trivial to calculate child positions for), DFS, and VEB order, as well as two cache-aware search tree formats. In this experiment, the tree was stored in memory and cached in the processor cache - cache hits stay in the processor, cache misses go to main memory.
In the case of VEB, the complex fractal structure makes it nontrivial to calculate the position of a node's children in the array. As a result, when the entire data structure is in cache, calculation of child position takes longer than memory accesses, and VEB is about 40% slower than the standard in-order ordering. VEB begins to outperform in-order ordering once about half of the tree does not fit into cache; this calculation complexity problem can be overcome by storing child pointers with each node, but this is rather self-defeating, as this only multiplies the amount of data that has to be fit into the limited cache. In almost all cases, the cache-aware algorithms were superior to the others, but obviously require tuning to the particular cache, which is exactly what we're trying to avoid. BFS also performed admirably, always at least 15% faster than in-order ordering, and superior to VEB when more than ~1.5% of the data was able to fit into cache.
Another article compared a cache-oblivious binary heap based on VEB ordering with a standard binary heap using BFS ordering, in the context of a real-world internet page cache in actual use. Here, the heap is stored on (solid state) disk and cached in memory - cache hits go to memory while cache misses go to the disk. As in the previous benchmark, VEB performed 30% worse than the standard BFS when the entire tree could be stored in cache, but outperformed BFS when more than 0.2% of the tree was not stored in memory (I would guess this threshold is so low due to the many order of magnitude difference between memory and disk performance). At the other end, VEB peaked at 10x the speed of BFS when most of the tree was not cached. I imagine the reason this wasn't much higher was that in this real-world benchmark the priority queue was very small relative to the other data that is being accessed, and as such performance was dominated by other operations.
In the ~10 years researchers have been working on this, an array of cache-oblivious algorithms have been described, such as searching, sorting, linked lists, heaps, matrix multiplication and transposition, and various geometric algorithms such as 3D bounding volumes. The list of stuff I've seen so far (though not necessarily read through completely) is shown below, though I'm certain there are other things out there as well.
Cache-Efficient Layouts of Bounding Volume Hierarchies [and space partitioning]
Cache-Oblivious Algorithms (overview and survey)
Cache-Oblivious Algorithms and Data Structures (overview and survey)
Cache Oblivious Distribution Sweeping (sorting and various geometric algorithms)
Cache-Oblivious Dynamic Search Trees
Cache-Oblivious Priority Queue and Graph Algorithm Applications
Cache Oblivious Search Trees via Binary Trees of Small Height
You're Doing It Wrong (overview and heap algorithm applied to a real-life internet cache program)
Tuesday, May 25, 2010
When Size Matters
I and another person, who is an IT professional, spent some time this weekend doing some volunteer work at a charity - more specifically, a homeless shelter and rehabilitation clinic, though any more details information isn't particularly relevant. Our task was to do "computer stuff", including basic maintenance on all their computers (those in the administration offices and those for use by residents), as well as take a look at what they had in storage.
While the computers available to residents weren't bad (about 5 years old or less), the situation in the office was more grim. Almost all of the computers were Pentium 3s and 4s, most with 256 megs of RAM and running Windows 2000 with Internet Explorer 6. That's right, Windows 2000 and IE6, which are both several years past end of life, and thus inherently insecure; oh, and did I mention that all the office staff run with admin privileges?
So, we started off with the easy stuff: chkdsk (full disk surface scan) and defrag on all of them. We intended to run virus scans on all of them, but were repeatedly thwarted by bad CD-ROM drives and stupid video cards that prevented us from using the AV boot disks I'd burned for the occasion (as I didn't trust the computers to not have rootkits), and eventually we had to resort on many computers to just running the AV from inside Windows.
While there were a few more specific problems with the computers, one universal complaint among the office staff was that the computers were anywhere from slow to extremely slow. While defrag no doubt helped a little with that (the computers were between 5 and 40% fragmented), the primary problem appeared to be something else entirely. Most of the computers had 256 megs of RAM, and on boot most of them were using anywhere from 210 to 260 megs of memory; add in 20 megs of memory for IE (I wanted to switch them to Firefox or a newer version of IE, but as both of those used significantly more memory that wasn't really an option), 30-40 megs for an Office app or two, and the observation that Windows starts disk-thrashing when you get to about 85% of physical memory used (about 220 megs), and it was clear that the computers were severely disk-thrashing.
So, memory upgrades were the obvious prescription. But that raises the question: why were the computers using so much memory to begin with? Anyone who remembers back from the day 10 years ago, including both myself and the other guy, can tell you that 256 megs should be plenty for Windows 2000 (and perhaps even XP). Given all the available evidence - that the computers ran Windows 2000 and IE6 in admin mode, our inability to do a proper virus scan on most of them, and the fact that there was a lot of unaccounted for memory (memory that was in use but not accounted for by running processes or kernel allocations) - naturally we assumed that they were severely infested with malware.
As irony would have it, the cause was actually just the opposite. On Sunday I finally got fed up with the situation, and decided to try a drastic experiment inspired with some experience in the past: I uninstalled the AVG Free antivirus that was on most of the computers. This experiment paid off; it turns out that AVG was in fact using a full 130 megs of memory. Without it, Windows was using about 80 megs of memory at boot, which is very much like what we remembered back from the day, when virus scanners took 30-40 megs, which would leave about 110 of the 256 megs available for running applications comfortably.
So... now what? Well, another 256 megs memory would put an end to the problem. But in the mean time, I had a stop-gap measure: get a smaller AV. Out of my previous tests on the best of the free AVs, the best current-generation AV in this regard was Avira AntiVir Personal, weighing in at about 95 megs. So, I switched all of the computers over to that. This reduced the amount of memory in use at boot to about 180 megs, leaving about 40 megs available for comfortably running applications. While that isn't a huge amount, I'm hoping that in a case this severe it will substantially improve performance until more memory can be acquired cheaply.
On that topic, I actually ordered a batch of used and very cheap 256 meg sticks off eBay, and I'm hoping to be able to test them out (which will take a couple days to thoroughly test this quantity of sticks) and get them installed this weekend or next, bringing the computers up to 512 megs; assuming, of course, that these computers (most of them Dells) aren't of the extremely finicky variety that reject all but very closely-matched memory. At 512 megs, it becomes reasonable to start looking at upgrading the computers to XP (pretty sure it wouldn't be a good idea to try Vista on those computers) and Firefox, which would go a long way to improving security (and, of course, at that point it would be worth making them not run as admin).
On one last note, one thing that continues to stump both of us is how on one computer the fonts in IE are enormous. On typical web pages lines of text are often 1-1.5 inches tall, making it extremely difficult to use the web. We both independently looked at both font settings and accessibility features in both IE and Windows, but none of those proved to be the cause. Setting fonts to smallest in IE made text more reasonable, but on some pages the text was actually "smallest", making it impossibly small to read; thus this was not a sufficient solution to the problem.
While the computers available to residents weren't bad (about 5 years old or less), the situation in the office was more grim. Almost all of the computers were Pentium 3s and 4s, most with 256 megs of RAM and running Windows 2000 with Internet Explorer 6. That's right, Windows 2000 and IE6, which are both several years past end of life, and thus inherently insecure; oh, and did I mention that all the office staff run with admin privileges?
So, we started off with the easy stuff: chkdsk (full disk surface scan) and defrag on all of them. We intended to run virus scans on all of them, but were repeatedly thwarted by bad CD-ROM drives and stupid video cards that prevented us from using the AV boot disks I'd burned for the occasion (as I didn't trust the computers to not have rootkits), and eventually we had to resort on many computers to just running the AV from inside Windows.
While there were a few more specific problems with the computers, one universal complaint among the office staff was that the computers were anywhere from slow to extremely slow. While defrag no doubt helped a little with that (the computers were between 5 and 40% fragmented), the primary problem appeared to be something else entirely. Most of the computers had 256 megs of RAM, and on boot most of them were using anywhere from 210 to 260 megs of memory; add in 20 megs of memory for IE (I wanted to switch them to Firefox or a newer version of IE, but as both of those used significantly more memory that wasn't really an option), 30-40 megs for an Office app or two, and the observation that Windows starts disk-thrashing when you get to about 85% of physical memory used (about 220 megs), and it was clear that the computers were severely disk-thrashing.
So, memory upgrades were the obvious prescription. But that raises the question: why were the computers using so much memory to begin with? Anyone who remembers back from the day 10 years ago, including both myself and the other guy, can tell you that 256 megs should be plenty for Windows 2000 (and perhaps even XP). Given all the available evidence - that the computers ran Windows 2000 and IE6 in admin mode, our inability to do a proper virus scan on most of them, and the fact that there was a lot of unaccounted for memory (memory that was in use but not accounted for by running processes or kernel allocations) - naturally we assumed that they were severely infested with malware.
As irony would have it, the cause was actually just the opposite. On Sunday I finally got fed up with the situation, and decided to try a drastic experiment inspired with some experience in the past: I uninstalled the AVG Free antivirus that was on most of the computers. This experiment paid off; it turns out that AVG was in fact using a full 130 megs of memory. Without it, Windows was using about 80 megs of memory at boot, which is very much like what we remembered back from the day, when virus scanners took 30-40 megs, which would leave about 110 of the 256 megs available for running applications comfortably.
So... now what? Well, another 256 megs memory would put an end to the problem. But in the mean time, I had a stop-gap measure: get a smaller AV. Out of my previous tests on the best of the free AVs, the best current-generation AV in this regard was Avira AntiVir Personal, weighing in at about 95 megs. So, I switched all of the computers over to that. This reduced the amount of memory in use at boot to about 180 megs, leaving about 40 megs available for comfortably running applications. While that isn't a huge amount, I'm hoping that in a case this severe it will substantially improve performance until more memory can be acquired cheaply.
On that topic, I actually ordered a batch of used and very cheap 256 meg sticks off eBay, and I'm hoping to be able to test them out (which will take a couple days to thoroughly test this quantity of sticks) and get them installed this weekend or next, bringing the computers up to 512 megs; assuming, of course, that these computers (most of them Dells) aren't of the extremely finicky variety that reject all but very closely-matched memory. At 512 megs, it becomes reasonable to start looking at upgrading the computers to XP (pretty sure it wouldn't be a good idea to try Vista on those computers) and Firefox, which would go a long way to improving security (and, of course, at that point it would be worth making them not run as admin).
On one last note, one thing that continues to stump both of us is how on one computer the fonts in IE are enormous. On typical web pages lines of text are often 1-1.5 inches tall, making it extremely difficult to use the web. We both independently looked at both font settings and accessibility features in both IE and Windows, but none of those proved to be the cause. Setting fonts to smallest in IE made text more reasonable, but on some pages the text was actually "smallest", making it impossibly small to read; thus this was not a sufficient solution to the problem.
Tuesday, May 04, 2010
What the
This one was a bit too long to post on Twitter. A quote from a link I tweeted:
Courts making rulings based on actual technical knowledge? What's this world coming to? I note that they even listened to me (okay, probably just other people with similar technical knowledge) and realized that content scanning would be ineffective as it would just lead to ubiquitous encryption with no actual reduction in infringement.
In addition, the appeals court took aim at several filtering schemes. Blocking all files of a certain type (such as RAR files) was deemed inappropriate, since a file type has no bearing on the legality of an upload. Scanning by IP address was also tossed, because numerous people can use a single IP address. File name filtering tells you nothing about the contents of a file, so that was tossed. Even content scanning was problematic, as the court noted that this would just lead to encrypted files. Besides, even if you could know that a file was copyrighted, it could still be a legal "private backup" not distributed to anyone else.
Courts making rulings based on actual technical knowledge? What's this world coming to? I note that they even listened to me (okay, probably just other people with similar technical knowledge) and realized that content scanning would be ineffective as it would just lead to ubiquitous encryption with no actual reduction in infringement.
Monday, May 03, 2010
Okay, I replaced the Twitter gadget from Blogger with the official Twitter one. It doesn't really visually match the blog, but all the ones that were available on Blogger had the same problem with links. This one doesn't.
Let me know if somebody knows one that matches visually without this problem.
Let me know if somebody knows one that matches visually without this problem.
& Bugs
Yikes. Somebody just made me aware that if you follow one of the links posted in my tweets on the sidebar, it opens the link in that little tweet frame. That's very buggy. I'll have to see if I can get Blogger (the one that created the Twitter thing) to fix that.
Friday, April 30, 2010
& Domain-Specific Computing
So, I went to the public lecture at UCI today (the one I posted an event for on my Facebook page). These public lectures are by various guest speakers on a wide range of topics; each one is usually something of an overview of a particular field, often ones which the average computer science student has minimal or no exposure to in their classes. As with last time, there were free brownies and coffee/tea.
Note that this post is all from memory. I didn't take notes or anything, so there are likely to be omissions and vagueness compared to the actual lecture.
The topic this time was domain-specific computing. Essentially this refers to the use of some manner of special-purpose hardware to offload work from a general-purpose CPU, either eliminating the CPU entirely or allowing the use of a smaller, cheaper, and more efficient CPU. The ultimate purpose of this is to reduce overall cost and power consumption while increasing overall performance for a given task.
If this doesn't sound revolutionary, it's because it's not. Modular electronics have been around for as long as electronics in total. If you want a real-world example of something built this way, you can look at just about anything at all. Computers consist of many components (e.g. motherboard, video card), each composed of many further components (GPU, southbridge, northbridge, etc.), usually microchips.
The problem then is that it's hard to manufacture these chips. It's expensive, requires skill in engineering, and is largely done manually. Skilled electrical engineers must manually design a circuit, then a huge fabrication plant uses big and very expensive machines to manufacture the circuit, which is then available for use in various devices. Because of the expense and manufacturing requirements, most companies are not able to produce custom chips in this way.
As a result, very common specialized circuits are produced and sold off-the-shelf in large quantities, while less general circuits instead use code running on a general-purpose CPU. After chip design and fabrication, another electric engineer must then analyze everything a particular device must do, determine where it would be beneficial to use specialized off-the-shelf components (which may either be used directly or require some manner of mapping to make the data fit the exact component), then determine which CPU to use for everything else, and have the programmers write the code for it.
Done correctly, the resulting device is faster, cheaper to manufacture, and more efficient than simply using a fast CPU to do everything. One of the papers he cited examined different algorithms implemented on a general-purpose CPU, a general-purpose GPU, and a custom FPGA (chips that can be programmed without massive fabrication plants, but are less efficient than standard fabricated chips). For one algorithm (seemingly a highly parallel one), the GPU performed 93x as well as the CPU, and the FPGA 11x. While the GPU was 8x as fast as the FPGA in absolute terms (though presumably you could increase the size of the FPGA 8 times, to match the GPU's total performance), when you compare performance:power consumption, the GPU was 60x that of the CPU, and the FPGA was about 220x: about 3.5x the performance of the GPU (and I'd wager the FPGA cost less than either of them). In other algorithms, the difference was tens of thousands of times.
But it's still a whole lot of work. Consequently, this tends to be done for mass-produced electronic devices, while more specialized things are simply executed on a common computer, as it's cheaper to code a program than engineer an electrical device.
This guy (the one who gave the lecture) is working to develop analysis and automation tools to reduce the cost and difficulty of custom hardware development, to significantly increase the range of things that are viable to produce this way. Ideally, you'd be able to write a specification or algorithm (e.g. a C++ program that describes an entire device's function), then automation would analyze the system, performing these steps (essentially the same ones I summarized above):
Actually, it looks like the slides from the lecture are available online for you to look at, beyond what I've already written about it.
Note that this post is all from memory. I didn't take notes or anything, so there are likely to be omissions and vagueness compared to the actual lecture.
The topic this time was domain-specific computing. Essentially this refers to the use of some manner of special-purpose hardware to offload work from a general-purpose CPU, either eliminating the CPU entirely or allowing the use of a smaller, cheaper, and more efficient CPU. The ultimate purpose of this is to reduce overall cost and power consumption while increasing overall performance for a given task.
If this doesn't sound revolutionary, it's because it's not. Modular electronics have been around for as long as electronics in total. If you want a real-world example of something built this way, you can look at just about anything at all. Computers consist of many components (e.g. motherboard, video card), each composed of many further components (GPU, southbridge, northbridge, etc.), usually microchips.
The problem then is that it's hard to manufacture these chips. It's expensive, requires skill in engineering, and is largely done manually. Skilled electrical engineers must manually design a circuit, then a huge fabrication plant uses big and very expensive machines to manufacture the circuit, which is then available for use in various devices. Because of the expense and manufacturing requirements, most companies are not able to produce custom chips in this way.
As a result, very common specialized circuits are produced and sold off-the-shelf in large quantities, while less general circuits instead use code running on a general-purpose CPU. After chip design and fabrication, another electric engineer must then analyze everything a particular device must do, determine where it would be beneficial to use specialized off-the-shelf components (which may either be used directly or require some manner of mapping to make the data fit the exact component), then determine which CPU to use for everything else, and have the programmers write the code for it.
Done correctly, the resulting device is faster, cheaper to manufacture, and more efficient than simply using a fast CPU to do everything. One of the papers he cited examined different algorithms implemented on a general-purpose CPU, a general-purpose GPU, and a custom FPGA (chips that can be programmed without massive fabrication plants, but are less efficient than standard fabricated chips). For one algorithm (seemingly a highly parallel one), the GPU performed 93x as well as the CPU, and the FPGA 11x. While the GPU was 8x as fast as the FPGA in absolute terms (though presumably you could increase the size of the FPGA 8 times, to match the GPU's total performance), when you compare performance:power consumption, the GPU was 60x that of the CPU, and the FPGA was about 220x: about 3.5x the performance of the GPU (and I'd wager the FPGA cost less than either of them). In other algorithms, the difference was tens of thousands of times.
But it's still a whole lot of work. Consequently, this tends to be done for mass-produced electronic devices, while more specialized things are simply executed on a common computer, as it's cheaper to code a program than engineer an electrical device.
This guy (the one who gave the lecture) is working to develop analysis and automation tools to reduce the cost and difficulty of custom hardware development, to significantly increase the range of things that are viable to produce this way. Ideally, you'd be able to write a specification or algorithm (e.g. a C++ program that describes an entire device's function), then automation would analyze the system, performing these steps (essentially the same ones I summarized above):
- Break it down into major functional units
- Determine which units can use off-the-shelf components and what the optimal component is
- Locate algorithms that would substantially benefit from the production of new components and then design those components for manufacturing, either using FPGAs, circuit boards, or as actual fabricated chips
- Choose the optimal CPU and algorithm for the tasks remaining (that aren't worth implementing in hardware) and write the code. Remember that different tasks run better or worse on different CPU architectures, so this step must find the best CPU for the given algorithm or rewrite the algorithm in a way that runs better on a more preferable (e.g. cheaper) CPU. For example, CPUs that lack branch prediction are cheaper and more energy-efficient, but perform poorly on algorithms that use a great deal of branching; however, depending on the task to be performed, an alternate algorithm might be able to perform the task with less branching.
- Design an optimal bus architecture for all the different electronic to communicate
- Identification of identical algorithm matches to existing circuits as well as partial matches that can work with some amount of data conversion
- Profiling of different matching circuits to determine which performs optimally on a given problem
- Determination of which algorithms would perform substantially better if implemented in custom hardware
- Conversion of procedures (e.g. C++ programs) to electronic schematics for manufacturing
- Profiling of different CPU architectures (e.g. x86 and ARM), models (e.g. i5 and i7), and variants (e.g. cache size, with or without optional subunits, etc.), to determine which is optimal for a given device, based on performance and cost
- Profiling of different bus architectures (e.g. mesh and crossbar) and configurations (e.g. number and size of channels) to determine what is optimal for a device
- Modularization for energy efficiency, to allow entire circuits to be shut off when they aren't in use (but others are)
Actually, it looks like the slides from the lecture are available online for you to look at, beyond what I've already written about it.
Friday, April 16, 2010
& MPQDraft and StarCraft 2
In the course of randomly wasting time today, I decided to go look at how MPQDraft is doing in terms of popularity, these days. I do that every so often, but it had been a few months since I last looked.
To my surprise, I noted a substantial spike in downloads: 50% more binary downloads and 100% more source downloads, beginning in February. It took me a second to realize the likely cause: SC2 going into beta mid-February. It's not clear to me whether people expect MPQDraft to work with SC2, or whether SC2 has inspired a more general revival in modding.
In any case - MPQDraft does not work with the SC2 beta. There are two reasons for this.
Part of why MPQDraft is so elegant is that it works in a game- and version-independent manner. This is possible because MPQDraft intercepts function calls between the games and the Storm DLL, the latter which contains the functions to access MPQs. This only works if Storm is dynamically linked to the game, in its own DLL. The SC2 beta statically links to Storm; the MPQ functions, as well as others, are incorporated directly into the game executable.
This means the current simple, elegant MPQDraft method will not work, period. The only way to deal with this problem, and to make MPQDraft work when the game statically links to Storm, is to directly locate the function addresses in the game, and include those addresses themselves in the MPQDraft DLL.
The problem with this is that it's game- and version-dependent. Every time a new patch comes out you'll have to wait until I or somebody else updates the function addresses before you can use MPQDraft on the new version. And this obviously requires somebody taking the time to manually locate the functions in every new version, from scratch.
So, that's in the "pain in the ass" class of problems. It also remains to be seen whether Blizzard intends to ship SC2 linked in this way, or if it will dynamically link to Storm in the release version.
The bigger problem is the fact that SC2 is online most of the time, including when you're playing single player (unless you specifically tell it to run in offline mode). Depending on how aggressively Blizzard performs its anti-cheating scans (which they've been doing since SC1), it's plausible that MPQDraft could be detected as a cheat, in which case you'd probably get your account banned.
That's the current state of MPQDraft and SC2.
To my surprise, I noted a substantial spike in downloads: 50% more binary downloads and 100% more source downloads, beginning in February. It took me a second to realize the likely cause: SC2 going into beta mid-February. It's not clear to me whether people expect MPQDraft to work with SC2, or whether SC2 has inspired a more general revival in modding.
In any case - MPQDraft does not work with the SC2 beta. There are two reasons for this.
Part of why MPQDraft is so elegant is that it works in a game- and version-independent manner. This is possible because MPQDraft intercepts function calls between the games and the Storm DLL, the latter which contains the functions to access MPQs. This only works if Storm is dynamically linked to the game, in its own DLL. The SC2 beta statically links to Storm; the MPQ functions, as well as others, are incorporated directly into the game executable.
This means the current simple, elegant MPQDraft method will not work, period. The only way to deal with this problem, and to make MPQDraft work when the game statically links to Storm, is to directly locate the function addresses in the game, and include those addresses themselves in the MPQDraft DLL.
The problem with this is that it's game- and version-dependent. Every time a new patch comes out you'll have to wait until I or somebody else updates the function addresses before you can use MPQDraft on the new version. And this obviously requires somebody taking the time to manually locate the functions in every new version, from scratch.
So, that's in the "pain in the ass" class of problems. It also remains to be seen whether Blizzard intends to ship SC2 linked in this way, or if it will dynamically link to Storm in the release version.
The bigger problem is the fact that SC2 is online most of the time, including when you're playing single player (unless you specifically tell it to run in offline mode). Depending on how aggressively Blizzard performs its anti-cheating scans (which they've been doing since SC1), it's plausible that MPQDraft could be detected as a cheat, in which case you'd probably get your account banned.
That's the current state of MPQDraft and SC2.
Sunday, April 11, 2010
On a tangentially-related note, I've also joined Twitter. This one I have a very specific purpose for: link spam (the stuff I formerly sent to friends on IM services and pasted into chat room). A place where I can simply link to interesting, funny, or otherwise linkable stuff I find online, without giving any commentary, and I can post stuff too insignificant or off-topic to clutter this blog with (although I may occasionally post short random thoughts, as well).
Those of you who think this blog has had entirely too little computer/programming stuff on it lately should check out my Twitter feed. While these days most of the stuff I think long and hard about (and blog about) is linguistics, the majority of the stuff I read online remains about computers, video games, and programming. So, expect the majority of my tweets to be on those topics, like this blog was, back before I became interested in linguistics.
There are several ways you can access my tweets. If you're on Twitter, you can simply follow me. If you're not, you can either see the mini-Twitter feed now on the blog sidebar, read the Twitter tab of my FaceBook page, or subscribe to the RSS version of my Twitter feed.
Those of you who think this blog has had entirely too little computer/programming stuff on it lately should check out my Twitter feed. While these days most of the stuff I think long and hard about (and blog about) is linguistics, the majority of the stuff I read online remains about computers, video games, and programming. So, expect the majority of my tweets to be on those topics, like this blog was, back before I became interested in linguistics.
There are several ways you can access my tweets. If you're on Twitter, you can simply follow me. If you're not, you can either see the mini-Twitter feed now on the blog sidebar, read the Twitter tab of my FaceBook page, or subscribe to the RSS version of my Twitter feed.
So, I joined Facebook.
Not much to say about it. It was purely for practical reasons (because an organization I'm with apparently now uses Facebook to communicate with their members with regard to things like meeting dates), so I'm not planning on doing too much with it. I'll take a look at the features and we'll see. If I can find a use for some part of it (that I actually care to use) I might use it for that; if not I'll just use it as a friend hub and one more way to find me on the internet.
Not much to say about it. It was purely for practical reasons (because an organization I'm with apparently now uses Facebook to communicate with their members with regard to things like meeting dates), so I'm not planning on doing too much with it. I'll take a look at the features and we'll see. If I can find a use for some part of it (that I actually care to use) I might use it for that; if not I'll just use it as a friend hub and one more way to find me on the internet.
Saturday, April 03, 2010
& Spring Anime Thoughts
Sooooo, exactly how much of that last post was real, and how much was April Fools? About half of it. RaptorIIC did indeed talk to me about the idea of making an anime blog, and the idea has come up again (and more seriously) with Random Curiosity closing. It's not true that we've actually (yet) decided to go for it, and the ecchi/hentai theme is definitely not true, either. And, ironically, the day after I wrote that post, RC announced that it might not be closing after all.
So, moving back into the real world, in this post I'll discuss some of the new series I might actually watch, this season. Of course this is all very tentative, as not even one episode of most of these have aired yet. What's more, many of them really fall into a "I'll take a look at it and see how it is" category, which isn't particularly informative. Again, the series summaries and pictures are coming from RC and THAT (although in this post they'll be quoted, so you can differentiate the summary from my own comments).
The premise of the series is very much like the "so moe I am gonna die" [what it actually got tagged on AniDB at one point] Nogizaka Haruka's Secret. So far this one doesn't seem as horrific as that series; perhaps this is due to this being a girls' series and that one being an ecchi guys' series, though shoujo series can (potentially) be horrific in their own way. This hasn't been the case in the first episode, but the first episode is pre-romance, which is where things could go downhill.
So, I'll definitely watch some more and see how it goes.
RC has covered episode 1. It's also been subbed by a group, though I haven't seen it, yet.
Basically, it's a pretty famous Chinese story (at least in that part of the world). For that reason I might check it out, although I must say that 52 episodes is a really large number for a series that may or may not be any good. One thing that could be interesting is that, as the series was produced by a Chinese company and originally aired in China, the series might be in Chinese, with Japanese subtitles.
I watched the first season of this, a couple seasons ago (I mentioned that it had a good ending song). It was fairly enjoyable, although it really had entirely too much moe; though obviously the guy who wrote the summary disagrees with that assessment. In either case, it's decently amusing, even if it can get on your nerves.
Oh, and in case anyone happens to be interested, RC has covered B Gata H Kei 1 (mentioned yesterday).
On a final note, both the Currently Watching section and the Introduction to Anime/List (which includes a list of almost all free-to-watch anime series I've seen) link on the sidebar are still live, and being updated as new series come out.
So, moving back into the real world, in this post I'll discuss some of the new series I might actually watch, this season. Of course this is all very tentative, as not even one episode of most of these have aired yet. What's more, many of them really fall into a "I'll take a look at it and see how it is" category, which isn't particularly informative. Again, the series summaries and pictures are coming from RC and THAT (although in this post they'll be quoted, so you can differentiate the summary from my own comments).
I'm not so sure about that picture, but the description sounds like it could be entertaining, and slice-of-life comedies (optionally with romance) are my bread and butter in anime, after all. The first episode aired last night (covered by both RC and THAT), and one of the (very) fast but good subbing groups already had it out, so I got a chance to see it. So far it looks pretty good, although you can't always count on the first episode of something being representative of a series, as the first episode usually forms the background of the main story.Kaichou wa Maid-sama! | 会長はメイド様!After only reading a glimpse of the premise and taking a look at the art style, I was already convinced that “The Student Council President is a Maid!” was my kind of show. Reading a bit of the shoujo manga only reaffirmed that thought, as it has everything I’d want in a romantic comedy. The story focuses on a girl who’s enrolled in an all-boys school that has recently turned co-ed, and worked her ass off to become the student council president so that she can change the bad habits in the still predominantly male school. She develops a tough exterior as a result and doesn’t particularly like men because of how her father walked out on her and her family, but works a part-time job at a maid cafe to make ends meet. The most popular guy in school stumbles onto her secret one day and she thinks she’s set up for a huge embarrassment, but he chooses to keep it a secret because he’s unknowingly infatuated with her.
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

The premise of the series is very much like the "so moe I am gonna die" [what it actually got tagged on AniDB at one point] Nogizaka Haruka's Secret. So far this one doesn't seem as horrific as that series; perhaps this is due to this being a girls' series and that one being an ecchi guys' series, though shoujo series can (potentially) be horrific in their own way. This hasn't been the case in the first episode, but the first episode is pre-romance, which is where things could go downhill.
So, I'll definitely watch some more and see how it goes.
One of the series I’m really looking forward to and can safely recommend to all audiences is Angel Beats. For some, it might be enough if I just say, “Key and P.A. Works.” For everyone else, this means the visual novel company that brought us AIR, CLANNAD, and Kanon, and the studio that produced true tears and CANAAN. Maeda Jun from Key is writing the script and screenplay, depicting an afterworld where one girl forms a war front, the Shinda Sekai Sensen (SSS), in defiance to god for giving her an unreasonable and short life. In this supernatural afterlife setting, we follow male protagonist Otonashi, who has no memories of when he was alive and gets dragged into the SSS’s struggles. Guns and superpowers are involved, but so is a seemingly normal school life at the same time.Key is a very well known maker of "dating sim" games. As mentioned in the summary, to date three of their games have been adapted into anime, and I've seen them all. The supernatural and fighting aspects are certainly different than any of previous ones, though it sounds as though it still has the school slice-of-life parts they're known for, as well. The three series so far have been at least enjoyable, so I'll probably end up watching this, also. It will be interesting to see how they do something less traditional dating sim.

RC has covered episode 1. It's also been subbed by a group, though I haven't seen it, yet.
Well, that isn't the most informative summary in the world. For more information, see the Wikipedia entry on the original Romance of the Three Kingdoms.And here it is, the fourth series this season with some basis on Romance of the Three Kingdoms, except this one’s meant to be the real deal, or at least Chinese studio Beijing Glorious Animation’s interpretation of it. It’s actually a joint production with Japan’s Takara Tomy and Future Planet (the first of its kind) in regards to both planning and animation production. So if you don’t care for the pretty girls seen in Ikkitousen and Koihime Musou nor Gundams and wanted a faithful version with old men, then here’s the perfect alternative. This 52-episode series was aired in China by CCTV and completed its run back in 2008, meaning this is a rebroadcasting for the Japanese market. It took four years to complete and cost 650 million yen (~7m USD).
Romance of the Three Kingdoms | 最強武将伝・三国演義
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

Basically, it's a pretty famous Chinese story (at least in that part of the world). For that reason I might check it out, although I must say that 52 episodes is a really large number for a series that may or may not be any good. One thing that could be interesting is that, as the series was produced by a Chinese company and originally aired in China, the series might be in Chinese, with Japanese subtitles.
If you’re looking for a cute slice-of-life comedy with an all-star cast, then look no further than WORKING. It’s an easy-going series that centers on high school student Takanashi Souta, who gets recruited by his short and absolutely adorable senior, Taneshima Popura, to work at a Hokkaido family restaurant named Wagnaria (hence the official site URL). As a normal and diligent 16 year old, Souta soon learns that all his coworkers are a bit unusual. This includes a manager who doesn’t care to work properly, a floor chief who carries a katana with her, and a server with androphobia. However, as a self-proclaimed lover of all things small and helpless (i.e. “minicon”), Souta sticks with it and there doesn’t ever seem to be a boring day at his job. The first episode of this had a special early broadcast last month, and I found it a perfect fit to fill that quirky yet clean humor slot for the season.That's about as slice-of-life comedy as you can get. This one actually had an early airing of the first episode a few weeks ago, and it wasn't bad. So, I'm planning on watching it. Oddly, neither RC nor THAT did a summary of the first episode to link you to, despite it being out for a couple weeks.

Another one for the "definitely maybe" pile. On the one hand the art and premise just screams "chick flick" (it is a girls' series, after all), though the premise also seems a bit intriguing. Bakemonogatari was pretty good, so if it's like Bakemonogatari, it could be good; we'll have to see how similar they really are.This is an adaptation of Nakamura Hikaru’s gag/romantic comedy manga about a young man named Ichinomiya Kou who sits on top of the business world, and whose family motto is to never be in debt to anyone for anything. He has that so ingrained in his mind since birth that the mere thought of having debts gives him an asthmatic panic attack. One day by Arakawa Bridge, he’s saved by a homeless girl named Nino living below, leaving him with the biggest debt ever. He’s completely unable to cope with the thought of that and tries to repay Nino by buying her a house, but she’s a bit odd and asks him to love her instead. Thus begins Kou’s life under the bridge with her, where he meets a bunch of very strange individuals, including the resident Kappa village chief. From the manga, I found the character interactions reminiscent of Bakemonogatari, mainly because Kou doesn’t know how to deal with the calm, composed, and most of all weird Nino.
Arakawa Under the Bridge | 荒川アンダー ザ ブリッジ
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

Another maybe series. From that description, it sounds like it could be interesting, if it doesn't turn out to be too depressing. I tend to dislike series that are dark and depressing, so we'll see how it turns out.If you’re looking for a show that’s very different from the usual stuff, then consider this adaptation of Abe George (Jouji) and Kakizaki Masumi’s award-winning manga. Taking place in 1955 after the end of World War II, it depicts the hardships that six juvenile delinquents go through after getting thrown into a corrections facility/prison, often graphically so. From everything to getting sexually abused by the male doctor and having to deal with the tyranny of the wardens, it’s meant to be a realistic view on poverty-stricken Japan following the war. Upon arrival to the prison, the six boys are thrown into Block 2 Cell 6 where they meet “Anchan”, their senior inmate who shows them some tough love on how to survive. The story follows the lives of these seven, both in prison and afterward. Abe George described this as a “story about friendship and courage”, which I could get a sense of from the first few chapters of the manga. Each of the boys was sentenced for acts of assault and theft, but the circumstances they committed their crimes under don’t necessarily make them bad kids, and you can get a feel for that from the bonds they make.
RAINBOW Nisha Rokubou no Shichinin | RAINBOW 二舎六房の七人
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

...and the infamous moe blob returns. To summarize it in a sentence, it's a slice-of-life school comedy about excessively moe girls doing excessively moe things, especially writing/performing excessively moe songs in their amateur band (the premise of the series). It's "the definition of moe" [what it got tagged on AniDB]: if you love moe, you'll probably love it; if you hate moe, you'll probably hate it.It was only at the end of last year that K-ON season two was announced, but three months later we already have more of our favorite light music club. Now with one more exclamation mark in the title! The extra DVD/BD live house episode helped tide things over a bit, but it’s not quite the same as a full season where we’re bound to hear a bunch of new songs. For those unfamiliar with this series, it’s Kyoto Animation’s adaptation of a lighthearted 4-koma manga that follows a group of girls who revive their high school’s music club by forming a band called “After School Tea Time”. It’s published in a seinen manga magazine and features quirky humor and a very cute cast of female characters. In short, it’s moe overload. When the original season aired last spring, the cast of seiyuus were all relatively low-profile, but that all changed with this series. The opening and ending theme songs they sang debuted at #4 and #2 on the Oricon music charts respectively, and they’ve all been in numerous series now, especially lead actress Toyosaki Aki. There are 28 broadcast stations lined up to air this highly anticipated sequel, which absolutely dwarfs every other series by a long shot. There’s no doubt in my mind that I’ll be watching this and it’s a safe series to recommend to almost anyone. Go watch the first season now if you haven’t!

I watched the first season of this, a couple seasons ago (I mentioned that it had a good ending song). It was fairly enjoyable, although it really had entirely too much moe; though obviously the guy who wrote the summary disagrees with that assessment. In either case, it's decently amusing, even if it can get on your nerves.
The noitaminA time slot has expanded from half an hour to a full hour this season, and taking the bottom slot is an adaptation of Ristorante Paradiso creator Ono Natsume’s “House of Five Leaves”. It takes place during the Edo period and revolves around a timid rounin named Akitsu Masanosuke. By chance, he runs into a charismatic individual that wants to hire him as his bodyguard but later finds out that he’s the leader of a gang known as the Five Leaves. Realizing what he’s up against, Masanosuke gets wrapped up in the gang and its very unique individuals and learns there’s more to them than it initially seems. Don’t be swayed by the character designs here if they seem a bit odd to you, as this is just Natsume’s unique style. Personally, I find they’re a refreshing change from the more generic ones you often see.This one's a big question mark. It sounds like it could potentially be interesting, but that's a pretty big maybe. I watched the first couple episodes of Ristorante Paradiso and couldn't stand it, between the art and the writing. So, we'll find out in a week or two how this one is.

Another big question mark, and this one is even less clear on what it's going to be like. Though I have to say the art kind of gives me a bad feeling. Either way, we'll again know more in a couple weeks.Taking the top slot in noitaminA’s newly expanded time slot is a novel adaptation about a nameless third-year Kyoto University student (only referred to as “I”) and his life with the “Tennis Circle Cupid” club that he joined in his first year. The story is broken up into four chapters and will be aired as an 11 episode series here. Not having read the novel, I’m not too sure what to expect, but the promo videos already showcase how strangely different everything is. The title on the other hand seems to translate to “Compendium of 4½ Tatami Mythology”.
Yojou-han Shinwa Taikei | 四畳半神話大系
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

Oh, and in case anyone happens to be interested, RC has covered B Gata H Kei 1 (mentioned yesterday).
On a final note, both the Currently Watching section and the Introduction to Anime/List (which includes a list of almost all free-to-watch anime series I've seen) link on the sidebar are still live, and being updated as new series come out.
Thursday, April 01, 2010
& New Endeavors
A ways back, RaptorIIC, one of the modders back from the StarCraft era, came to me with an idea. He was considering starting an anime blogging site with some of his friends, and wondered if I'd be interested. The basic idea is that bloggers write summaries of episodes of certain series (the ones they're watching) each time a new episode comes out; readers then read the summaries and discuss each episode via the posts' comments. In the past I've mentioned two such sites that I follow: Random Curiosity (henceforth known as RC) and T.H.A.T. Anime Blog (although the latter is mainly for a second set of opinions on new season series, in addition to RC).
I gave it some serious consideration, and mentioned it to a number of my friends online, though I don't think I ever mentioned it on this blog. However, nothing ever became of the idea, and for quite a while nobody thought about it again.
However, now that RC is closing its doors, the idea has come up again, and more seriously than before. To make a long story short, we decided to give it a shot, and just applied to AnimeBlogger (the host of RC, and I believe at one time the host of THAT). As is typical for AnimeBlogger (as mentioned in their FAQ), it's taking a few days to get the new blog all set up.
However, despite this being inspired by the closure of RC, our blog is a bit more of a niche market. That is, our blog will specialize in ecchi and hentai series.
Coming up with a name wasn't exactly trivial. We wanted something halfway tasteful, yet still had a halfway appropriate meaning. "Q & H" was immediately rejected for being too cheesy. Ultimately we decided on Zettai Ryouiki [from WWWJDIC: "絶対領域: exposed skin between top of knee-high socks and hemline of skirt (lit: absolute territory)"].
As you might know, this is right in time for the spring anime season, which begins next week. Obviously we won't know exactly what we're going to cover until we can actually see an episode or two of the new series, but here are a couple that look like good candidates for blogging (the information and pictures are ripped from RC's and THAT's season previews from a few weeks ago; note thus that any first-person statements are not mine):

B Gata H Kei | B型H系
http://www.bgata-hkei.com/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi Adapted from a 4-koma manga serialized in Weekly Young Jump, B Gata H Kei (B-type H-style) targets an older audience with a story about a beautiful high school girl named Yamada, whose sex-ridden mind wants to sleep with 100 different guys. Despite her beauty, she’s actually a virgin because she’s too worried about being ridiculed by good-looking and experienced sex partners to lose it. One day, she mistakenly believes that a plain and homely guy named Kosuda Takashi intentionally saved her from falling over in a bookstore. Sensing that he’s a good yet sexually-inexperienced man like she’s been looking for, she decides to use him as her first and craziness ensues.

kiss x sis | キスシス
http://www.starchild.co.jp/special/kiss_sis/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi Ecchi fans rejoice, as the seinen manga turned OVA is getting its own TV series. Studio Feel is producing this retelling as well, and it will be broadcast on AT-X (and only AT-X). I don’t think I’ll ever quite understand the Japanese fantasy/fetish over incest, but kiss x sis revolves around that idea with stepsiblings unrelated by blood. This is probably the most risqué/borderline hentai series in this season’s lineup, involving a middle school boy named Suminoe Keita, whose high school twin stepsisters, Ako and Riko, are passionately in love with him and will seduce and violate him every chance they get. Keita however doesn’t want any involvement with them in that way and tries to focus on getting into the same high school, even though their parents encourage a potential relationship. The girls completely drive the explicit fan-service here, with Ako being a closet pervert and Riko calm and assertive, but there is some plot involving their childhoods to tie things together in a meaningful way. This still doesn’t change the fact that sexual scenarios are foremost, so unsuspecting viewers beware.

Ikkitousen XTREME XECUTOR | 一騎当千 XTREME XECUTOR
http://www.ikkitousen.com/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi I gather Ikkitousen doesn’t need too much introduction, seeing as XTREME XECUTOR marks the fourth season of the series, but the story here is loosely based on the classic Chinese novel Romance of the Three Kingdoms. That’s what they advertise it as anyway, but anyone who’s actually watched the show will probably tell you it’s an overflowing fan-service affair with busty girls from rival schools fighting one another and getting their clothes torn off like there’s no tomorrow.
On the downside, being an anime blogger will require a lot less laziness from me, as I'll have to blog each episode as it comes out (once a week, for however many series). And everybody knows I hate obligations.
I'll let you know when the blog is online.
Oh, and entirely coincidentally, Anime News Network currently has an ad theme that seems very relevant to this announcement. The relevant slice of the theme:

I gave it some serious consideration, and mentioned it to a number of my friends online, though I don't think I ever mentioned it on this blog. However, nothing ever became of the idea, and for quite a while nobody thought about it again.
However, now that RC is closing its doors, the idea has come up again, and more seriously than before. To make a long story short, we decided to give it a shot, and just applied to AnimeBlogger (the host of RC, and I believe at one time the host of THAT). As is typical for AnimeBlogger (as mentioned in their FAQ), it's taking a few days to get the new blog all set up.
However, despite this being inspired by the closure of RC, our blog is a bit more of a niche market. That is, our blog will specialize in ecchi and hentai series.
Coming up with a name wasn't exactly trivial. We wanted something halfway tasteful, yet still had a halfway appropriate meaning. "Q & H" was immediately rejected for being too cheesy. Ultimately we decided on Zettai Ryouiki [from WWWJDIC: "絶対領域: exposed skin between top of knee-high socks and hemline of skirt (lit: absolute territory)"].
As you might know, this is right in time for the spring anime season, which begins next week. Obviously we won't know exactly what we're going to cover until we can actually see an episode or two of the new series, but here are a couple that look like good candidates for blogging (the information and pictures are ripped from RC's and THAT's season previews from a few weeks ago; note thus that any first-person statements are not mine):

B Gata H Kei | B型H系
http://www.bgata-hkei.com/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

kiss x sis | キスシス
http://www.starchild.co.jp/special/kiss_sis/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi

Ikkitousen XTREME XECUTOR | 一騎当千 XTREME XECUTOR
http://www.ikkitousen.com/
Information Links: ANN Encyclopedia, AnimeNfo, AniDB, MyAnimeList, syoboi
On the downside, being an anime blogger will require a lot less laziness from me, as I'll have to blog each episode as it comes out (once a week, for however many series). And everybody knows I hate obligations.
I'll let you know when the blog is online.
Oh, and entirely coincidentally, Anime News Network currently has an ad theme that seems very relevant to this announcement. The relevant slice of the theme:

Subscribe to:
Posts (Atom)

