Q1 is a load-store architecture. That means that the only instructions that read/write memory are load and store instructions; all math and binary operations are performed on registers and/or immediates encoded in the instruction itself. Q1 uses three different instruction formats, which maximize the amount of the encoded instruction that is the same for all three formats, to minimize the amount of work that must be done by the instruction decoder circuitry. All instructions have the primary opcode in the highest 6 bits. As well, all immediate values are signed.
The simplest format of instructions is the long immediate format. In this format, the high 6 bits contain the opcode for the instruction, and the remaining 26 bits contain the long (signed) immediate. This format is used primarily in conditional branch instructions, in which the immediate represents the relative address of the branch target, and the opcode indicates the condition being tested.
Next is the short immediate format. In this format, the high 6 bits contain the opcode, the next 5 bits contain the destination register index, the next 5 bits the source register index, and the final 16 bits contain the short (signed) immediate. This format is used for all instructions that take a register and an immediate as parameters, such as load and store instructions (which add the immediate to the value of the source register to form the address for the operation) and math operations that take an immediate value.
Last is the register format. Just like the short immediate format, the top 16 bits contain the opcode, destination register, and first source register, respectively. After that, 5 bits contain the second source register, the next 5 bits the second destination register, and the last 6 bits contain the extended opcode. In this instruction format, the primary opcode is always 0, indicating that this is a register format instruction, and the extended opcode indicating the operation to be performed; this was chosen to allow a greater number of instructions when possible.
The second source register is used in any instruction that takes two inputs, with neither being an immediate. The second destination register is used only in instructions that have two outputs; right now the only instructions which do are the multiply (64-bit result) and divide (32-bit quotient and 32-bit remainder) instructions.
If this instruction format looks familiar (to, say, MIPS), that's probably because I've been studying MIPS all semester in my Low Level Languages class, which handily coincides with the time that I've been designing the Q1. Nevertheless, a lot of it is just common sense. The maximum that can be stored in one instruction is a 16-bit immediate and two 5-bit register indices, leaving 6 bits for the opcode. As well, in each case the order of instruction fields is such that the maximum amount of similarity between formats is achieved, minimizing the decoding hardware necessary.
Thursday, November 24, 2005
Wednesday, November 23, 2005
Conditions and Overflow - The Q1 Way
Finally, the end of this thread of posts: what I'm going to use for the Q1.
Q1 will use a mix-and-match of features from the x86 and PPC. Conditions and overflow are both handled by means of a condition register, with flags for carry (unsigned overflow), overflow (signed overflow), signed (negative) result, and zero result. This condition register will be set only by versions of math and binary instructions that set the condition register (add!, sub!, and!, or!, xor!, nor!).
I decided on this method because I consider it too slow and cumbersome to have to manually determine whether overflow or carry has occurred, or whether a comparison of two numbers is true. As well, exceptions are too slow to execute; not only that, but to support both carry and overflow exceptions, there would have to be separate signed and unsigned instructions for every math operation.
I also considered making add and subtract operations 4-register operations (two inputs, and two outputs forming a doubleword result), which would have made it very easy to do chain math operations of values larger than the word; while this is a neat idea, it seemed impractical, as not only would it have required signed and unsigned variants of those operations (so that the Q1 would be able to determine whether the high word should be 1 or -1 if a carry occurs), but it would have made comparisons against zero more difficult.
Q1 supports two methods of handling conditions, once the condition register has been set. First, it supports conditional jumps for carry/unsigned less than, overflow/signed less than, unsigned greater than, signed greater than, signed result, and zero result. It also supports conditional moves that are 3-register operations - the destination register will be set to one value (in another register) if the condition is true, or a second value if it is false. I may also add an instruction to invert the condition register flags; I'm still thinking about that.
To me, conditional moves were a necessity, for speed reasons. Any conditional branch has the potential to be slow, with that potential directly proportional to the frequency of the less taken branch; conditional moves do not have that possibility. However, if you think about it, it's logically possible to implement conditional branches without any conditional branch instructions at all: perform a conditional move with the two target addresses, then do an unconditional branch. While that would have cut down the number of instructions in the Q1 by half a dozen, I thought it would be too slow. A conditional branch takes only a single instruction, while using a conditional move in that way requires four: two loads to load the target addresses, the conditional move, and the unconditional branch.
Q1 will use a mix-and-match of features from the x86 and PPC. Conditions and overflow are both handled by means of a condition register, with flags for carry (unsigned overflow), overflow (signed overflow), signed (negative) result, and zero result. This condition register will be set only by versions of math and binary instructions that set the condition register (add!, sub!, and!, or!, xor!, nor!).
I decided on this method because I consider it too slow and cumbersome to have to manually determine whether overflow or carry has occurred, or whether a comparison of two numbers is true. As well, exceptions are too slow to execute; not only that, but to support both carry and overflow exceptions, there would have to be separate signed and unsigned instructions for every math operation.
I also considered making add and subtract operations 4-register operations (two inputs, and two outputs forming a doubleword result), which would have made it very easy to do chain math operations of values larger than the word; while this is a neat idea, it seemed impractical, as not only would it have required signed and unsigned variants of those operations (so that the Q1 would be able to determine whether the high word should be 1 or -1 if a carry occurs), but it would have made comparisons against zero more difficult.
Q1 supports two methods of handling conditions, once the condition register has been set. First, it supports conditional jumps for carry/unsigned less than, overflow/signed less than, unsigned greater than, signed greater than, signed result, and zero result. It also supports conditional moves that are 3-register operations - the destination register will be set to one value (in another register) if the condition is true, or a second value if it is false. I may also add an instruction to invert the condition register flags; I'm still thinking about that.
To me, conditional moves were a necessity, for speed reasons. Any conditional branch has the potential to be slow, with that potential directly proportional to the frequency of the less taken branch; conditional moves do not have that possibility. However, if you think about it, it's logically possible to implement conditional branches without any conditional branch instructions at all: perform a conditional move with the two target addresses, then do an unconditional branch. While that would have cut down the number of instructions in the Q1 by half a dozen, I thought it would be too slow. A conditional branch takes only a single instruction, while using a conditional move in that way requires four: two loads to load the target addresses, the conditional move, and the unconditional branch.
Tuesday, November 22, 2005
Practical MMORPG Math
We now interrupt your normally scheduled viewing for this unimportant math lesson.
As has been mentioned previously, I spend a substantial amount of time playing World of Warcraft (WoW), Blizzard's MMORPG. More than anything else, I like playing with my friends. However, as is especially the case with friends who have a very limited amount of time they can play (or only use a single character), sometimes they play without me (I play on many chars, so it's rarely a problem the other way around). For catching up, I've developed a strategy, one that has left two of my friends with blank (uncomprehending) stares, thus far; so, I'll explain the math behind it, here.
First, let me give a brief summary of the relevant features of WoW, for those who haven't played it:
- Enemies near your level give experience (XP) when you kill them
- When in a party, XP for kills (only kills) is divided by the number of players in the party
- Quests come in many shapes and sizes; kill X number of Y, and collect X number of Y, where Y drops at some frequency from enemy Z are two examples
- Quests give XP when you complete them
- Each quest can generally only be completed once per character
- Thus, quest rewards are not a good way of playing catch-up, as the person you're playing with will have to do them in the future, and you won't have gained anything
- Grinding (killing enemies without any purpose other than to get XP) is boring
So, here's my strategy: when playing catch-up solo, do quests that require collection of items that drop off enemies. If you think about it, you can imagine the reasoning for my friends' skepticism: if you have to kill Y (the number of people in the party) times as many enemies, each giving 1/Y XP when in a party, shouldn't that mean that you get the same amount of XP doing the quest solo as when you do it in a group?
No. And here's why. While it's true that you will get the same amount of XP from the enemies when you do the quest, remember that the people you're playing with still need to do the quest. If you tag along with them, not only will you get the XP of when you did it solo, but you will also get a proportionate share of the XP from the party (100% * XP + 100%/Y XP). And by doing so, you decrease the amount of XP the other party members get, proportionally (100% * (Y - 1)/Y XP). This comes out, for example, to a 150%/50% (% of the amount of XP for doing the quest solo) or 3:1 split between you and your companion, if in a group of two (166%/66%/66%, 5:2:2, for three, etc.).
And on a completely unrelated note, there's a term in psychology called the hindsight bias. It describes the tendency of people who know the solution to a problem (especially in the case of nontrivial problems) to think that the answer was unavoidably obvious, even when the problem is difficult enough that it is likely that they themselves could not have solved it. Also known as the "I could have told you that" syndrome. A prime example of this is the media and others' response to the "intelligence failures" that prevented the 9/11 attacks on the World Trade Center from being stopped, despite the previously obtained evidence that the attack was coming.
As has been mentioned previously, I spend a substantial amount of time playing World of Warcraft (WoW), Blizzard's MMORPG. More than anything else, I like playing with my friends. However, as is especially the case with friends who have a very limited amount of time they can play (or only use a single character), sometimes they play without me (I play on many chars, so it's rarely a problem the other way around). For catching up, I've developed a strategy, one that has left two of my friends with blank (uncomprehending) stares, thus far; so, I'll explain the math behind it, here.
First, let me give a brief summary of the relevant features of WoW, for those who haven't played it:
- Enemies near your level give experience (XP) when you kill them
- When in a party, XP for kills (only kills) is divided by the number of players in the party
- Quests come in many shapes and sizes; kill X number of Y, and collect X number of Y, where Y drops at some frequency from enemy Z are two examples
- Quests give XP when you complete them
- Each quest can generally only be completed once per character
- Thus, quest rewards are not a good way of playing catch-up, as the person you're playing with will have to do them in the future, and you won't have gained anything
- Grinding (killing enemies without any purpose other than to get XP) is boring
So, here's my strategy: when playing catch-up solo, do quests that require collection of items that drop off enemies. If you think about it, you can imagine the reasoning for my friends' skepticism: if you have to kill Y (the number of people in the party) times as many enemies, each giving 1/Y XP when in a party, shouldn't that mean that you get the same amount of XP doing the quest solo as when you do it in a group?
No. And here's why. While it's true that you will get the same amount of XP from the enemies when you do the quest, remember that the people you're playing with still need to do the quest. If you tag along with them, not only will you get the XP of when you did it solo, but you will also get a proportionate share of the XP from the party (100% * XP + 100%/Y XP). And by doing so, you decrease the amount of XP the other party members get, proportionally (100% * (Y - 1)/Y XP). This comes out, for example, to a 150%/50% (% of the amount of XP for doing the quest solo) or 3:1 split between you and your companion, if in a group of two (166%/66%/66%, 5:2:2, for three, etc.).
And on a completely unrelated note, there's a term in psychology called the hindsight bias. It describes the tendency of people who know the solution to a problem (especially in the case of nontrivial problems) to think that the answer was unavoidably obvious, even when the problem is difficult enough that it is likely that they themselves could not have solved it. Also known as the "I could have told you that" syndrome. A prime example of this is the media and others' response to the "intelligence failures" that prevented the 9/11 attacks on the World Trade Center from being stopped, despite the previously obtained evidence that the attack was coming.
Monday, November 21, 2005
Dilemma - Conditions and Overflow
Now that I've discussed conditions and overflow, I can explain what the dilemma is (or was, back when I was thinking about it). The way I see it, there are three methods of handling conditions and overflow (although two are much more similar than the third).
MIPS treats signed overflow (but not unsigned carry, which it provides no mechanism for detecting) as an exception. When an arithmetic instruction generates signed overflow, an overflow exception is generated, and the exception handler is called. Separate unsigned arithmetic instructions exist, which will not throw overflow exceptions.
Conditions, on the other hand, are implemented by a series of conditional branch instructions: beq (branch if two values are equal), bne (branch of two values are not equal), bltz (branch if value is less than zero), blez (branch if value is less than or equal to zero), bgtz (branch if greater than zero), bgez (branch if greater than or equal to zero).
While overflow exceptions can be convenient, this method has many shortcomings. First, comparisons of two values is cumbersome and slow, as they must be performed using a number of instructions. Testing for carry is similarly slow, and also requires multiple instructions. Finally, exceptions are slow. Even in a single-tasking system (like the Playstation, which uses a MIPS CPU), where the OS doesn't need to do complicated exception handling before control returns to the program (I benchmarked this taking more than 100,000 cycles on my NT computer), if the exception handler is called in kernel mode (as is the case for MIPS, x86, etc.), a full kernel mode transition is still required before the user mode handler (i.e. the catch block) can get invoked (I don't know about MIPS, but on x86 this kind of thing can take hundreds of cycles). Compare this to the worst case scenario in a Pentium 4 (the worst performing CPU I know of, with respect to unpredicted branches), where an incorrectly predicted branch can stall the CPU for 29 cycles.
x86 uses perhaps the most obvious method of handling conditions and overflows: a condition register. This register has flags for a wide variety of conditions, including carry, overflow, zero, signed, all four being set (or reset, as the case may be) by math and binary (and, or, etc.) instructions. In addition (and likely on account of the fact that the x86 only has 8 registers), x86 has two comparison instructions: CMP, which is equivalent to a subtraction, save that the result is not written to any register (thus conserving a register, while setting the flags from the operation), and TEST, which performs a binary and, then discards the result.
x86 offers three ways of responding to conditions. First, conditional branches allow for branching based on various conditions, such as greater than, less than, carry, signed, etc. As well, conditional set instructions set a register depending on whether the condition is true (1) or false (0); this is commonly used for complex boolean algebra expressions. Finally, conditional move instructions perform a move only if the condition is true. The conditional set and condition move instructions are of particular value, as they allow actions other than branches (which can be mispredicted) to be taken based on conditions.
PowerPC uses a similar but simpler method of handling conditions and overflow. It also uses a condition register, comparison instructions (similar to the x86 CMP command), and conditional branches, but does not support conditional moves or sets. What is noteworthy, however, is that each math and logical instruction comes in two flavors: those that set the condition register, and those that don't. This allows other math operations to come between the condition register being set and the action taken as a result.
MIPS treats signed overflow (but not unsigned carry, which it provides no mechanism for detecting) as an exception. When an arithmetic instruction generates signed overflow, an overflow exception is generated, and the exception handler is called. Separate unsigned arithmetic instructions exist, which will not throw overflow exceptions.
Conditions, on the other hand, are implemented by a series of conditional branch instructions: beq (branch if two values are equal), bne (branch of two values are not equal), bltz (branch if value is less than zero), blez (branch if value is less than or equal to zero), bgtz (branch if greater than zero), bgez (branch if greater than or equal to zero).
While overflow exceptions can be convenient, this method has many shortcomings. First, comparisons of two values is cumbersome and slow, as they must be performed using a number of instructions. Testing for carry is similarly slow, and also requires multiple instructions. Finally, exceptions are slow. Even in a single-tasking system (like the Playstation, which uses a MIPS CPU), where the OS doesn't need to do complicated exception handling before control returns to the program (I benchmarked this taking more than 100,000 cycles on my NT computer), if the exception handler is called in kernel mode (as is the case for MIPS, x86, etc.), a full kernel mode transition is still required before the user mode handler (i.e. the catch block) can get invoked (I don't know about MIPS, but on x86 this kind of thing can take hundreds of cycles). Compare this to the worst case scenario in a Pentium 4 (the worst performing CPU I know of, with respect to unpredicted branches), where an incorrectly predicted branch can stall the CPU for 29 cycles.
x86 uses perhaps the most obvious method of handling conditions and overflows: a condition register. This register has flags for a wide variety of conditions, including carry, overflow, zero, signed, all four being set (or reset, as the case may be) by math and binary (and, or, etc.) instructions. In addition (and likely on account of the fact that the x86 only has 8 registers), x86 has two comparison instructions: CMP, which is equivalent to a subtraction, save that the result is not written to any register (thus conserving a register, while setting the flags from the operation), and TEST, which performs a binary and, then discards the result.
x86 offers three ways of responding to conditions. First, conditional branches allow for branching based on various conditions, such as greater than, less than, carry, signed, etc. As well, conditional set instructions set a register depending on whether the condition is true (1) or false (0); this is commonly used for complex boolean algebra expressions. Finally, conditional move instructions perform a move only if the condition is true. The conditional set and condition move instructions are of particular value, as they allow actions other than branches (which can be mispredicted) to be taken based on conditions.
PowerPC uses a similar but simpler method of handling conditions and overflow. It also uses a condition register, comparison instructions (similar to the x86 CMP command), and conditional branches, but does not support conditional moves or sets. What is noteworthy, however, is that each math and logical instruction comes in two flavors: those that set the condition register, and those that don't. This allows other math operations to come between the condition register being set and the action taken as a result.
Sunday, November 20, 2005
Conditions
Now that I've explained the topic of overflow, I can get to the second part of the problem: conditions. Conditions are any manner of expression that can produce different behavior when the very same instruction is executed multiple times. The most common types of conditions are equal, not equal, less than, and greater than.
The reason I put overflow and conditions under the same heading is that conditions are also based on carry overflow. If we compare two values, one of the following must be true: they are equal, the first is less than the second, or the first is greater than the second. Computers perform this comparison using subtraction, then checking for overflow. Compare unsigned 5 and 10 (in that order): 5 - 10 = -5 (a nonunsigned result) with carry. If we reverse these, 10 - 5 = 5, with no carry.
Thus, a carry indicates that the first is less than the second (this is always true, not just in these two examples). In the case of both values being equal, the result will be 0. Note that the assumption that carry indicates less than, and no carry indicates greater than, is only valid when the result is nonzero.
Signed comparisons are a bit more complicated, as it's not as simple as whether or not there is overflow. I won't go into examples of why this is (as you'd have to construct a full truth table to see the relationships), but this is how it works: excluding the case of both being equal, then the first value is less than the second if the overflow state is different than the sign of the result of the subtraction (overflow != result_sign) .
The reason I put overflow and conditions under the same heading is that conditions are also based on carry overflow. If we compare two values, one of the following must be true: they are equal, the first is less than the second, or the first is greater than the second. Computers perform this comparison using subtraction, then checking for overflow. Compare unsigned 5 and 10 (in that order): 5 - 10 = -5 (a nonunsigned result) with carry. If we reverse these, 10 - 5 = 5, with no carry.
Thus, a carry indicates that the first is less than the second (this is always true, not just in these two examples). In the case of both values being equal, the result will be 0. Note that the assumption that carry indicates less than, and no carry indicates greater than, is only valid when the result is nonzero.
Signed comparisons are a bit more complicated, as it's not as simple as whether or not there is overflow. I won't go into examples of why this is (as you'd have to construct a full truth table to see the relationships), but this is how it works: excluding the case of both being equal, then the first value is less than the second if the overflow state is different than the sign of the result of the subtraction (overflow != result_sign) .
Saturday, November 19, 2005
Overflow
One of the major design decisions I had to make for Q1 was how to handle two things that seem unrelated, but really are: arithmetic overflow and conditions. Arithmetic overflow occurs when the result of arithmetic (either addition or subtraction) is a number that is too large to be represented in a single word (a register; as Q1 is a 32-bit CPU, its words are 32-bit).
Take the case of the unsigned addition of 0xFFFFFFFF and 0xFFFFFFFF (the largest possible numbers). The correct result of this addition is 0x1FFFFFFFE. However, this result requires 33 bit, and is thus truncated to 0xFFFFFFFE when placed in a register; one bit of significant data is loss.
Now, at the risk of confusing you, I should make it clear that the lost 33rd bit is not always significant. Take, for example, the subtraction of 5 from 10. In two's complement math this is performed by negating the 5 (to get 0xFFFFFFFB) and then adding it to 10. The result of this is 0x100000005, which is 33 bits. In this case, one bit is lost, but it contains no actual information. A single example such as this isn't sufficient to prove it is so, so I'll tell you straight out: for unsigned subtraction, overflow occurs if and only if there is NO loss of the 33rd bit - exactly the opposite of the case for addition.
However, it gets even more complicated. Consider the signed addition of 0x40000000 and 0x50000000. Both of these numbers are positive, so the result must also be positive. However, the result of addition is 0x90000000; the fact that the highest bit has been set indicates that the number is negative. Overflow has occurred, even though the 33rd bit hasn't been touched. Now consider the addition of -1 and -1 (0xFFFFFFFF). In this case the result is 0x1FFFFFFFE, or 0xFFFFFFFE (-2) when truncated. Here, the 33rd bit is lost, but no overflow has occurred.
What this means is that there are different methods of detecting overflow for signed and unsigned arithmetic. Unsigned arithmetic is fairly simple: if ((33rd_bit != 0) != is_subtraction), overflow has occurred. For signed arithmetic, it's more complicated. First of all, let me tell you that this equation, although it appears in some computer architecture books (like mine), is NOT correct: if (33rd_bit != 32nd_bit) overflow. The correct equation is: if ((32nd_bit_of_operand_1 == 32rd_bit_of_operand_2) && (32nd_bit_of_result != 32nd_bit_of_operand_1)) overflow. In other words, if both operands have the same sign (remember that with subtraction one operand will be negated; this must be taken into account), but the sign of the result is different, then overflow has occurred. Traditionally, unsigned overflow is referred to as a carry, and signed overflow is referred to as overflow (neither of which are particularly good names).
Take the case of the unsigned addition of 0xFFFFFFFF and 0xFFFFFFFF (the largest possible numbers). The correct result of this addition is 0x1FFFFFFFE. However, this result requires 33 bit, and is thus truncated to 0xFFFFFFFE when placed in a register; one bit of significant data is loss.
Now, at the risk of confusing you, I should make it clear that the lost 33rd bit is not always significant. Take, for example, the subtraction of 5 from 10. In two's complement math this is performed by negating the 5 (to get 0xFFFFFFFB) and then adding it to 10. The result of this is 0x100000005, which is 33 bits. In this case, one bit is lost, but it contains no actual information. A single example such as this isn't sufficient to prove it is so, so I'll tell you straight out: for unsigned subtraction, overflow occurs if and only if there is NO loss of the 33rd bit - exactly the opposite of the case for addition.
However, it gets even more complicated. Consider the signed addition of 0x40000000 and 0x50000000. Both of these numbers are positive, so the result must also be positive. However, the result of addition is 0x90000000; the fact that the highest bit has been set indicates that the number is negative. Overflow has occurred, even though the 33rd bit hasn't been touched. Now consider the addition of -1 and -1 (0xFFFFFFFF). In this case the result is 0x1FFFFFFFE, or 0xFFFFFFFE (-2) when truncated. Here, the 33rd bit is lost, but no overflow has occurred.
What this means is that there are different methods of detecting overflow for signed and unsigned arithmetic. Unsigned arithmetic is fairly simple: if ((33rd_bit != 0) != is_subtraction), overflow has occurred. For signed arithmetic, it's more complicated. First of all, let me tell you that this equation, although it appears in some computer architecture books (like mine), is NOT correct: if (33rd_bit != 32nd_bit) overflow. The correct equation is: if ((32nd_bit_of_operand_1 == 32rd_bit_of_operand_2) && (32nd_bit_of_result != 32nd_bit_of_operand_1)) overflow. In other words, if both operands have the same sign (remember that with subtraction one operand will be negated; this must be taken into account), but the sign of the result is different, then overflow has occurred. Traditionally, unsigned overflow is referred to as a carry, and signed overflow is referred to as overflow (neither of which are particularly good names).
Friday, November 18, 2005
Ssssssssssssssmokin'!
Pop quiz, kids: is it a good thing or a bad thing when your CPU is hot enough to boil water? Because mine is! And gosh, just as I was typing this message my grandparents called and asked if there were any forest fires in our area (there are some in our state right now, but not too close to us). Heh, earlier today I was talking to Dark_Brood about CPUs, and mentioning that the new CPUs are twice as fast as mine (by raw clock speed). Wonder if I'll have to replace any other parts while I'm at it (and no, I'm not on my own computer, right now).
!#@$, It Broke!
Okay, I just broke the VC++ optimizer, or something. All of a sudden it started adding a copy of the return path to EACH INSTRUCTION (there are about 50 of them). While each one isn't so bad on its own (7 bytes), this adds up to 350 bytes (16% of the total of 2,162 bytes for the emulation core).
Thursday, November 17, 2005
& Immunology
BahamutZero just informed me that one of the major books on immunology is available freely online. If that sort of thing interests you (like it does me and BZ), you should go check it out.
Not for the Faint of Heart
Q1Emu is becoming quite a noteworthy piece of software. I wonder if, somewhere, there's a prize for most creative use of code structure that implies a compiler optimization strategy; I could be in the running for it. I've already broken the Visual Studio debugger's ability to match source code lines to instruction addresses; I'm sure the VS coders will be warning everyone "friends don't let friends' compilers do Q1Emu" :P
Incidentally, the Q1 emulation core is now done. It currently weighs in at 1.8 KB, but I may be able to shrink it some. So far all the optimization has been stuff I've done as I've coded. Now that I'm all done, I can go back and look for new things to optimize.
Incidentally, the Q1 emulation core is now done. It currently weighs in at 1.8 KB, but I may be able to shrink it some. So far all the optimization has been stuff I've done as I've coded. Now that I'm all done, I can go back and look for new things to optimize.
Tank-Top and Shorts?
While not the first to point out the lack of malware utility response to the Sony rootkit, Groklaw is pointing out something few seem to have noticed (original source):
The creator of the copy-protection software, a British company called First 4 Internet, said the cloaking mechanism was not a risk, and that its team worked closely with big antivirus companies such as Symantec to ensure that was the case. The cloaking function was aimed at making it difficult, though not impossible, to hack the content protection in ways that have been simple in similar products, the company said.So the antivirus companies were working with the maker of the rootkit to begin with? Hope you brought some cool clothes, because it's hot where we're going.
& Debates - Origin of Homosexuality
Star Alliance forums are back up, and I've got a new debate to go with them:
So, I was looking for articles on gender roles for a psychology class paper. Well, I found something really interesting, because it totally NOT what I was expecting to find. First of all, about the person being interviewed:
"Dr. Anne Fousto-Sterling, 56, a professor of biology and women's studies at Brown... lesbian... Her 1985 book, 'Myths of Gender: Biological Theories About Women and Men,' is used in women's studies courses throughout the country."
Q. Among gay people, there is a tendency to embrace a genetic explanation of homosexuality. Why is that?
A. It's a popular idea with gay men. Less so with gay women. That may be because the genesis of homosexuality appears to be different for men than women. I think gay men also face a particularly difficult psychological situation because they are seen as embracing something hated in our culture - the feminine - and so they'd better come up with a good reason for what they're doing.
Gay women, on the other hand, are seen as, rightly or wrongly, embracing something our culture values highly - masculinity. Now that whole analysis that gay men are feminine and gay women are masculine is itself open to big question, but it provides a cop-out and an area of relief. You know, "It's not my fault, you have to love me anyway."
It provides the disapproving relatives with an excuse: "It's not my fault, I didn't raise 'em wrong." It provides a legal argument that is, at the moment, actually having some sway in court. For me, it's a very shaky place. It's bad science and bad politics. It seems to me that the way we consider homosexuality in our culture is an ethical and moral question.
The biology here is poorly understood. The best controlled studies performed to measure genetic contributions to homosexuality say that 50 percent of what goes into making a person homosexual is genetic. That means 50 percent is not. And while everyone is very excited about genes, we are clueless about the equally important nongenetic contributions.
Q. Why do you suppose lesbians have been less accepting than gay men about genetics as the explanation for homosexuality?
A. I think most lesbians have more of a sense of the cultural component in making us who we are. If you look at many lesbians' life histories, you will often find extensive heterosexual experiences. They often feel they've made a choice. I also think lesbians face something that males don't: at the end of the day, they still have to be a woman in a world run by men. All of that makes them very conscious of complexity.
Hallelujah!
At a conference for its management software customers, company executives detailed its plans to add support 64-bit microprocessors in its server applications and operating systems.Frankly, I was dissappointed when MS announced that Longhorn would run on x86-32 at all. Now that x86-64 CPUs are starting to appear on the desktop, and should be the majority by the time Longhorn ships, having Longhorn only run on x86-64 would have drastically simplified application design. But I guess something is better than nothing.
By late next year, Microsoft expects to deliver Exchange 12, which will run only on x86-compatible 64-bit servers, said Bob Kelly, general manager of infrastructure server marketing at Microsoft.
Kelly said 64-bit chips will make the greatest impact on the performance of applications such as Exchange and its SQL Server database.
"IT professionals will be able to consolidate the total number of servers running 64-bit (processors) and users will be able to have bigger mailbox size," he said.
Longhorn Server R2 and a small-business edition of Longhorn Server will be available only for x86-compatible 64-bit chips as well the company's Centro mid-market bundle. Longhorn server is expected to be released in 2007 and the R2 follow-up could come two years after that.
Tuesday, November 15, 2005
It Runs! - UPDATED
That title pretty much says it all. Today I have a paper to write; that means it's procrastination time! Fortunately, I had plenty of stuff to procrastinate with. So, I started working on an emulator for Q1 (my CPU). After only an hour or so of coding, it runs a simple test program with a 6 instruction set. Of course, as each instruction only requires 3 lines of code, adding the other 50 or so will be quite easy. I'll have to do that on Thursday.
UPDATE: Now it's up to 24 instructions (half the instruction set). The emulation core is about 2/3 KB of optimized assembly. Should be no problem keeping the emulation function and the CPU context (most importantly the registers) in L1 cache, making it about as fast as possible.
UPDATE: Now it's up to 24 instructions (half the instruction set). The emulation core is about 2/3 KB of optimized assembly. Should be no problem keeping the emulation function and the CPU context (most importantly the registers) in L1 cache, making it about as fast as possible.
News From the Front Lines
durandal255 (11:16 PM) :
in the latest wow patch, they finally admit to searching your computer for viruses and cheats
Quantam (11:17 PM) :
I saw that
durandal255 (11:17 PM) :
it pokes through my IE history!
Quantam (11:17 PM) :
That's not cool
durandal255 (11:17 PM) :
god knows what it does after that!
durandal255 (11:18 PM) :
it also looks at your autoexec.bat, and um, your start menu and desktop shortcuts
Quantam (11:18 PM) :
Dude
durandal255 (11:18 PM) :
old news?
Quantam (11:18 PM) :
I bet MS' malicious software removal tool does less than that
durandal255 (11:19 PM) :
rofl
durandal255 (11:19 PM) :
it looks at ntuser.log and both the 9x and NT temp folders
durandal255 (11:20 PM) :
i bet i'd find it inspecting my MBR if i knew how to look for that
Quantam (11:20 PM) :
Probably
in the latest wow patch, they finally admit to searching your computer for viruses and cheats
Quantam (11:17 PM) :
I saw that
durandal255 (11:17 PM) :
it pokes through my IE history!
Quantam (11:17 PM) :
That's not cool
durandal255 (11:17 PM) :
god knows what it does after that!
durandal255 (11:18 PM) :
it also looks at your autoexec.bat, and um, your start menu and desktop shortcuts
Quantam (11:18 PM) :
Dude
durandal255 (11:18 PM) :
old news?
Quantam (11:18 PM) :
I bet MS' malicious software removal tool does less than that
durandal255 (11:19 PM) :
rofl
durandal255 (11:19 PM) :
it looks at ntuser.log and both the 9x and NT temp folders
durandal255 (11:20 PM) :
i bet i'd find it inspecting my MBR if i knew how to look for that
Quantam (11:20 PM) :
Probably
MD5 Is Officially Dead - UPDATED
Patrick Stach has announced that he has created a program that can find MD5 hash collisions in 45 minutes on a 1.6 ghz Pentium 4. If that's true, MD5 isn't just insecure, it's downright dead.
If you've got any digital signatures using MD5, I suggest you FIX THEM, NOW! (not that I know exactly what to use; SHA-1 is on its last leg)
UPDATE: Fortunately, it isn't as bad as I thought it was. This program can only produce two randomly generated messages that hash to the same value; it cannot find a new message that matches a given hash. No complete security meltdown yet, but you could still safely say that MD5 is no longer safe to use.
If you've got any digital signatures using MD5, I suggest you FIX THEM, NOW! (not that I know exactly what to use; SHA-1 is on its last leg)
UPDATE: Fortunately, it isn't as bad as I thought it was. This program can only produce two randomly generated messages that hash to the same value; it cannot find a new message that matches a given hash. No complete security meltdown yet, but you could still safely say that MD5 is no longer safe to use.
& Debates - Responsibility - UPDATED
One of the sites I frequent is the Star Alliance. Star Alliance is a game and modding site, but it also is known for something else: its debates. While not exactly the Socrates, Plato, and Aristotle of our time, the forumers manage to regularly engage in at least halfway intellectual debates (some more than other), often involving religion or philosphy. While there are some exceptions, these debates are moderately mature, particularly as the site ages, and the 'old school' forumers are in college, now.
Now that there's a formal debate forum (requires registration to view/post in) with more strict rules for posts, I've begun to periodically start debates (in fact I have a list of four or so I plan to start in the foreseeable future). The flavor of the week is the nature of indirect responsibility for something. The opening post (which is just to get the thinking started, before the debate begins):
UPDATE: As those of you (assuming there are any of you out there reading this blog) probably noticed, the Star Alliance site went down a day after I posted this entry, and has been down ever since. Seems they had some problems with their host, and are in the process of relocating. I'll try to remember to post when they come back up.
Now that there's a formal debate forum (requires registration to view/post in) with more strict rules for posts, I've begun to periodically start debates (in fact I have a list of four or so I plan to start in the foreseeable future). The flavor of the week is the nature of indirect responsibility for something. The opening post (which is just to get the thinking started, before the debate begins):
This is, to my knowledge, a fictitious story (although it would hardly surprise me if sometime, somewhere in history it actually happened).A more recent post, which introduces the debate itself:
There once was a husband and wife. The husband worked nights, and the wife frequently became lonely, and went out to meet lovers during the night, although she always returned home before her husband. The wife always cut off the relationships if the lovers wanted it to get serious (as in, endangering her marriage).
One night, she was doing just that: dumping a lover. She had just left the lover's apartment, and was about to go home, when she realized she didn't have money for the ferry she would have to take to get back to her house. Reluctantly, she went back and asked the lover if she could borrow some money. Not surprisingly, the lover slammed the door in her face.
She then went and asked her previous lover (call him #2) for money, who lived nearby. He also slammed the door in her face. So she went back to the ferry, and begged the ferry operator to let her ride for free, and she would pay him back. He refused.
Finally, she remembered there was a bridge a ways away, but she thought she could still make it home in time. However, this bridge was known as being a dangerous area, especially at night. So, she takes the bridge, and, as luck would have it, gets mugged. Angered that she did not have any money, the mugger stabs her, and she dies.
Now, how would you assign blame for the death of the woman? Rank the six characters (the husband, the wife, lover #1, lover #2, the ferry operator, and the mugger) from most responsible to least responsible in your post.
Well, where I was hoping to go with this was a debate about what constitutes responsibility for something like this.Do not think to reply here. If you want to join the debate (which is the whole point of me posting about it), go to the debate itself.
As for myself, I'd say the blame belongs first and foremost to the mugger, as the mugger is the one who actually killed her. But I don't think it's correct to say the woman didn't contribute to it. She made several choices that contributed directly or indirectly to her death. In chronological order:
- She chose to be out there having an affair. While getting killed by a mugger is not a foreseeable outcome of having an affair, I have little sympathy for people who get hurt or killed as a result of perpetrating some crime (in this case the crime is a moral one; as I said a couple posts up, I consider being faithful to your spouse part of the job description for anyone who's married). If a terrorist gets blown up due to a bomb malfunction while trying to bomb some place, all I'm going to say is "Haha, loser!"
- She chose to take a dangerous route in the middle of the night. While that isn't to say she was "asking" to be killed, the fact remains that when you do something fairly dangerous (and you have viable alternatives), you have to take some responsibility for the plausible, predictable outcomes, of which this was one. If I'm welding something while not paying attention, and I end up burning myself (a plausible, predictable outcome for welding carelessly), it's my fault for not being more careful. If, on the other hand, the propane tank explodes and kills me due to some manufacturing defect (neither a plausible nor predictable outcome), that's the manufacturer's fault.
In other news, the usual response to that story (it's commonly used in college psychology classes) is that about half the people blame the woman primarily, and the other half the mugger. I guess this goes to show that you become more conservative with education...

UPDATE: As those of you (assuming there are any of you out there reading this blog) probably noticed, the Star Alliance site went down a day after I posted this entry, and has been down ever since. Seems they had some problems with their host, and are in the process of relocating. I'll try to remember to post when they come back up.
Saturday, November 12, 2005
Errata
Skape (I don't know who that is other than that it's someone Skywing knows) has informed me that my reasoning as to the reasons NTDLL has a fixed address was incorrect. There are kernel mode facilities for loading and preparing user mode modules, so this is not an issue. Rather, the reason is that the kernel expects some functions in NTDLL that it calls to be in the same place for all processes.
Friday, November 11, 2005
Of Wizards and Quantum Physics
Back when I made the post about Singularity, I sent Merlin (of Camelot Systems fame, and who now works as a coder for Microsoft) the link, to ask what he thought of Singularity. He provided me with some food for thought, although I didn't get around to writing about it until now (story of my life...).
His overall conclusion of Singularity was that the idea was 'idiotic'. He had two reasons for this conclusion. First, he claimed that the quality of the JITer is not sufficient for this kind of thing, given that the JITer becomes the single most important piece of software in Singularity, with respect to security and stability (as I said in my post).
Second, he claims that the idea of the JITer being the gatekeeper to system security is fundamentally flawed in that it can't control the hardware. It can certainly ensure that software doesn't have access to the hardware, and that drivers communicate only in well-defined (and legal) ways, but the JITer has no way to verify that the data drivers actually send to the hardware is valid. Even with a JITed system, it's possible a driver might give the wrong address or buffer size to the hardware, and the hardware writes to it, corrupting program or system data (or even worse).
This second point is particularly valid, as I've seen first-hand (my knowledge of the JITer itself is insufficient to comment on the first point). Take a little library I was writing called DD3D (that's 'DirectDraw 3D') as an example. It was a little library that displays a DirectDraw surface as a Direct3D texture map. The test program would recreate the Direct3D device every time you resized the window, so that it could use the right size of back buffer (for optimal image quality). This meant frequent destruction and creation of Direct3D devices. Well, as it turned out, the program initially had a reference count leak that prevented the Direct3D device from actually being destroyed before another one was created; Direct3D even complied with the requests to create new devices.
Eventually, this exhausted some system resource, and it broke. And by 'broke' I don't mean it threw a "screw you, I'm not making any more devices" error (which would have been an appropriate response in this situation). Nor did the program crash, or even blue-screen. Nope; once it got above some number of Direct3D devices created, it hard-reset the computer. That is, blammo, black screen, "testing memory", "press
So, maybe this isn't such a viable idea after all.
& California Housing
Random fact: our house here (which is about 50 years old, 1 story, and moderately large - but not huge or very ornate) is worth more than half a million dollars, up from $65k parents paid 30 years ago. That always boggles my mind.
Also, on a totally unrelated note, I seem to be accumulating quite a harem in my Temp tab of my ICQ contact list (where I put all the people who spontaneously add me to their contact list with no prior contact). 11 girls and counting (and those are the ones that aren't porn bots - I've broken half a dozen porn bots this week alone with my first reply); apparently 'Justin' is a popular name girls from countries all over the planet search for to find people to chat with (one of them said that's how she found me). *shakes head* Heck, at least half of them have never even messaged me.
Also, on a totally unrelated note, I seem to be accumulating quite a harem in my Temp tab of my ICQ contact list (where I put all the people who spontaneously add me to their contact list with no prior contact). 11 girls and counting (and those are the ones that aren't porn bots - I've broken half a dozen porn bots this week alone with my first reply); apparently 'Justin' is a popular name girls from countries all over the planet search for to find people to chat with (one of them said that's how she found me). *shakes head* Heck, at least half of them have never even messaged me.
Asynchronous I/O - Notification Types Summary
Event-Based Notification
Pros
- Only method that allows threads to wait until the operation completes
Cons
- Not useful in most other cases
- Potentially high latency on POSIX
Asynchronous Procedure Calls
Pros
- Calls only occur in the thread that requests the I/O
- Calls can be deferred until the thread is ready for them
- Most convenient method for single-threaded programs
Cons
- Must be polled for in the thread that requested the I/O
- Potentially high latency on POSIX
I/O Completion Ports
Pros
- Potentially fastest (highest throughput), most scalable method on multi-CPU systems, due to optimized thread pooling architecture
Cons
- Cumbersome to use, as often requires construction of a finite state machine
- Not particularly suitable for single-threaded programs
- Potentially high latency on POSIX
Unpredictable Callbacks
Pros
- Lowest latency method on POSIX
- Potentially fast on multi-CPU systems, if the OS does CPU load balancing of callbacks
Cons
- Calls may occur in any thread at any time
- Must be polled for in the thread that requested the I/O
Pros
- Only method that allows threads to wait until the operation completes
Cons
- Not useful in most other cases
- Potentially high latency on POSIX
Asynchronous Procedure Calls
Pros
- Calls only occur in the thread that requests the I/O
- Calls can be deferred until the thread is ready for them
- Most convenient method for single-threaded programs
Cons
- Must be polled for in the thread that requested the I/O
- Potentially high latency on POSIX
I/O Completion Ports
Pros
- Potentially fastest (highest throughput), most scalable method on multi-CPU systems, due to optimized thread pooling architecture
Cons
- Cumbersome to use, as often requires construction of a finite state machine
- Not particularly suitable for single-threaded programs
- Potentially high latency on POSIX
Unpredictable Callbacks
Pros
- Lowest latency method on POSIX
- Potentially fast on multi-CPU systems, if the OS does CPU load balancing of callbacks
Cons
- Calls may occur in any thread at any time
- Must be polled for in the thread that requested the I/O
Wednesday, November 09, 2005
Dilemma: Predictable and Unpredictable?
I'm seriously considering adding a fourth method of asynchronous I/O notification: unpredictable callbacks. Unlike asynchronous procedure calls (APCs), which will only be executed in a predictable place (the thread that requested the I/O) and time (when the APC dispatch function is called), unpredictable callbacks are just that: unpredictable. They could take the form of an APC queued to the thread that requested the I/O, or they could be called at some random time in a totally different thread.
Thus, the practical difference between APCs and unpredictable callbacks is that unpredictable callback functions have to be thread-safe. If they access any shared data, it must be protected by thread synchronization (with APCs you could sometimes get away without thread safety, if the "shared" data was only used by the thread that started the I/O). Of course, because it's possible that unpredictable callbacks will be implemented as APCs, it's still necessary to regularly dispatch APCs for the threads that request I/O.
So, what's the point? Seems like a lot of work for a lot of uncertainty. Well, the usual answer for questions like that about LibQ is speed. Windows implements APCs natively; POSIX does not. Instead, POSIX implements asynchronous I/O notifications via signals, one form of which is unpredictable callbacks. All other types of notification can be readily emulated using POSIX callbacks (as they're the single most flexible method of asynchronous I/O notification), but this comes at a speed cost.
The speed cost itself isn't very large (several dozen cycles), but the latency introduced is much worse (could be hundreds of milliseconds, in the worst case). For situations where a low latency response is needed, this might be too much. If, on the other hand, latency isn't important, other methods might be more convenient (or even faster, i.e. completion ports).
Thus, the practical difference between APCs and unpredictable callbacks is that unpredictable callback functions have to be thread-safe. If they access any shared data, it must be protected by thread synchronization (with APCs you could sometimes get away without thread safety, if the "shared" data was only used by the thread that started the I/O). Of course, because it's possible that unpredictable callbacks will be implemented as APCs, it's still necessary to regularly dispatch APCs for the threads that request I/O.
So, what's the point? Seems like a lot of work for a lot of uncertainty. Well, the usual answer for questions like that about LibQ is speed. Windows implements APCs natively; POSIX does not. Instead, POSIX implements asynchronous I/O notifications via signals, one form of which is unpredictable callbacks. All other types of notification can be readily emulated using POSIX callbacks (as they're the single most flexible method of asynchronous I/O notification), but this comes at a speed cost.
The speed cost itself isn't very large (several dozen cycles), but the latency introduced is much worse (could be hundreds of milliseconds, in the worst case). For situations where a low latency response is needed, this might be too much. If, on the other hand, latency isn't important, other methods might be more convenient (or even faster, i.e. completion ports).
Tuesday, November 08, 2005
& Psychology Fun - UPDATED
"Call girl nymphomaniac in front of entire social psychology class"
*crosses item off life todo list*
That'll teach her not to be so ambiguous in playing her role that people had to ask what she was supposed to be (and nymphomaniac was the first thing that came to my mind after the first couple things she said). :P Was also hilarious when the nerd listed Screech Powers as his hero.
And for your information, the purpose of that exercise was to demonstrate the stereotypes associated with various roles.
BahamutZero's response to this post: "I do think I said you were a devious, corrupt, manipulative and all around dangerous person."
UPDATE: Today (Thursday) in psychology class the teacher was asking for attributes (taken from a list she passed out) that we thought were more typical of women than men. I answered 'tact'. I heard several people chuckle; I have a guess as to why :P
*crosses item off life todo list*
That'll teach her not to be so ambiguous in playing her role that people had to ask what she was supposed to be (and nymphomaniac was the first thing that came to my mind after the first couple things she said). :P Was also hilarious when the nerd listed Screech Powers as his hero.
And for your information, the purpose of that exercise was to demonstrate the stereotypes associated with various roles.
BahamutZero's response to this post: "I do think I said you were a devious, corrupt, manipulative and all around dangerous person."
UPDATE: Today (Thursday) in psychology class the teacher was asking for attributes (taken from a list she passed out) that we thought were more typical of women than men. I answered 'tact'. I heard several people chuckle; I have a guess as to why :P
Friday, November 04, 2005
Q's Fact of the Day
Eating 2/3 of a pound (like 1/3 kg) of gummy worms before tae kwon do is a remarkably stupid idea.
Rootkits, Spyware, and Hacks, Oh My!
So yeah, this news is a bit old now, but I thought I should post it, if for no reason other than to use that post title. All of this stuff I discovered (or, more accurately, was linked to, by people or sites).
First, we have Sony installing a rootkit on the computers of anyone (with admin privileges) that puts the Get Right With the Man CD in their drive. This rootkit is a driver that hides itself from detection by hooking the Windows system call table and preventing any files with file names beginning with "$sys$" from showing up in Explorer or anywhere else (you can readily test for the presence of this rootkit by renaming a file that way, and observing if it disappears). After the public outrage from the Slashdot readers and others, Sony released a none-too-effective uninstaller.
In the same week (at least for me), news of the Warden got around. The Warden is Blizzard's anti-hacking tool for World of Warcraft (in the legacy of Work, Blizzard's neato hack detector for Starcraft, Diablo II, and Warcraft III). This one has the enjoyable function of scanning the programs running on your computer, and sending such things as the title of open windows to Blizzard.
Finally, in a move of minor brilliance (and what makes an ideal final entry in summary posts such as this), hackers decide that it would be worth their time to use one to thwart the other; that is, to use the Sony rootkit to hide their WoW hacks from the Warden. Looks like it's gonna be a war between the video game and music industries for who's responsible for this mess.
First, we have Sony installing a rootkit on the computers of anyone (with admin privileges) that puts the Get Right With the Man CD in their drive. This rootkit is a driver that hides itself from detection by hooking the Windows system call table and preventing any files with file names beginning with "$sys$" from showing up in Explorer or anywhere else (you can readily test for the presence of this rootkit by renaming a file that way, and observing if it disappears). After the public outrage from the Slashdot readers and others, Sony released a none-too-effective uninstaller.
In the same week (at least for me), news of the Warden got around. The Warden is Blizzard's anti-hacking tool for World of Warcraft (in the legacy of Work, Blizzard's neato hack detector for Starcraft, Diablo II, and Warcraft III). This one has the enjoyable function of scanning the programs running on your computer, and sending such things as the title of open windows to Blizzard.
Finally, in a move of minor brilliance (and what makes an ideal final entry in summary posts such as this), hackers decide that it would be worth their time to use one to thwart the other; that is, to use the Sony rootkit to hide their WoW hacks from the Warden. Looks like it's gonna be a war between the video game and music industries for who's responsible for this mess.
Industrial Strength Spin
Okay, I usually try to avoid the Slashdot bashing, but this one I just couldn't resist. One person (who should be thankful they remain nameless) writes:
Of course, these are simply statistics showing off the abilities of Singularity (that's just common sense - when you go to great lengths to make something faster than its competitors, you want to show that it's faster than its competitors), and a much too small sample size to draw any kind of conclusions.
Even more disturbing is that most of the replies to this post are along the lines of "Well, duh. Everybody knows that Windows blows; MS just finally stopped lying about it." And they wonder why Slashdot has a reputation for being a bunch of fanatic Linux zealots who couldn't think rationally if their lives depended on it...
I'm only replying to the parent so that this post is high up the screen.
Look at page 31 of this PDF. Microsoft publish benchmark statistics showing Linux (and FreeBSD) to be better than Windows.
Okay, so this post is so important he decided to ignore posting etiquette. The post refers to a table of benchmarks that shows the number of cycles needed for each of 6 things, on Singularity, XP, FreeBSD, and Linux. If we ignore Singularity, which has the lowest - and thus best - scores in 5 of 6 categories, Windows XP holds the lowest score in 3 categories, Linux in 3 categories, and FreeBSD in none (however, FreeBSD does have a lower score than XP in 1 category). As far as proof of Linux/FreeBSD superiority goes, that's pretty underwhelming (and while I could be grossly ignorant, I don't recall MS ever claiming that Windows was superior to Linux on every single data point).
Of course, these are simply statistics showing off the abilities of Singularity (that's just common sense - when you go to great lengths to make something faster than its competitors, you want to show that it's faster than its competitors), and a much too small sample size to draw any kind of conclusions.
Even more disturbing is that most of the replies to this post are along the lines of "Well, duh. Everybody knows that Windows blows; MS just finally stopped lying about it." And they wonder why Slashdot has a reputation for being a bunch of fanatic Linux zealots who couldn't think rationally if their lives depended on it...
Thursday, November 03, 2005
Groovy
So, today Slashdot (and by association myself) learned about Singularity: Microsoft labs' new playtoy OS. I immediately went and read part of (was already late for class at this time...) the overview paper on the MS labs site.
This thing is pretty sweet. It's like .NET (or Java) applied to an entire computer (OS, drivers, and applications), and then some new ideas. From what I've read, there are two basic ideas that set Singularity apart from any existing production OS. First, the entire system, with the exception of the microkernel, is JITed code. This is a huge benefit because it allows the JITer to verify that the code is safe before it ever gets executed. In a garbage-collected language without pointers, this means no more access violations or buffer overflows, period. It also means the code can't pull exploits like those that can give elevated permissions, or screw up some other thread/process' data.
In fact, because the OS audits all code before it ever gets executed, there's no need for multiple processes at all; indeed, all logical processes in Singularity run in the same virtual address space (commonly known as a 'process' on today's OSs; and in theory you could have everything running in kernel mode and it would still be safe). The fact that code can be guaranteed to be well-behaved on load also removes the need for most (but not all) checks for things like parameter validity, access control, etc., making programs run faster than has ever been possible.
The other major premise of Singularity is strict modularization. All code exists in its own "sandbox". Code is loaded as a unit, either as an application, with multiple code modules, or as a single library. Once a sandbox is created, no new code can be loaded in it.
However, it's possible to call from one sandbox to another. This communication is governed by interface metadata that dictates exactly what is and is not allowed, and is mediated by the JITer. While inter-process communication (IPC) has always been painfully slow in the past, it is not so in this case. Because all code is JITed, the JITer can verify that new code follows the rules, then give it direct access to what it's trying to reach, creating 0-overhead IPC.
Unfortunately, as MS has so much invested in Windows already, it's not actually looking to make this into an actual product. However, I think it's a really promising idea, and hope that somebody at some point will try to make a commercial OS based on this kind of thing.
Oh, and on a completely unrelated note, that overview paper has a benchmark comparing the speed creating processes on various OSs (one of the things I'd been wondering for a while): 5.4 million cycles for XP, compared to Linux's 720k.
This thing is pretty sweet. It's like .NET (or Java) applied to an entire computer (OS, drivers, and applications), and then some new ideas. From what I've read, there are two basic ideas that set Singularity apart from any existing production OS. First, the entire system, with the exception of the microkernel, is JITed code. This is a huge benefit because it allows the JITer to verify that the code is safe before it ever gets executed. In a garbage-collected language without pointers, this means no more access violations or buffer overflows, period. It also means the code can't pull exploits like those that can give elevated permissions, or screw up some other thread/process' data.
In fact, because the OS audits all code before it ever gets executed, there's no need for multiple processes at all; indeed, all logical processes in Singularity run in the same virtual address space (commonly known as a 'process' on today's OSs; and in theory you could have everything running in kernel mode and it would still be safe). The fact that code can be guaranteed to be well-behaved on load also removes the need for most (but not all) checks for things like parameter validity, access control, etc., making programs run faster than has ever been possible.
The other major premise of Singularity is strict modularization. All code exists in its own "sandbox". Code is loaded as a unit, either as an application, with multiple code modules, or as a single library. Once a sandbox is created, no new code can be loaded in it.
However, it's possible to call from one sandbox to another. This communication is governed by interface metadata that dictates exactly what is and is not allowed, and is mediated by the JITer. While inter-process communication (IPC) has always been painfully slow in the past, it is not so in this case. Because all code is JITed, the JITer can verify that new code follows the rules, then give it direct access to what it's trying to reach, creating 0-overhead IPC.
Unfortunately, as MS has so much invested in Windows already, it's not actually looking to make this into an actual product. However, I think it's a really promising idea, and hope that somebody at some point will try to make a commercial OS based on this kind of thing.
Oh, and on a completely unrelated note, that overview paper has a benchmark comparing the speed creating processes on various OSs (one of the things I'd been wondering for a while): 5.4 million cycles for XP, compared to Linux's 720k.
Tuesday, November 01, 2005
& Halloween
Happy halloween! No, Q didn't forget it until today, nor was he too drunk to post until now. No, today's the day: the day Q and friends go and raids all the local stores to get halloween candy at half price. Now it's time to eat candy till your teeth bleed!
Sunday, October 30, 2005
Lazy is Better
So, I'm playing around with code for the asynchronous I/O system. In a number of ways I'm finding that doing things "the right way" (fully thread safe, fully error checked and tolerant, etc.) is both cumbersome to code and slow/bloated when compiled (if you haven't figured it out by now, I step through most new code in release build, to see what the generated assembly looks like). Both of these are very much in opposition to the entire LibQ paradigm; so, I've decided to use a lazy model for the design of this thing.
What that means is that it's sensitive to how you use it. If you follow the rules (particularly with respect to call orders, and what operations you do from different threads simultaneously), nobody gets hurt; if you don't, you can expect that sometime, somewhere, anything ranging from subtle errors to spectacular crashes will slink into your program.
For a couple examples, calling CFile::Open (on the same CFile variable) at the same time from two different threads means death. Closing a file from one thread while another thread is doing a read/write on that file means death. Trying to use the same CAsyncStatus for an operation before the last operation using that CAsyncStatus has completed means death. Get the picture? Most of it's just common sense, but some of it I'll have to explicitly document.
What that means is that it's sensitive to how you use it. If you follow the rules (particularly with respect to call orders, and what operations you do from different threads simultaneously), nobody gets hurt; if you don't, you can expect that sometime, somewhere, anything ranging from subtle errors to spectacular crashes will slink into your program.
For a couple examples, calling CFile::Open (on the same CFile variable) at the same time from two different threads means death. Closing a file from one thread while another thread is doing a read/write on that file means death. Trying to use the same CAsyncStatus for an operation before the last operation using that CAsyncStatus has completed means death. Get the picture? Most of it's just common sense, but some of it I'll have to explicitly document.
Saturday, October 29, 2005
Positional Operations vs. the File Pointer
Traditionally, file I/O was sequential. You read (or wrote) from the beginning of the file to the end. While my history of operating systems isn't sufficient to say that it was the first, Unix was (and still is) particularly fond of this model, because it allows for piping (that is, redirecting the output of one program to the input of another, etc.).
Traditional I/O APIs reflect this behavior, in that they feature a file pointer associated with each file. Reads and writes always begin at the current file pointer, and advance the file pointer on completion (assuming the operation succeeded). If you wanted to do random access on a file (that is, read or write nonsequentially in the file), you had to call a seek function. On Windows, these functions are ReadFile, WriteFile, and SetFilePointer; on Unix, there's read, write, and lseek; and in the C standard library, there's fread, fwrite, and fseek. These functions work perfectly for sequential file access, and work sufficiently for random file access from a single thread (remember that DOS, Win16, and Unix were single-threaded operating systems, although Win16 and Unix could run multiple single thread processes simultaneously).
Then came NT and later editions of Unix (actually, it would hardly surprise me if other OS supported this earlier; I just don't know of them), which introduced multithreaded apps. This introduced the possibility that multiple threads could share access to a single file handle (Unix always allowed multiple programs to share access to files; but in this case each process had its own file handle, with its own file pointer, so this wasn't a problem.
This is a good thing, certainly, but it created problems. Since it was not possible to atomically set the file pointer and perform the file operation (and it would probably even require two trips to kernel mode), the entire procedure was fundamentally thread-unsafe. If two threads tried to perform random file access on the same file at the same time, it would be impossible to tell exactly where each operation would take place.
The simplest solution to this problem would be to protect each file with a mutex. By ensuring mutually exclusive access to the file, you ensure that you will always know exactly where the file pointer is. However, by definition it also causes all threads to wait if more than one thread attempts a file operation at the same time. While this might be acceptable when file I/O occupies a very small portion of the thread's time, this is a distinctly sub-optimal solution.
This is where positional operations come in. Positional operations are read/write functions which explicitly specify where the operation is supposed to occur, and do not alter the file pointer. Windows NT was originally created with this ability (in fact, as previously mentioned, all I/O on NT is internally performed asynchronously, which mandates positional operations) - the very same ReadFile and WriteFile, only used in a different way - but I don't know when exactly the POSIX positional file functions were introduced - pread and pwrite. Windows 9x, again bearing more resemblance to Windows 3.1 than to Windows NT, and again the most primitive of the three, does not support the use of positional operations.
The merit of truly simultaneous operations on the same file may not immediately be obvious. If this is a disk, or some other type of secondary storage, the nature of the device dictates that it can only perform one operation at any point in time; so what benefit is the OS being able to accept multiple operation requests on the same file simultaneously? It is because when the OS supports this in the kernel (as opposed to funneled kernels, or kernels that emulate this with per-file mutexes), neat optimizations can be done. For example, if thread A wants to read 10 bytes from offset 0 in a file, and thread B wants to read 10 bytes from offset 10 in the file, the operations can be combined into one physical disk operation (reading 20 bytes from offset 0), and the OS can then copy the data into the two output buffers.
But even if it isn't the case that the operations can be combined, there are still optimizations that can be done. For example, if thread A wants to read 10 bytes from the file at offset 50, and thread B wants to read 10 bytes from the file at offset 150, does it matter which of these reads gets physically performed first? It does, actually, because the hard drive has a "file pointer" of its own - the head location. If the head location is at offset 0 in the file, it will probably (I say probably because in reality things are a lot more complicated than I've described here; this is just a simple illustration) be faster to perform thread A's read first, then thread B's, because the total distance the head will move in this order is 160 bytes (50 + 10 + 90 + 10); if it did the reads in the opposite order, it would have to move the head forward 160 bytes, then back 110 bytes (150 + 10 - 50), and finally forward 10 bytes, totalling 280 bytes - almost twice as far.
Conclusion: positional file I/O is a Good Thing (tm).
Traditional I/O APIs reflect this behavior, in that they feature a file pointer associated with each file. Reads and writes always begin at the current file pointer, and advance the file pointer on completion (assuming the operation succeeded). If you wanted to do random access on a file (that is, read or write nonsequentially in the file), you had to call a seek function. On Windows, these functions are ReadFile, WriteFile, and SetFilePointer; on Unix, there's read, write, and lseek; and in the C standard library, there's fread, fwrite, and fseek. These functions work perfectly for sequential file access, and work sufficiently for random file access from a single thread (remember that DOS, Win16, and Unix were single-threaded operating systems, although Win16 and Unix could run multiple single thread processes simultaneously).
Then came NT and later editions of Unix (actually, it would hardly surprise me if other OS supported this earlier; I just don't know of them), which introduced multithreaded apps. This introduced the possibility that multiple threads could share access to a single file handle (Unix always allowed multiple programs to share access to files; but in this case each process had its own file handle, with its own file pointer, so this wasn't a problem.
This is a good thing, certainly, but it created problems. Since it was not possible to atomically set the file pointer and perform the file operation (and it would probably even require two trips to kernel mode), the entire procedure was fundamentally thread-unsafe. If two threads tried to perform random file access on the same file at the same time, it would be impossible to tell exactly where each operation would take place.
The simplest solution to this problem would be to protect each file with a mutex. By ensuring mutually exclusive access to the file, you ensure that you will always know exactly where the file pointer is. However, by definition it also causes all threads to wait if more than one thread attempts a file operation at the same time. While this might be acceptable when file I/O occupies a very small portion of the thread's time, this is a distinctly sub-optimal solution.
This is where positional operations come in. Positional operations are read/write functions which explicitly specify where the operation is supposed to occur, and do not alter the file pointer. Windows NT was originally created with this ability (in fact, as previously mentioned, all I/O on NT is internally performed asynchronously, which mandates positional operations) - the very same ReadFile and WriteFile, only used in a different way - but I don't know when exactly the POSIX positional file functions were introduced - pread and pwrite. Windows 9x, again bearing more resemblance to Windows 3.1 than to Windows NT, and again the most primitive of the three, does not support the use of positional operations.
The merit of truly simultaneous operations on the same file may not immediately be obvious. If this is a disk, or some other type of secondary storage, the nature of the device dictates that it can only perform one operation at any point in time; so what benefit is the OS being able to accept multiple operation requests on the same file simultaneously? It is because when the OS supports this in the kernel (as opposed to funneled kernels, or kernels that emulate this with per-file mutexes), neat optimizations can be done. For example, if thread A wants to read 10 bytes from offset 0 in a file, and thread B wants to read 10 bytes from offset 10 in the file, the operations can be combined into one physical disk operation (reading 20 bytes from offset 0), and the OS can then copy the data into the two output buffers.
But even if it isn't the case that the operations can be combined, there are still optimizations that can be done. For example, if thread A wants to read 10 bytes from the file at offset 50, and thread B wants to read 10 bytes from the file at offset 150, does it matter which of these reads gets physically performed first? It does, actually, because the hard drive has a "file pointer" of its own - the head location. If the head location is at offset 0 in the file, it will probably (I say probably because in reality things are a lot more complicated than I've described here; this is just a simple illustration) be faster to perform thread A's read first, then thread B's, because the total distance the head will move in this order is 160 bytes (50 + 10 + 90 + 10); if it did the reads in the opposite order, it would have to move the head forward 160 bytes, then back 110 bytes (150 + 10 - 50), and finally forward 10 bytes, totalling 280 bytes - almost twice as far.
Conclusion: positional file I/O is a Good Thing (tm).
Friday, October 28, 2005
R.I.P. Slinky
So, now we're down by two. Last year (like 53 weeks ago) we lost Kaity, and Tuesday we lost Slinky. Slinky, for those not already acquainted with him, was one of our (formerly) three cats: Poguita ('Dorkess'), Ping Pong ('Slinky'), and Kaity ('Squishy Fat').
Slinky and Dorkess, the twins, were born in 1992, and we've had them ever since then. Slinky was given the official name Ping Pong, due to the white spot on his chin. He was later nicknamed Slinky because of his skinniness and the slinky way he walked. In addition to those, he was known for his perpetually gigantic yellow eyes, his long tail that twitched incessantly, and his constant meowing with his Spanish rolled rrs.
He seemed to have some sort of metabolic disorder, as he remained thin and slinky, despite eating enormous amounts of food (more than any of the other cats). However, this got much worse in the last year or so, as his body seemed to progressively deteriorate in the amount of food it absorbed. Ultimately, he starved to death.
So, I'm writing this post for a couple reasons. First, a number of my friends have heard of Slinky, Dorkess, and Kaity a lot, but so far almost all the pictures I've put online have been of Kaity. As well, this post is to be a tribute to the memory of Slinky, as I believe that instead of grieving someone's death, it's better to be happy about their life.

The twins - Poguita on the left, Pong on the right




Rest in peace, Slinky.
Friday, October 21, 2005
Asynchronous I/O - APCs - Windows Implementation
So, I just wrote the Windows version of the APC system (the NT 4+ one). It was, as expected, trivial. The code is very straightforward, although I should mention one thing: I use WaitForSingleObjectEx rather than SleepEx. See, SleepEx(0, TRUE) has an undesirable behavior: if no APCs are executed, even with a timeout of 0 MS, SleepEx WILL sleep; specifically, it will surrender the rest of the thread's time slice. This can conceivably take hundreds of milliseconds, which is NOT what we want DispatchAsyncCalls to be doing.
To work around this, I used WaitForSingleObjectEx, waiting on an object that will never become signaled (at least not before the function returns) - the current thread. Unlike SleepEx, WaitForSingleObjectEx with a timeout of 0 MS will indeed return immediately.
However, there was a significant problem: by definition LibQ can't use any platform-specific definitions in the interface exposed to the user. PAPCFUNC, however, is a Win32 definition: the prototype for the APC function that Windows calls directly. So, we have what appears to be a paradox: we can't make the client use PAPCFUNC, yet we have no choice but to use PAPCFUNC. The solution: a bit of black magic; you know, the kind of thing that makes other programmers call you (or me, as is often the case) a pervert.
Three potential solutions occurred to me. After some time thinking about it, I decided one was significantly better than the alternatives. Specifically, this one (note that the typedef is platform-independent, while the two defines are the Windows versions of platform-independent macros):
This method works by generating proxy functions that conform to the OS APC prototype, while calling the user's APC function using the platform-independent prototype. Of course, all this is handled by two easy to use macros.
So, this was tested, and confirmed to work. But for me, the ultimate acid test of success with anything LibQ-related was efficiency of code generated. So, into release build we go, to look at the assembly generated in calls to these functions. Take a look:
CThread &thread = CThread::GetCurrentThread();
004018A0 mov eax,dword ptr [Q::CThread::s_curThread (40ECC8h)]
004018A5 push eax
004018A6 call dword ptr [__imp__TlsGetValue@4 (40B034h)]
thread.QueueAsyncCall(MAKE_ASYNC_CALL_PROC(AsyncFunc), 0);
004018AC mov ecx,dword ptr [eax+0Ch]
004018AF push 0
004018B1 push ecx
004018B2 push offset APCProxy_AsyncFunc (401860h)
004018B7 call dword ptr [__imp__QueueUserAPC@12 (40B038h)]
CThread::DispatchAsyncCalls(0);
004018BD push 1
004018BF push 0
004018C1 call dword ptr [__imp__GetCurrentThread@0 (40B040h)]
004018C7 push eax
004018C8 call dword ptr [__imp__WaitForSingleObjectEx@12 (40B03Ch)]
Isn't that pretty? The only way you can tell that this wasn't native Win32 API C code is that the program has to resort to thread-local storage to hold a pointer to the CThread, whereas a Win32 program would just call GetCurrentThread; but I'm quite pleased with the results, and this is a prime example of the LibQ philosophy of incurring the absolute minimum possible amount of overhead.
To work around this, I used WaitForSingleObjectEx, waiting on an object that will never become signaled (at least not before the function returns) - the current thread. Unlike SleepEx, WaitForSingleObjectEx with a timeout of 0 MS will indeed return immediately.
inline bool QueueAsyncCall(PAPCFUNC lpCallProc, uword param)
{
assert(lpCallProc);
return (QueueUserAPC(lpCallProc, m_hThread, (ULONG_PTR)param) != 0);
}
// Returns true if APCs were dispatched before the timeout expired, otherwise false
static inline bool DispatchAsyncCalls(unsigned int nTimeoutMS)
{ return (WaitForSingleObjectEx(::GetCurrentThread(), nTimeoutMS, TRUE) == WAIT_IO_COMPLETION); }
// Returns true if APCs were dispatched, false if an error occurred
static inline bool DispatchAsyncCalls()
{ return (WaitForSingleObjectEx(::GetCurrentThread(), INFINITE, TRUE) == WAIT_IO_COMPLETION); }
{
assert(lpCallProc);
return (QueueUserAPC(lpCallProc, m_hThread, (ULONG_PTR)param) != 0);
}
// Returns true if APCs were dispatched before the timeout expired, otherwise false
static inline bool DispatchAsyncCalls(unsigned int nTimeoutMS)
{ return (WaitForSingleObjectEx(::GetCurrentThread(), nTimeoutMS, TRUE) == WAIT_IO_COMPLETION); }
// Returns true if APCs were dispatched, false if an error occurred
static inline bool DispatchAsyncCalls()
{ return (WaitForSingleObjectEx(::GetCurrentThread(), INFINITE, TRUE) == WAIT_IO_COMPLETION); }
However, there was a significant problem: by definition LibQ can't use any platform-specific definitions in the interface exposed to the user. PAPCFUNC, however, is a Win32 definition: the prototype for the APC function that Windows calls directly. So, we have what appears to be a paradox: we can't make the client use PAPCFUNC, yet we have no choice but to use PAPCFUNC. The solution: a bit of black magic; you know, the kind of thing that makes other programmers call you (or me, as is often the case) a pervert.
Three potential solutions occurred to me. After some time thinking about it, I decided one was significantly better than the alternatives. Specifically, this one (note that the typedef is platform-independent, while the two defines are the Windows versions of platform-independent macros):
// Prototype for asynchronous call functions
typedef void (*TAsyncCallPtr)(uword param);
// Windows macros for APC proxy generation and use. Must be used in the same module as the APC is queued.
#define DECLARE_ASYNC_CALL_PROC(function) static VOID CALLBACK APCProxy_##function(ULONG_PTR lpParam) { function ((uword)lpParam); }
#define MAKE_ASYNC_CALL_PROC(function) (PAPCFUNC)APCProxy_##function
typedef void (*TAsyncCallPtr)(uword param);
// Windows macros for APC proxy generation and use. Must be used in the same module as the APC is queued.
#define DECLARE_ASYNC_CALL_PROC(function) static VOID CALLBACK APCProxy_##function(ULONG_PTR lpParam) { function ((uword)lpParam); }
#define MAKE_ASYNC_CALL_PROC(function) (PAPCFUNC)APCProxy_##function
This method works by generating proxy functions that conform to the OS APC prototype, while calling the user's APC function using the platform-independent prototype. Of course, all this is handled by two easy to use macros.
So, this was tested, and confirmed to work. But for me, the ultimate acid test of success with anything LibQ-related was efficiency of code generated. So, into release build we go, to look at the assembly generated in calls to these functions. Take a look:
CThread &thread = CThread::GetCurrentThread();
004018A0 mov eax,dword ptr [Q::CThread::s_curThread (40ECC8h)]
004018A5 push eax
004018A6 call dword ptr [__imp__TlsGetValue@4 (40B034h)]
thread.QueueAsyncCall(MAKE_ASYNC_CALL_PROC(AsyncFunc), 0);
004018AC mov ecx,dword ptr [eax+0Ch]
004018AF push 0
004018B1 push ecx
004018B2 push offset APCProxy_AsyncFunc (401860h)
004018B7 call dword ptr [__imp__QueueUserAPC@12 (40B038h)]
CThread::DispatchAsyncCalls(0);
004018BD push 1
004018BF push 0
004018C1 call dword ptr [__imp__GetCurrentThread@0 (40B040h)]
004018C7 push eax
004018C8 call dword ptr [__imp__WaitForSingleObjectEx@12 (40B03Ch)]
Isn't that pretty? The only way you can tell that this wasn't native Win32 API C code is that the program has to resort to thread-local storage to hold a pointer to the CThread, whereas a Win32 program would just call GetCurrentThread; but I'm quite pleased with the results, and this is a prime example of the LibQ philosophy of incurring the absolute minimum possible amount of overhead.
Asynchronous I/O - APCs - Updated
So, supporting asynchronous I/O uniformly on a variety of platforms while making full use of OS specific features provides us (or me, at least) with a challenge. However, with a bit of clever object-oriented magic, the challenge is significantly reduced.
Apart from the classes I've already mentioned, two other classes form the core of LibQ's asynchronous I/O system. While I could have (and was originally planning on) making the features applicable to the asynchronous I/O system for internal use only, I ultimately decided they would be useful enough for public use that I'd put some extra care into them and make them part of the public API.
The first of these important features is asynchronous procedure calls (APCs). APCs can be queued to any thread via CThread::QueueAsyncCall, and will be held until the thread calls CThread::DispatchAsyncCalls to dispatch them; at that point, each queued APC function for that thread will be called, before the function returns.
Win32 (both Windows NT and 9x) supports this mechanism natively. APCs are queued to the specified thread with the QueueUserAPC function, and dispatched at any indeterminate point while the thread is in an alertable wait state. An alertable wait state is when the thread is suspended (i.e. sleeping or waiting on an object) but is flagged as alertable (this can only be specified in SleepEx, WaitForSingleObjectEx, and WaitForMultipleObjectsEx). All of those functions will sleep until one of three things happens: the object being waited on becomes signaled (not applicable to SleepEx), the timeout expires, or APCs are executed. CThread uses Win32 APCs on Windows.
Unfortunately, we do not have the luxury of the same decadence in a uniform cross-platform library. POSIX does not natively support APCs (at least not in a form that resembles the Win32 method); the closest thing to Win32 APCs that POSIX supports is message queues, which I chose not to use for the reason that there is no qualitative benefit (and a performance penalty) for using kernel-mode message queues over a user-mode implementation.
The POSIX implementation consists simply of a linked list (a queue) protected by a mutex, and a condition, for each thread. This allows us to approximate the Win32 APC by allowing waits - either timed or indefinite - for APCs. However, it still won't be possible to process APCs while waiting on a synchronization object (although you can simulate this by queuing APCs that do some particular task that would otherwise have been executed when a synchronization object became signaled).
UPDATE: I've just heard some very grave (and unexpected) news. NT pre-4.0 does NOT support QueueUserAPC. This puts a rather sizeable hurdle in the way of this thing, as it leaves two options.
First, I could drop support for NT before 4.0. While I wouldn't hesitate to drop support for NT 3.1 (back from 1993), NT 3.5 was around until 1996 or 1997, making it not THAT old. Of course, it could be argued that new programs will require the Explorer interface that wasn't introduced until NT 4 (it was first released in Windows 95, which preceded NT 4). While it's safe to assume that no new GUI program would use the Windows 3.1 GUI (which NT 3.1 and 3.5 had), this isn't the case for programs (or libraries) that don't have a GUI.
The other alternative is to create a hybrid list/APC system. NT has always supported APCs for asynchronous I/O notification; however, it wasn't until 4.0 that you could send your own APCs. In order to pull this off, I'd have to implement a hybrid condition variable-type-thingy that waits on the condition in an alertable state (and perhaps even throw a timeout in there for good measure). This would be messy, to say the least, and it could take 2 kernel mode transitions just to be sure all bases are covered (if WaitForSingleObjectEx returns WAIT_OBJECT_0 you can't be sure that there weren't APCs that didn't get executed, and if it returns WAIT_IO_COMPLETION you can't be sure that the object wasn't signaled), making it slower.
I'm leaning towards requiring NT 4.
Apart from the classes I've already mentioned, two other classes form the core of LibQ's asynchronous I/O system. While I could have (and was originally planning on) making the features applicable to the asynchronous I/O system for internal use only, I ultimately decided they would be useful enough for public use that I'd put some extra care into them and make them part of the public API.
The first of these important features is asynchronous procedure calls (APCs). APCs can be queued to any thread via CThread::QueueAsyncCall, and will be held until the thread calls CThread::DispatchAsyncCalls to dispatch them; at that point, each queued APC function for that thread will be called, before the function returns.
Win32 (both Windows NT and 9x) supports this mechanism natively. APCs are queued to the specified thread with the QueueUserAPC function, and dispatched at any indeterminate point while the thread is in an alertable wait state. An alertable wait state is when the thread is suspended (i.e. sleeping or waiting on an object) but is flagged as alertable (this can only be specified in SleepEx, WaitForSingleObjectEx, and WaitForMultipleObjectsEx). All of those functions will sleep until one of three things happens: the object being waited on becomes signaled (not applicable to SleepEx), the timeout expires, or APCs are executed. CThread uses Win32 APCs on Windows.
Unfortunately, we do not have the luxury of the same decadence in a uniform cross-platform library. POSIX does not natively support APCs (at least not in a form that resembles the Win32 method); the closest thing to Win32 APCs that POSIX supports is message queues, which I chose not to use for the reason that there is no qualitative benefit (and a performance penalty) for using kernel-mode message queues over a user-mode implementation.
The POSIX implementation consists simply of a linked list (a queue) protected by a mutex, and a condition, for each thread. This allows us to approximate the Win32 APC by allowing waits - either timed or indefinite - for APCs. However, it still won't be possible to process APCs while waiting on a synchronization object (although you can simulate this by queuing APCs that do some particular task that would otherwise have been executed when a synchronization object became signaled).
UPDATE: I've just heard some very grave (and unexpected) news. NT pre-4.0 does NOT support QueueUserAPC. This puts a rather sizeable hurdle in the way of this thing, as it leaves two options.
First, I could drop support for NT before 4.0. While I wouldn't hesitate to drop support for NT 3.1 (back from 1993), NT 3.5 was around until 1996 or 1997, making it not THAT old. Of course, it could be argued that new programs will require the Explorer interface that wasn't introduced until NT 4 (it was first released in Windows 95, which preceded NT 4). While it's safe to assume that no new GUI program would use the Windows 3.1 GUI (which NT 3.1 and 3.5 had), this isn't the case for programs (or libraries) that don't have a GUI.
The other alternative is to create a hybrid list/APC system. NT has always supported APCs for asynchronous I/O notification; however, it wasn't until 4.0 that you could send your own APCs. In order to pull this off, I'd have to implement a hybrid condition variable-type-thingy that waits on the condition in an alertable state (and perhaps even throw a timeout in there for good measure). This would be messy, to say the least, and it could take 2 kernel mode transitions just to be sure all bases are covered (if WaitForSingleObjectEx returns WAIT_OBJECT_0 you can't be sure that there weren't APCs that didn't get executed, and if it returns WAIT_IO_COMPLETION you can't be sure that the object wasn't signaled), making it slower.
I'm leaning towards requiring NT 4.
Thursday, October 20, 2005
Watch Where You Poke
So, today I had an interesting (and awkward) experience. If you've ever seen me play air hockey, you know I'm pretty good, despite the fact that I play maybe once a year. I think one of the main reasons for that is that I'm pretty good with my peripheral vision. This shows up in my daily life, as I'll often not look directly at what I'm "looking at" unless there's a particular reason to do so (i.e. being able to see it very clearly).
Well, this can be taken too far, it appears. So, my social psychology class just ended (my last class for the day, and I wanted to get out of there as much as everyone else did), and I was picking up my backpack to go (I was sitting in the front row). So, I pick up the backpack, sling it over my right shoulder, and insert left arm through the strap. In my usual manner, I was spotting the location of the strap with my peripheral vision - I only needed to see the location of the strap, I didn't need to focus on it.
So, insert the left arm and... *squish* Uh oh, that can't be a good thing. Now aware that there was somebody much closer to me than I was aware of (less than 18 inches), I looked to see who this was. Given the 50:50 chance, it was only a surprise in these particular circumstances that it was a girl. That's right, I'd just felt some girl up. Fortunately, she either comprehended exactly what had happened, or was too polite to say anything while I quickly apologized and slinked out of the building.
So, the moral of the story: watch where you're sticking your hands when there are other people present.
Well, this can be taken too far, it appears. So, my social psychology class just ended (my last class for the day, and I wanted to get out of there as much as everyone else did), and I was picking up my backpack to go (I was sitting in the front row). So, I pick up the backpack, sling it over my right shoulder, and insert left arm through the strap. In my usual manner, I was spotting the location of the strap with my peripheral vision - I only needed to see the location of the strap, I didn't need to focus on it.
So, insert the left arm and... *squish* Uh oh, that can't be a good thing. Now aware that there was somebody much closer to me than I was aware of (less than 18 inches), I looked to see who this was. Given the 50:50 chance, it was only a surprise in these particular circumstances that it was a girl. That's right, I'd just felt some girl up. Fortunately, she either comprehended exactly what had happened, or was too polite to say anything while I quickly apologized and slinked out of the building.
So, the moral of the story: watch where you're sticking your hands when there are other people present.
Friday, October 14, 2005
Asynchronous I/O - The LibQ Way
Okay, so now that I've talked about the challenges in asynchronous I/O, let me explain my solution (the interface, at least; will discuss the implementation later). First of all let me state that this is the working draft of the interface; function names in particular are not final, and the interface may change somewhat.
LibQ supports asynchronous I/O on all OS, and supports all three notifications methods: event notification, completion callbacks, and completion ports.
CAsyncStatus
The object-oriented state of an asynchronous I/O operation. May be either unused, pending, or completed. When completed, contains the information such as the success/failure status of the operation and the number of bytes transferred, as well as the original information about the I/O offset, file, etc. Allocated and freed by the caller, and may be inherited to add caller-owned data associated with the operation.
CCompletionPort
An I/O completion port. Can be associated with one or more files that it should receive completion notifications for. Can be used to retrieve a queued completion (in the form of a CAsyncStatus) or waited on until the next notification is queued (if none are already queued).
CAsyncFile
The class for a file opened for asynchronous I/O. Synchronous I/O is done using Read and Write; asynchronous I/O is done using RequestRead and RequestWrite, both taking a CAsyncStatus for the operation, as well as a CEvent to set or a callback function to call on completion (if neither is specified, the completion notification will be queued on the file's CCompletionPort). The CAsyncStatus must remain valid until the operation is complete.
Completion callbacks are queued to the thread that called RequestRead/RequestWrite, and are not actually called until DispatchNotifications is called from that thread, when all queued notification callbacks are called for that thread.
Uncompleted I/O requests can be cancelled for a file in all threads by calling CAsyncFile::CancelAllIo for that file.
LibQ supports asynchronous I/O on all OS, and supports all three notifications methods: event notification, completion callbacks, and completion ports.
CAsyncStatus
The object-oriented state of an asynchronous I/O operation. May be either unused, pending, or completed. When completed, contains the information such as the success/failure status of the operation and the number of bytes transferred, as well as the original information about the I/O offset, file, etc. Allocated and freed by the caller, and may be inherited to add caller-owned data associated with the operation.
CCompletionPort
An I/O completion port. Can be associated with one or more files that it should receive completion notifications for. Can be used to retrieve a queued completion (in the form of a CAsyncStatus) or waited on until the next notification is queued (if none are already queued).
CAsyncFile
The class for a file opened for asynchronous I/O. Synchronous I/O is done using Read and Write; asynchronous I/O is done using RequestRead and RequestWrite, both taking a CAsyncStatus for the operation, as well as a CEvent to set or a callback function to call on completion (if neither is specified, the completion notification will be queued on the file's CCompletionPort). The CAsyncStatus must remain valid until the operation is complete.
Completion callbacks are queued to the thread that called RequestRead/RequestWrite, and are not actually called until DispatchNotifications is called from that thread, when all queued notification callbacks are called for that thread.
Uncompleted I/O requests can be cancelled for a file in all threads by calling CAsyncFile::CancelAllIo for that file.
Thursday, October 13, 2005
Very Clever
So, I was writing a little helper class to use in later projects. It's a chain link class to be used in the construction of circular linked lists. So, I wanted to see what the optimized assembly VC++ would generate would look like. The class and the test function are shown below:
Well, VC++ really pulled a fast one on me. In the end, I didn't learn what I was looking for, but I did see VC++ do some clever optimization. Have a look at the assembly it generated:
CChainLink A, B, C, D, E;
A.SpliceNext(B);
00401868 8D 4C 24 24 lea ecx,[esp+24h]
0040186C 89 4C 24 20 mov dword ptr [esp+20h],ecx
B.SpliceNext(C);
00401870 8D 54 24 14 lea edx,[esp+14h]
00401874 89 54 24 1C mov dword ptr [esp+1Ch],edx
00401878 8D 44 24 1C lea eax,[esp+1Ch]
D.SpliceNext(E);
0040187C 8D 4C 24 04 lea ecx,[esp+4]
00401880 8D 54 24 0C lea edx,[esp+0Ch]
00401884 89 4C 24 0C mov dword ptr [esp+0Ch],ecx
C.SpliceNext(D);
00401888 8B CA mov ecx,edx
0040188A 89 44 24 24 mov dword ptr [esp+24h],eax
0040188E 89 44 24 18 mov dword ptr [esp+18h],eax
00401892 8D 44 24 24 lea eax,[esp+24h]
00401896 89 4C 24 14 mov dword ptr [esp+14h],ecx
0040189A 89 54 24 08 mov dword ptr [esp+8],edx
0040189E 89 44 24 04 mov dword ptr [esp+4],eax
SLIST_HEADER asdfgh;
SLIST_ENTRY lkjhg;
InitializeSListHead(&asdfgh);
004018A2 8D 4C 24 2C lea ecx,[esp+2Ch]
004018A6 8D 54 24 04 lea edx,[esp+4]
004018AA 8D 44 24 14 lea eax,[esp+14h]
004018AE 51 push ecx
004018AF C7 44 24 40 04 00 00 00 mov dword ptr [esp+40h],4
004018B7 89 54 24 2C mov dword ptr [esp+2Ch],edx
004018BB 89 44 24 14 mov dword ptr [esp+14h],eax
004018BF FF 15 38 B0 40 00 call dword ptr [__imp__InitializeSListHead@4 (40B038h)]
class CChainLink
{
protected:
CChainLink *m_pNext;
CChainLink *m_pPrev;
// Swap pointers to links
inline static void SwapLinks(CChainLink **ppFirst, CChainLink **ppSecond)
{
assert(ppFirst);
assert(*ppFirst);
assert(ppSecond);
assert(*ppSecond);
CChainLink *pTemp = *ppFirst;
*ppFirst = *ppSecond;
*ppSecond = pTemp;
}
public:
inline CChainLink()
{
m_pNext = m_pPrev = this;
}
inline ~CChainLink()
{
SpliceOut();
}
// Removes self from the chain
inline void SpliceOut()
{
CChainLink &prev = *m_pPrev, &next = *m_pNext;
SwapLinks(&prev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &m_pPrev);
}
// Inserts the chain beginning with link between the current link and the next link
inline void SpliceNext(CChainLink &link)
{
assert(&link != this);
CChainLink &linkPrev = *link.m_pPrev, &next = *m_pNext;
SwapLinks(&linkPrev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &link.m_pPrev);
}
// Inserts the chain beginning with link between the previous link and the current link
inline void SplicePrev(CChainLink &link)
{
m_pPrev->SpliceNext(link);
}
// Replaces self with the chain beginning with link
inline void SpliceOver(CChainLink &link)
{
assert(&link != this);
SpliceNext(link);
SpliceOut();
}
};
int main(int argc, char* argv[])
{
CChainLink A, B, C, D, E;
A.SpliceNext(B);
B.SpliceNext(C);
D.SpliceNext(E);
C.SpliceNext(D);
// There's actually more test code down here, but I've omitted it since it has nothing to do with the chain class
}
{
protected:
CChainLink *m_pNext;
CChainLink *m_pPrev;
// Swap pointers to links
inline static void SwapLinks(CChainLink **ppFirst, CChainLink **ppSecond)
{
assert(ppFirst);
assert(*ppFirst);
assert(ppSecond);
assert(*ppSecond);
CChainLink *pTemp = *ppFirst;
*ppFirst = *ppSecond;
*ppSecond = pTemp;
}
public:
inline CChainLink()
{
m_pNext = m_pPrev = this;
}
inline ~CChainLink()
{
SpliceOut();
}
// Removes self from the chain
inline void SpliceOut()
{
CChainLink &prev = *m_pPrev, &next = *m_pNext;
SwapLinks(&prev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &m_pPrev);
}
// Inserts the chain beginning with link between the current link and the next link
inline void SpliceNext(CChainLink &link)
{
assert(&link != this);
CChainLink &linkPrev = *link.m_pPrev, &next = *m_pNext;
SwapLinks(&linkPrev.m_pNext, &m_pNext);
SwapLinks(&next.m_pPrev, &link.m_pPrev);
}
// Inserts the chain beginning with link between the previous link and the current link
inline void SplicePrev(CChainLink &link)
{
m_pPrev->SpliceNext(link);
}
// Replaces self with the chain beginning with link
inline void SpliceOver(CChainLink &link)
{
assert(&link != this);
SpliceNext(link);
SpliceOut();
}
};
int main(int argc, char* argv[])
{
CChainLink A, B, C, D, E;
A.SpliceNext(B);
B.SpliceNext(C);
D.SpliceNext(E);
C.SpliceNext(D);
// There's actually more test code down here, but I've omitted it since it has nothing to do with the chain class
}
Well, VC++ really pulled a fast one on me. In the end, I didn't learn what I was looking for, but I did see VC++ do some clever optimization. Have a look at the assembly it generated:
CChainLink A, B, C, D, E;
A.SpliceNext(B);
00401868 8D 4C 24 24 lea ecx,[esp+24h]
0040186C 89 4C 24 20 mov dword ptr [esp+20h],ecx
B.SpliceNext(C);
00401870 8D 54 24 14 lea edx,[esp+14h]
00401874 89 54 24 1C mov dword ptr [esp+1Ch],edx
00401878 8D 44 24 1C lea eax,[esp+1Ch]
D.SpliceNext(E);
0040187C 8D 4C 24 04 lea ecx,[esp+4]
00401880 8D 54 24 0C lea edx,[esp+0Ch]
00401884 89 4C 24 0C mov dword ptr [esp+0Ch],ecx
C.SpliceNext(D);
00401888 8B CA mov ecx,edx
0040188A 89 44 24 24 mov dword ptr [esp+24h],eax
0040188E 89 44 24 18 mov dword ptr [esp+18h],eax
00401892 8D 44 24 24 lea eax,[esp+24h]
00401896 89 4C 24 14 mov dword ptr [esp+14h],ecx
0040189A 89 54 24 08 mov dword ptr [esp+8],edx
0040189E 89 44 24 04 mov dword ptr [esp+4],eax
SLIST_HEADER asdfgh;
SLIST_ENTRY lkjhg;
InitializeSListHead(&asdfgh);
004018A2 8D 4C 24 2C lea ecx,[esp+2Ch]
004018A6 8D 54 24 04 lea edx,[esp+4]
004018AA 8D 44 24 14 lea eax,[esp+14h]
004018AE 51 push ecx
004018AF C7 44 24 40 04 00 00 00 mov dword ptr [esp+40h],4
004018B7 89 54 24 2C mov dword ptr [esp+2Ch],edx
004018BB 89 44 24 14 mov dword ptr [esp+14h],eax
004018BF FF 15 38 B0 40 00 call dword ptr [__imp__InitializeSListHead@4 (40B038h)]
Asynchronous I/O - Taking Inventory
At some point in the distant past, I discussed the three basic methods of asynchronous I/O completion notification: events, callback functions, and notification ports. Now I want to talk about the difficulties in implementing a single cross-platform asynchronous I/O API; phrased differently, I want to explain what OS implement what.
To me, there are four major OS - Windows NT, Windows 9x, Linux, and OS X - separated into three platforms (as far as LibQ is concerned) - Windows NT, Windows 9x, and POSIX. While 9x is getting up there in age, I'm still not comfortable dropping support for it yet.
To varying extents, Windows (both NT and 9x) supports asynchronous I/O and both event and callback-based notifications. Callbacks are handled in somewhat of a novel way: when the I/O operation completes or fails, a callback notification is queued for that operation as a user-mode asynchronous procedure call (APC) to the thread that started the operation. When the thread goes into an alertable waitstate (that is, using WaitForSingleObjectEx and kin) the APCs for that thread are executed, and the callback is called. This has some interesting (and actually pretty nice) properties. First, it ensures that callbacks will only be called when the program wants them to be called. It also has the advantage that the callbacks will always be called from the thread that initiated the I/O; in the best cases, this means that no cross-thread data protection must be done. Furthermore, calls to cancel pending I/O affect I/O operations issued by that thread, only.
Windows 9x is possibly the most primitive of the three platforms - it's something of a cross between Windows 3.1 (16-bit Windows) and NT (32-bit Windows). Although it supports both event and callback-based notifications, 9x supports asynchronous I/O only on sockets (and a couple other minor items you're not likely to ever use).
Windows NT is the true 32-bit Windows. It's a completely new code-base to go with a new archetecture (although Microsoft attempted to make it as backward compatible as possible). In the NT kernel, all I/O is asynchronous, and synchronous I/O is nothing more than suspending threads while their I/O gets processed. NT is the only platform that supports all three modes of asynchronous notifications (although the very first version of NT - 3.1 - did not support notification ports).
POSIX is quite another beast altogether. To begin with, unlike Windows NT and 9x, POSIX is a vague standard, rather than an actual platform. Furthermore, asynchronous I/O is considered an option in POSIX, which does not need to be supported by any POSIX-compliant OS; this fact is illustrated in many places. Linux did not support asynchronous I/O in the kernel until version 2.6 (the current version; it was actually added in 2.5, but that was an unstable developer version); OS X did not support the POSIX asynchronous I/O functions until version 10.4 (the current version). And even those platforms that do support the POSIX functions remain limited by the standard itself; of our three methods of completion notification, POSIX only supports callback functions. As well, what features it does provide are wholly incompatible with the Windows feature set. There is no guarantee when or in what thread completion callbacks will arrive. Even more problematic is that POSIX provides no way to cancel pending I/O for a single thread; only a method to cancel all I/O for a file.
So, all in all, it's a huge mess. This is perhaps the area of LibQ that I'm most excited about, and put the most thought into (and I haven't even started to code it, yet). Some of the solutions I've come up with are very elegant, and I take pride in them; others are simply the best of the possible bad options, and I'd rather forget that I have to go with them.
To me, there are four major OS - Windows NT, Windows 9x, Linux, and OS X - separated into three platforms (as far as LibQ is concerned) - Windows NT, Windows 9x, and POSIX. While 9x is getting up there in age, I'm still not comfortable dropping support for it yet.
To varying extents, Windows (both NT and 9x) supports asynchronous I/O and both event and callback-based notifications. Callbacks are handled in somewhat of a novel way: when the I/O operation completes or fails, a callback notification is queued for that operation as a user-mode asynchronous procedure call (APC) to the thread that started the operation. When the thread goes into an alertable waitstate (that is, using WaitForSingleObjectEx and kin) the APCs for that thread are executed, and the callback is called. This has some interesting (and actually pretty nice) properties. First, it ensures that callbacks will only be called when the program wants them to be called. It also has the advantage that the callbacks will always be called from the thread that initiated the I/O; in the best cases, this means that no cross-thread data protection must be done. Furthermore, calls to cancel pending I/O affect I/O operations issued by that thread, only.
Windows 9x is possibly the most primitive of the three platforms - it's something of a cross between Windows 3.1 (16-bit Windows) and NT (32-bit Windows). Although it supports both event and callback-based notifications, 9x supports asynchronous I/O only on sockets (and a couple other minor items you're not likely to ever use).
Windows NT is the true 32-bit Windows. It's a completely new code-base to go with a new archetecture (although Microsoft attempted to make it as backward compatible as possible). In the NT kernel, all I/O is asynchronous, and synchronous I/O is nothing more than suspending threads while their I/O gets processed. NT is the only platform that supports all three modes of asynchronous notifications (although the very first version of NT - 3.1 - did not support notification ports).
POSIX is quite another beast altogether. To begin with, unlike Windows NT and 9x, POSIX is a vague standard, rather than an actual platform. Furthermore, asynchronous I/O is considered an option in POSIX, which does not need to be supported by any POSIX-compliant OS; this fact is illustrated in many places. Linux did not support asynchronous I/O in the kernel until version 2.6 (the current version; it was actually added in 2.5, but that was an unstable developer version); OS X did not support the POSIX asynchronous I/O functions until version 10.4 (the current version). And even those platforms that do support the POSIX functions remain limited by the standard itself; of our three methods of completion notification, POSIX only supports callback functions. As well, what features it does provide are wholly incompatible with the Windows feature set. There is no guarantee when or in what thread completion callbacks will arrive. Even more problematic is that POSIX provides no way to cancel pending I/O for a single thread; only a method to cancel all I/O for a file.
So, all in all, it's a huge mess. This is perhaps the area of LibQ that I'm most excited about, and put the most thought into (and I haven't even started to code it, yet). Some of the solutions I've come up with are very elegant, and I take pride in them; others are simply the best of the possible bad options, and I'd rather forget that I have to go with them.
Wednesday, October 12, 2005
& Too Much Stuff
So many things to work on, so little time. Just to name a few:
- experiment more with Java, C#, and JavaScript
- make many posts about my CPU archetecture
- get back to posting about reader-writer locks
- post about things I learned about the first amendment this semester in world history
- get up to date with the progress on the room we're building here over the last 4 or 5 weeks
- post a series about endians and endian conversion functions
- get back to working on LibQ (I'd particularly like to work on the I/O portion, especially the asynchronous I/O classes)
- finish the paper for social psychology due tomorrow
- study for my history test tomorrow
But I suspect I'll just play WoW instead :P
Incidentally, an old friend of mine that I haven't talked to in quite a while (he's a console programmer) is working on some interesting programming projects (the kind of thing I might do). One of the projects is a converter that takes an XML data file and schema and compiles it to a memory image file that can be loaded directly into memory without parsing (although some pointer fixups may be needed). This is kinda like what Diablo II does, using data files compiled from SYLK spreadsheets, although more general.
- experiment more with Java, C#, and JavaScript
- make many posts about my CPU archetecture
- get back to posting about reader-writer locks
- post about things I learned about the first amendment this semester in world history
- get up to date with the progress on the room we're building here over the last 4 or 5 weeks
- post a series about endians and endian conversion functions
- get back to working on LibQ (I'd particularly like to work on the I/O portion, especially the asynchronous I/O classes)
- finish the paper for social psychology due tomorrow
- study for my history test tomorrow
But I suspect I'll just play WoW instead :P
Incidentally, an old friend of mine that I haven't talked to in quite a while (he's a console programmer) is working on some interesting programming projects (the kind of thing I might do). One of the projects is a converter that takes an XML data file and schema and compiles it to a memory image file that can be loaded directly into memory without parsing (although some pointer fixups may be needed). This is kinda like what Diablo II does, using data files compiled from SYLK spreadsheets, although more general.
Tuesday, October 11, 2005
& The Tides of Darkness
So, yesterday was Monday. And for me that often means it's time to find a new music CD to stick in my car (I usually change the CD every week or two). The flavor of the week is Warcraft II. As I have at least 50 soundtracks to choose from, it takes a couple years for me to stick in the same CD twice; this is one of those times. Well, the same thing happened as the last time I put it in: I was awe-struck by how awesome the music is, and why it remains on my list of favorite soundtracks. It was composed by Glenn Stafford, who also did some music on Starcraft, Warcraft III, and Diablo II; however, the Warcraft II music remains his best work.
Here are a couple tracks ripped from the CD (although only 128 kbps MP3):
Human Track 3
Orc Track 2
The legendary Title Theme
Unfortunately, acquiring this music (legally) is rather difficult. The original Warcraft II: Tides of Darkness and Beyond the Dark Portal (the expansion, which contains 3 tracks the original does not) contain the music in beautiful CD audio (what I play in my car) quality; these DOS versions, however, are almost a decade old, and no longer for sale. Warcraft II: Battle.Net Edition (the updated Windows version), contains the music in butchered, 22 khz, lossy ADPCM (and low quality, at that), which would only be acceptable if you're not a big fan of music, and if there was absolutely no other choice.
In other news, my latest shipment of manga arrived today: Yotsuba &! 3, Trigun Maximum 3 and 4, Ai Yori Aoshi 9, the Madlax OST 1 (2 won't be out in the US till next month), Batman Begins OST, and Harry Potter and the Prisoner of Azkaban OST (both of the last two are movies I've never seen or heard the music to, but they're by composers I like, and rated well).
Also, while I was writing this post up, this amusing exchange occurred in WoW (you'll have to click on the images to bring them to full size):
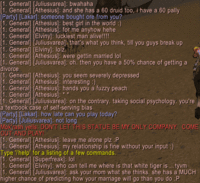
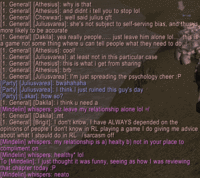
Here are a couple tracks ripped from the CD (although only 128 kbps MP3):
Human Track 3
Orc Track 2
The legendary Title Theme
Unfortunately, acquiring this music (legally) is rather difficult. The original Warcraft II: Tides of Darkness and Beyond the Dark Portal (the expansion, which contains 3 tracks the original does not) contain the music in beautiful CD audio (what I play in my car) quality; these DOS versions, however, are almost a decade old, and no longer for sale. Warcraft II: Battle.Net Edition (the updated Windows version), contains the music in butchered, 22 khz, lossy ADPCM (and low quality, at that), which would only be acceptable if you're not a big fan of music, and if there was absolutely no other choice.
In other news, my latest shipment of manga arrived today: Yotsuba &! 3, Trigun Maximum 3 and 4, Ai Yori Aoshi 9, the Madlax OST 1 (2 won't be out in the US till next month), Batman Begins OST, and Harry Potter and the Prisoner of Azkaban OST (both of the last two are movies I've never seen or heard the music to, but they're by composers I like, and rated well).
Also, while I was writing this post up, this amusing exchange occurred in WoW (you'll have to click on the images to bring them to full size):

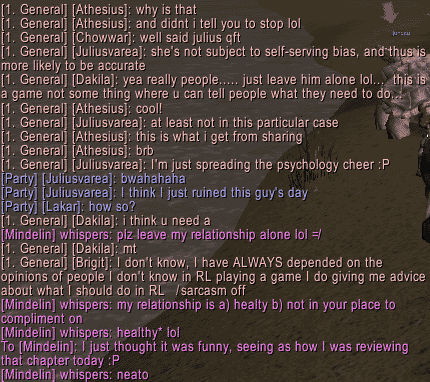
Monday, October 10, 2005
One Language to Rule Them All - Java
For a long time I'd been hoping to add a scripting language to LibQ, to use in any of my (or other people's) projects that needed a scripting language. The ideal scripting language would be well known, portable (that is, the interpreter code should be portable), flexible, and easy to interface with. However, just in the last couple days, I've come up with arguably my most insane idea ever for a programming project. While I don't think I'll discuss the idea here, let's say that one of the staples of this project would be LARGE scripts, making speed a requirement as well.
Given all these criteria, two languages jumped to mind: Java and C#. Both of these languages are well known (although Java significantly more than C#), flexible, portable (again Java more than C#), and fairly easy to interface with (C# more than Java, actually). You'll also notice that these are less than conventional choices for scripting languages... that is, they're NOT scripting languages, but rather compiled languages. This was how I thought would be the best way to meet the speed requirement, as they'll run circles around interpreted languages (probably at least 10x as fast).
So, first we examine Java. Java is perhaps the most well known programming language today (possibly second to C/C++), and Sun makes a virtual machine for all major OSs, as well as the minor OSs. Benchmarks I did a year or two ago showed that Java executed equivalent computational code at about half the speed of native code (that is, it took twice as long to execute). What I really didn't know is how easy it was to interface with. So, I looked up the Java Native Interface on Sun's Java site, and started playing. It turns out that it's quite easy to host a Java virtual machine and interact with it.
Benchmarks showed that it took about 450 cycles to call a native function from Java code, and about 3100 cycles to call a Java function from native code. 450 cycles isn't bad, but 3100 cycles is a bit slow (at least for said programming project). Also, there doesn't appear to be a programmatic interface to the Java compiler (Java code is compiled in two steps; first the source code is compiled to Java "machine language", and this code is what Java programs are usually distributed as; then, at run time, the Java machine language is compiled to true machine language for the machine the program is executed on). This might be okay for some things (i.e. game scripts, where the scripts could be distributed in compiled form), but it's not a good thing for simple scripts (i.e. batch files).
UPDATE: I could have sworn I fixed that "Java makes a virtual machine" mistake this morning, when I was proof-reading it...
Given all these criteria, two languages jumped to mind: Java and C#. Both of these languages are well known (although Java significantly more than C#), flexible, portable (again Java more than C#), and fairly easy to interface with (C# more than Java, actually). You'll also notice that these are less than conventional choices for scripting languages... that is, they're NOT scripting languages, but rather compiled languages. This was how I thought would be the best way to meet the speed requirement, as they'll run circles around interpreted languages (probably at least 10x as fast).
So, first we examine Java. Java is perhaps the most well known programming language today (possibly second to C/C++), and Sun makes a virtual machine for all major OSs, as well as the minor OSs. Benchmarks I did a year or two ago showed that Java executed equivalent computational code at about half the speed of native code (that is, it took twice as long to execute). What I really didn't know is how easy it was to interface with. So, I looked up the Java Native Interface on Sun's Java site, and started playing. It turns out that it's quite easy to host a Java virtual machine and interact with it.
Benchmarks showed that it took about 450 cycles to call a native function from Java code, and about 3100 cycles to call a Java function from native code. 450 cycles isn't bad, but 3100 cycles is a bit slow (at least for said programming project). Also, there doesn't appear to be a programmatic interface to the Java compiler (Java code is compiled in two steps; first the source code is compiled to Java "machine language", and this code is what Java programs are usually distributed as; then, at run time, the Java machine language is compiled to true machine language for the machine the program is executed on). This might be okay for some things (i.e. game scripts, where the scripts could be distributed in compiled form), but it's not a good thing for simple scripts (i.e. batch files).
UPDATE: I could have sworn I fixed that "Java makes a virtual machine" mistake this morning, when I was proof-reading it...
Subscribe to:
Posts (Atom)

