Ambiguities are fun (and troublesome) in any language, but when you're designing a language from scratch, they tend to be even more fun, as now it's YOUR fault that they exist. Lately I've been spending a moderate amount of thought trying to solve a problem.
Let us take the following classic phrase from IRC and syntactically translate it into Caia:
'the holy castrating sledgehammer'
That seems relatively unambiguous in English, thanks to the intuitive meaning of the word order used. In Caia, however, there are almost no true adjectives, as Caia instead forms pseudo-adjectives by relating one noun to another with an attributive particle ("of"); true adjectives are things which do not have an acceptable noun form (things like "more"). Thus, in Caia it would look something like this:
'sledgehammer of holiness of castration'
Now that looks a bit frightening even in English, although it's even worse in Caia. The most intuitive interpretation of this phrase, in Caia, would be 'sledgehammer of (holiness of castration)' (parentheses added as an indicator of how the syntax tree would be formed), suggesting that it is the holiness that is being castrated - something along the lines of "sledgehammer of castrated holiness".
'sledgehammer of castration of holiness' is no better. This implies that holiness is a property of castration. More freely translated, it would sound something like "sledgehammer of holy castration", which is also not what we are trying to say.
Caia has something called delimiting particles, which act like the parentheses used earlier to illustrate word grouping - they indicate that everything in between the delimiters should be treated as a single syntactic unit, with regard to the rest of the sentence. While this can be handy for longer things such as relative (noun) clauses ("the house that Jack built with his own hands"), the fact that they must be paired makes them annoyingly cumbersome to use for simpler relations.
Another possible "solution" would be to make a list of the pseudo-adjectives like so:
'sledgehammer of holiness and castration'
This, however, presents a similar problem in a different place: is castration in a list along with holiness ('sledgehammer of (holiness and castration)' - what we're actually looking for) or with the sledgehammer ('(sledgehammer of holiness) and castration')?
That problem made me think quite a bit, and I believe I've come up with a solution: the disjoining particle. The disjoining particle does exactly the opposite of what the delimiting particles do: rather than indicating that a block of words go together syntactically, the disjoining particle indicates that a group of words do NOT go together. Speaking with regards to the syntactic tree, the disjoining particle indicates that the attachment for the following words is not the previous word (as we would intuitively assume), but rather the syntactic parent of the previous word. In this case, the syntactic part of "holiness" is "sledgehammer". Thus, the following unambiguously represents the phrase we were trying to translate (and, in fact, you could switch holiness and castration and have the same meaning):
'sledgehammer of holiness DISJOINING_PARTICLE of castration'
This is not limited to single word shifts. Suppose, for illustration's sake (this wouldn't actually happen in Caia, as the particles for attribution and ownership are different) we tried to translate the following:
'Justin's holy castrating sledgehammer'
The correct and unambiguous translation would be the following (actually, you could put the relations in any order and retain the same meaning):
'sledgehammer of Justin DISJOINING_PARTICLE of holiness DISJOINING_PARTICLE of castration'
Of course, now that we've added two disjoining particles and two duplicated attributive particles, it might be more elegant (and would require no more words; in fact, if we had one more attribute to attach to sledgehammer it would actually come out to be less words) to just use the delimiters and conjunctions as follows:
'sledgehammer of (Justin and holiness and castration)'
Monday, October 09, 2006
Friday, October 06, 2006
Script Fun
So I was making my daily blog rounds and came upon this on Narges' blog. Seeing the opportunity to make a quip, I pounced on the reply button. And by the time I realized I'd entered into something (not having looked at the reply count before posting), I'd won this:

That's "Justin" (or some odd-sounding accented version of it) written in Persian script. Persian for the most part uses the same alphabet as Arabic, but it adds a couple of letters and changes a couple pronunciations.
I don't know if I've ever mentioned it on the blog, but I've mentioned it in IMs and forums: I think Arabic script is the prettiest writing system I've seen; Tengwar takes second (even though it's not a real-world script). Din dabireh and Devanāgarī get honorable mentions.
And I know I've mentioned it to a few different people on IM, but I'm not sure if I've mentioned it on the blog, but I've experimented with making a few scripts myself, some experimental (just to try out a theme), others are intended to actually be used.
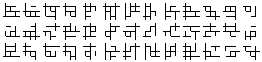
These are called S-Runes. I was originally going for something like Chinese characters, but based on mathematical formula. This was an experimental character set. Originally they were written at about a 30 degree slant, but that didn't work at all with a computer monitor, so I made them straight horizontal and vertical.

Some early sketches of the S-Runes, back when they were still slanted:
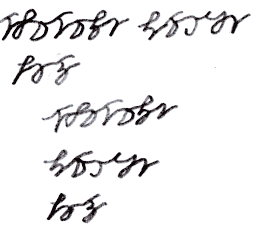
Next is another experimental script. This one was based on simple multiplicative complexity: using combinations of 1/3 top and 2/3 bottom glyphs to form each character, occasionally forming things that don't look exactly like the combination would lead you to expect.
There was a third experimental script based on a tic-tac-toe board (no, you're probably not correctly imagining what it looks like), but I'm not sure where the paper I had that written down on is.
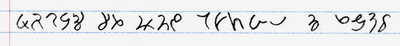
Next is a real script, called something along the lines of Caia hieroglyphics. This was originally to be the official Caia writing system, but I ultimately decided it was too cumbersome to use for a language that is designed for efficiency. It kind of resembles Aramaic script.
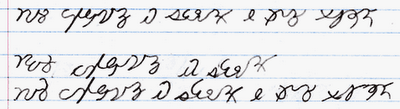
Lastly, the current official Caia script. This is fairly heavily derived from the Caia hieroglyphics, as it was supposed to be kind of like cursive is to printing. Many of the Caia hieroglyphs can be found in some form in Caia script, but a number of them couldn't be adapted well to script form.

That's "Justin" (or some odd-sounding accented version of it) written in Persian script. Persian for the most part uses the same alphabet as Arabic, but it adds a couple of letters and changes a couple pronunciations.
I don't know if I've ever mentioned it on the blog, but I've mentioned it in IMs and forums: I think Arabic script is the prettiest writing system I've seen; Tengwar takes second (even though it's not a real-world script). Din dabireh and Devanāgarī get honorable mentions.
And I know I've mentioned it to a few different people on IM, but I'm not sure if I've mentioned it on the blog, but I've experimented with making a few scripts myself, some experimental (just to try out a theme), others are intended to actually be used.

These are called S-Runes. I was originally going for something like Chinese characters, but based on mathematical formula. This was an experimental character set. Originally they were written at about a 30 degree slant, but that didn't work at all with a computer monitor, so I made them straight horizontal and vertical.

Some early sketches of the S-Runes, back when they were still slanted:

Next is another experimental script. This one was based on simple multiplicative complexity: using combinations of 1/3 top and 2/3 bottom glyphs to form each character, occasionally forming things that don't look exactly like the combination would lead you to expect.
There was a third experimental script based on a tic-tac-toe board (no, you're probably not correctly imagining what it looks like), but I'm not sure where the paper I had that written down on is.
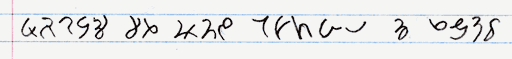
Next is a real script, called something along the lines of Caia hieroglyphics. This was originally to be the official Caia writing system, but I ultimately decided it was too cumbersome to use for a language that is designed for efficiency. It kind of resembles Aramaic script.
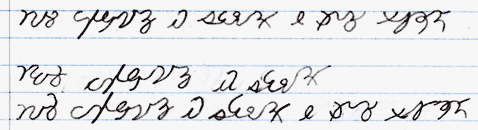
Lastly, the current official Caia script. This is fairly heavily derived from the Caia hieroglyphics, as it was supposed to be kind of like cursive is to printing. Many of the Caia hieroglyphs can be found in some form in Caia script, but a number of them couldn't be adapted well to script form.
Monday, September 25, 2006
Dude, Where's My Blogging?
As those of you keeping count have probably noticed, there hasn't been a whole lot of blogging from me, lately. There's a pretty intuitive reason for that. As I mentioned previously, Squid and I went to Kansas to work for the same company as Skywing over the summer. Skywing's boss (actually the chief technical officer) had invited me to work there out of the blue, while Squid was just bored, and thought out of state travel might amuse him. It came as a surprise, then, that when we arrived, the CTO told Squid that if he was bored and wanted to work for the company as a Q/A person (since his programming abilities aren't really enough to get by at an actual job) he could; only, they didn't have budget to pay him.
As Squid was in fact bored (that and the fact that, for technical reasons, he could only use the internet from the hotel room for the first couple of weeks while I was there), he decided to try working (a relatively new concept for him, although I don't suppose I'm one to talk). So, I worked on my (programming) project for the ten weeks we were there, and he worked for their Q/A "department" (actually only like 3 people, including him).
Well, it turned out that Squid was actually pretty good at Q/A, and at the end of the summer both of us were invited to stay and work full-time for the company, once they managed to find budgets for us (during the summer I was the only one getting paid, and only making an intern's pay). I declined, as I wanted to finish up my last 3 semesters of college (double majors, remember), though I expected to go back over the winter and summer breaks, and work remotely during the school semesters (maybe).
So, we came home, and I started school on August 22. A couple weeks after, however, we got a call from them, regarding some new funding. They wanted me to work remotely to finish the project I'd started during the summer (and wanted it done in three weeks!), and they now had budget for Squid.
So, there are a couple points to this story. First, I'm going to school full-time (taking the same number of units I was in the previous semesters; I also have two project and a term paper due within three weeks from now) and still working part-time, meaning I'm busier than I used to be (and Gord help me if I ever start playing WoW again). Though I'm not sure if it'll last; my project has to be done by next Monday, and I don't know whether they'll want me to work on anything else remotely after it's done (from what I've heard they don't usually let people work remotely).
Second, Squid has accepted the job, and is leaving (for good) on Thursday. I guess if his luggage doesn't explode this time (last time his carry-on suitcase set off the bomb detector), I'll see him around Christmas, if I go back to work there. Amusingly (and surprisingly), it look like his sister may move into his room in the house here, after he moves out. Unfortunately, I don't think she downloads every single anime episode that comes out, like he does (so that I could always just get whatever I wanted from him); oh well :P
As Squid was in fact bored (that and the fact that, for technical reasons, he could only use the internet from the hotel room for the first couple of weeks while I was there), he decided to try working (a relatively new concept for him, although I don't suppose I'm one to talk). So, I worked on my (programming) project for the ten weeks we were there, and he worked for their Q/A "department" (actually only like 3 people, including him).
Well, it turned out that Squid was actually pretty good at Q/A, and at the end of the summer both of us were invited to stay and work full-time for the company, once they managed to find budgets for us (during the summer I was the only one getting paid, and only making an intern's pay). I declined, as I wanted to finish up my last 3 semesters of college (double majors, remember), though I expected to go back over the winter and summer breaks, and work remotely during the school semesters (maybe).
So, we came home, and I started school on August 22. A couple weeks after, however, we got a call from them, regarding some new funding. They wanted me to work remotely to finish the project I'd started during the summer (and wanted it done in three weeks!), and they now had budget for Squid.
So, there are a couple points to this story. First, I'm going to school full-time (taking the same number of units I was in the previous semesters; I also have two project and a term paper due within three weeks from now) and still working part-time, meaning I'm busier than I used to be (and Gord help me if I ever start playing WoW again). Though I'm not sure if it'll last; my project has to be done by next Monday, and I don't know whether they'll want me to work on anything else remotely after it's done (from what I've heard they don't usually let people work remotely).
Second, Squid has accepted the job, and is leaving (for good) on Thursday. I guess if his luggage doesn't explode this time (last time his carry-on suitcase set off the bomb detector), I'll see him around Christmas, if I go back to work there. Amusingly (and surprisingly), it look like his sister may move into his room in the house here, after he moves out. Unfortunately, I don't think she downloads every single anime episode that comes out, like he does (so that I could always just get whatever I wanted from him); oh well :P
Friday, September 22, 2006
Slashdot Go Boom

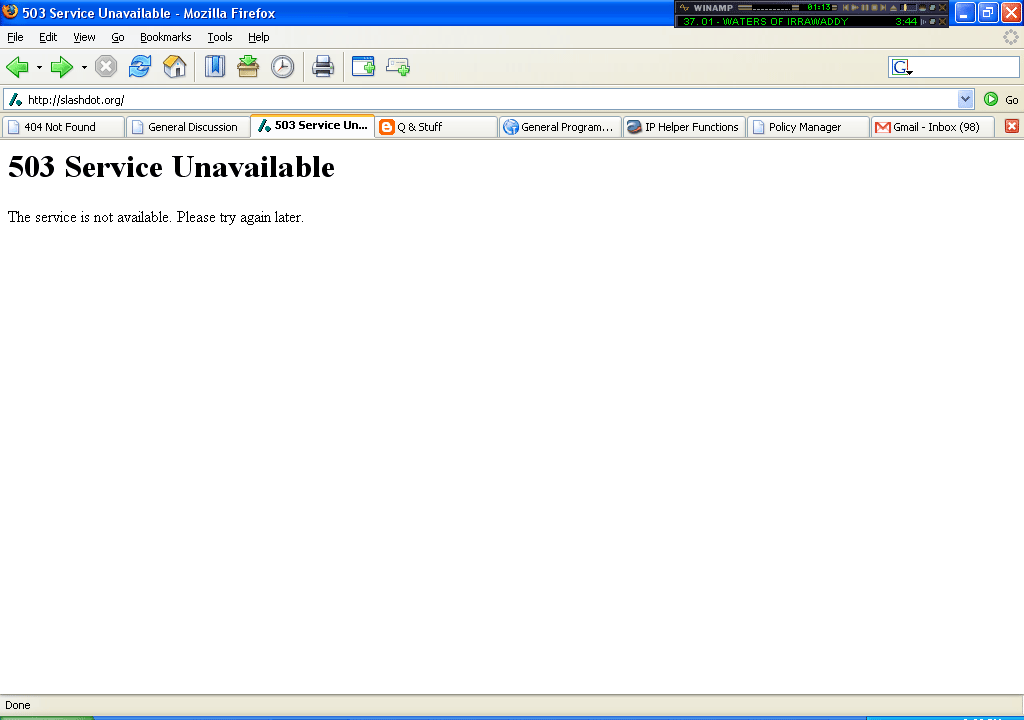
Initiating SYN Stealth Scan against slashdot.org (66.35.250.150) [1 port] at 22:29
Running: Linux 2.4.X|2.6.X
OS details: Linux 2.4.21 (Suse, X86), Linux 2.4.6 - 2.4.21, Linux 2.6.8 (Debian)
Now that's ammunition.
Wednesday, September 20, 2006
Q's Fact of the Day
Blast Processing was a marketing term coined by Sega to advertise the fact that the Sega Mega Drive/Genesis could calculate faster motion than the Super Nintendo Entertainment System and was generally taken by the public to refer to the main system processors. Strictly the term refers to a technical feature of the Genesis that wasn't replicated on the SNES - the ability for the CPU to be working on one visible section of map while the graphics processor displays another. Since only the visible part of the map is uploaded at any one time, this feature greatly increases the distance that the map can scroll from one frame to the next, but few if any people will have been able to discern that meaning from the advertising.http://en.wikipedia.org/wiki/Blast_Processing
I always wondered what that term really meant.
Monday, September 18, 2006
Public Service Announcement
This is Q's public service announcement of the... well, since whenever the last one was. Today I'm writing to warn you about possibly the most idiotic, incompetent bank in the whole world: Wells Fargo. This bank is so special that it's been charging me a monthly service fee on my free savings account (which I only opened because I needed one to get their student credit card, at the time) for several years, now. I've been over there four times to yell at them and tell them to fix it. The first three times it was "I'm so sorry, sir, I'll fix it right now." Lo and behold: bam, monthly service charge on the next month's statement.
The fourth time, however, was a little different (note that it's exactly the same amount of money in the account as there was the last several years, minus their deductions). This time it's "You have less than the minimum balance in your account, sir. Didn't anybody tell you there was a minimum balance fee?" Uh, no. Okay, so I add another $1,400 to the account (several times the minimum balance). Four weeks later: bam, monthly service fee on the account statement.
Now, I'm not positive about what to make of the fact that the first three times I went there nobody mentioned a minimum balance. It could be that their bankers (the ones that have their own desks) are just absolutely clueless about how their bank policies work, and Gord knows what it was they "fixed" when they said they had done so; or, it could be that the minimum balance is a new policy (this is consistent with the fact that I have no recollection of any service charge, and I read all the account information before opening it, but I'm not absolutely positive that I haven't forgotten), in which case it wouldn't explain the first couple years of deductions.
In either case, go put your money into Nigerian banks, people; you'll get ass-raped less than with Wells Fargo. And do make sure to spread the word.
Saturday, September 02, 2006
The Burning Crusade MoPaQs
A few days ago, BZ made me aware of the fact that the World of Warcraft: The Burning Crusade friends and family beta was available for download on the WoW site. As one of the areas of my expertise is the MoPaQ archive format (used by all Blizzard games since Diablo), I immediately wanted to know whether there had been any additions to the format with this new release.
I walked him through all the places he needed to look for additions, as he already had it downloaded and I did not. No new flags in the file table, no new extended attributes. MPQDump reported that there were no new compressions methods in use, nor unusual "system" files. There were, however, 12 new bytes in the MPQ header; unfortunately, they were all 0 in all of the game archives.
To make a long story short, I spent several hours over Thursday and Friday looking at the disassembly and running the thing (the installer, to be specific) with a debugger; I couldn't actually watch the code that used the new fields execute, but I did watch the code around those areas, and tried to put the pieces together in my head.
Finally, I'd completed my analysis, and was ready to update my specs. But I couldn't help but want to verify that everything I'd figured out was correct; but how do you study something when that thing doesn't exist? Well, you make it, and see if it works. And thus began the experiment to create a recombinant MPQ.
I made a list of all the new features in BC, so that I could be sure I tried all of them.
- Pointer to the extended file table
- Large archive support for the hash table pointer
- Large archive support for the file table pointer
- Large archive support for the file pointers
- The shunting system
How to test all of these with minimal effort, while eliminative false negatives and positives? Well, to me, the path of least resistance was fairly obvious: I spliced 4294967296 bytes of garbage directly after the MPQ header. This ensured that every file pointer in the archive would have to be altered, and shifted above the 32-bit file pointer limit present in older MPQs. Because it was exactly 4294967296 bytes, no existing pointers in the file (that is, the low 32 bits of the pointers) would have to be altered; the upper bits just had to be inserted, and they would always be 1. Thus, by simply splicing data there and setting the new fields of the header (two of three of which just needed to be set to 1), I'd knocked all of the three first items off the checklist. However, now I needed to add the high bits to all of the file pointers. This was accomplished simply by appending the proper number of bytes at the end of the archive (2 bytes per file) with the hex pattern 01 00.
But the real clincher would be the shunt. I had, I believed, figured out enough about the shunt to get it to do its thing. However, there were two values from the shunt header that the MPQ API saved in its archive data structure that I couldn't tell where they were used, meaning I couldn't tell HOW they were used. So, all I could do is set the value I knew what it did to what it should be and the value I didn't to 0, and hoped for the best.
After writing recMPQ, a program to perform the recombination on an archive, I ran the program on all three of the installer tomes (installation archives). What better way to verify my understanding than to use the recombinant archives as vectors and attempt a transfection?
I observed the experiment from WinDbg. As the archive was opened, I placed watches on the fields that the unknown portions of the shunt header were saved to, with the hope of being able to find the location of the code that was accessing them. Unfortunately, this failed; the fields were never observed to be accessed.
However, the recombinant MPQs worked perfectly - they were uptaken and their payload delivered without difficulty. Thus, the experiment was a success, and I updated my specs with (most of) the information I'd learned.
I walked him through all the places he needed to look for additions, as he already had it downloaded and I did not. No new flags in the file table, no new extended attributes. MPQDump reported that there were no new compressions methods in use, nor unusual "system" files. There were, however, 12 new bytes in the MPQ header; unfortunately, they were all 0 in all of the game archives.
To make a long story short, I spent several hours over Thursday and Friday looking at the disassembly and running the thing (the installer, to be specific) with a debugger; I couldn't actually watch the code that used the new fields execute, but I did watch the code around those areas, and tried to put the pieces together in my head.
Finally, I'd completed my analysis, and was ready to update my specs. But I couldn't help but want to verify that everything I'd figured out was correct; but how do you study something when that thing doesn't exist? Well, you make it, and see if it works. And thus began the experiment to create a recombinant MPQ.
I made a list of all the new features in BC, so that I could be sure I tried all of them.
- Pointer to the extended file table
- Large archive support for the hash table pointer
- Large archive support for the file table pointer
- Large archive support for the file pointers
- The shunting system
How to test all of these with minimal effort, while eliminative false negatives and positives? Well, to me, the path of least resistance was fairly obvious: I spliced 4294967296 bytes of garbage directly after the MPQ header. This ensured that every file pointer in the archive would have to be altered, and shifted above the 32-bit file pointer limit present in older MPQs. Because it was exactly 4294967296 bytes, no existing pointers in the file (that is, the low 32 bits of the pointers) would have to be altered; the upper bits just had to be inserted, and they would always be 1. Thus, by simply splicing data there and setting the new fields of the header (two of three of which just needed to be set to 1), I'd knocked all of the three first items off the checklist. However, now I needed to add the high bits to all of the file pointers. This was accomplished simply by appending the proper number of bytes at the end of the archive (2 bytes per file) with the hex pattern 01 00.
But the real clincher would be the shunt. I had, I believed, figured out enough about the shunt to get it to do its thing. However, there were two values from the shunt header that the MPQ API saved in its archive data structure that I couldn't tell where they were used, meaning I couldn't tell HOW they were used. So, all I could do is set the value I knew what it did to what it should be and the value I didn't to 0, and hoped for the best.
After writing recMPQ, a program to perform the recombination on an archive, I ran the program on all three of the installer tomes (installation archives). What better way to verify my understanding than to use the recombinant archives as vectors and attempt a transfection?
I observed the experiment from WinDbg. As the archive was opened, I placed watches on the fields that the unknown portions of the shunt header were saved to, with the hope of being able to find the location of the code that was accessing them. Unfortunately, this failed; the fields were never observed to be accessed.
However, the recombinant MPQs worked perfectly - they were uptaken and their payload delivered without difficulty. Thus, the experiment was a success, and I updated my specs with (most of) the information I'd learned.
Friday, September 01, 2006
MoPaQ File Format Spec Updated
I updated my MPQ file format spec today, after pretty much completing my reverse-engineering of the Burning Crusade modifications to the format (which started on Thursday, after I found out that the BC beta was out). Also, the spec has a new home, now that CC has bit the dust (or at least the old site did) - on BZ's wiki.
Tuesday, August 22, 2006
Forgeted to Mention
I be back in California, now. After ten weeks of me being in Kansas, working for SW's company, Dorkess and Bigg'ns (my dog) sure beed happy to see me. It beed fun. I geted to work on a tool that attempt to auto-configur their server; I doed not quite hav enough time to finish it, but I finished all the major stuff, and all that be left be a bunch of odds and ends. I be hoping that I canill go back to work there during the coming winter and summer break, between school semesters.
Which bring up the fact that I be back in school for the fall semester. Three courses that probably beill boring, and one (operating systems concepts) that possibly might be intereting, if I don't already know most of the stuff the course beill teaching. Stuff like scheduling, synchronization, I/O, memory managment, real-time systems, etc.
While I beed in Kansas, I picked up watching a few new TV series. Monk beed mildly amusing, although it beed more of a time-filler than something I would rather watch than do other things. Psych, on the other hand, I might continu to watch, even though I be back home.
House be just godly. It be probably one of my favorite shows (along with Law and Order). It be about a doctor (House) and his medical students who get some of the more confusing cases, either due to extremely obscure illnesses, or symptoms that don't seem consistent with the illness, due to some unique circumstance. To quot one person on Star Alliance, House be Sherlock Holmes, only with medicine instead of crime. Oh, and doed I mention that House be a complete (and highly amusing) ass-hole? Arrogant, rude, anti-social, immature, rebellious, unprofessional, mean, etc. Since I discovered House, I hav learnen that a good number of my friends also watch it. And now you be going to watch it, too! You can probably find it for download somewhere. Or you could just watch it on Fox (tonight, I believ).
Other than that, I hav been slowly watching Stellvia of the Universe, as per SW's suggestion, and playing Neverwinter Nights and Hordes of the Underdark. Speaking of which, it hav been a good five or six months since I last played WoW. I wonder if I canill mak it all the way to the expansion (which beill November, at the earliest) without playing it again. Also, NWN2 beill coming out in October, and I be planning to get it, along with a new computer, using the money from this summer's work.
I wonder if I workill on LibQ again any time soon. I hav not worked on it in several months, and now I be rather engrossed in my evil plans that I be researching. Oh, and as a last note, this post be only tangentially related to what I be researching English grammar for.
Which bring up the fact that I be back in school for the fall semester. Three courses that probably beill boring, and one (operating systems concepts) that possibly might be intereting, if I don't already know most of the stuff the course beill teaching. Stuff like scheduling, synchronization, I/O, memory managment, real-time systems, etc.
While I beed in Kansas, I picked up watching a few new TV series. Monk beed mildly amusing, although it beed more of a time-filler than something I would rather watch than do other things. Psych, on the other hand, I might continu to watch, even though I be back home.
House be just godly. It be probably one of my favorite shows (along with Law and Order). It be about a doctor (House) and his medical students who get some of the more confusing cases, either due to extremely obscure illnesses, or symptoms that don't seem consistent with the illness, due to some unique circumstance. To quot one person on Star Alliance, House be Sherlock Holmes, only with medicine instead of crime. Oh, and doed I mention that House be a complete (and highly amusing) ass-hole? Arrogant, rude, anti-social, immature, rebellious, unprofessional, mean, etc. Since I discovered House, I hav learnen that a good number of my friends also watch it. And now you be going to watch it, too! You can probably find it for download somewhere. Or you could just watch it on Fox (tonight, I believ).
Other than that, I hav been slowly watching Stellvia of the Universe, as per SW's suggestion, and playing Neverwinter Nights and Hordes of the Underdark. Speaking of which, it hav been a good five or six months since I last played WoW. I wonder if I canill mak it all the way to the expansion (which beill November, at the earliest) without playing it again. Also, NWN2 beill coming out in October, and I be planning to get it, along with a new computer, using the money from this summer's work.
I wonder if I workill on LibQ again any time soon. I hav not worked on it in several months, and now I be rather engrossed in my evil plans that I be researching. Oh, and as a last note, this post be only tangentially related to what I be researching English grammar for.
Saturday, August 19, 2006
English Verbs - The 1' Verbs
Yeah, I realize I still have some uncompleted series to finish (like the Japanese grammar series), but at the moment I'm feeling most inspired in something else, so bear with me.
From time to time the last couple months, I've been looking at English grammar (yes, as you might imagine, it was for some greater purpose; no, you can't know what it is). Today I've been going through the English verbs and classifying them according to how they are conjugated. English verbs are broadly divided into two groups: the regular verbs and the irregular verbs. However, I prefer a bit more specific classification than that, and have thus created my own classification system.
Regular verbs are verbs which follow a very specific conjugation pattern, illustrated below:
Infinitive: to _ (ex: to mark)
Non-past tense: _ (mark), _s (marks; third person singular)
Non-past participle/gerund: _ing (marking)
Past tense: _ed (marked)
Past participle: _ed (marked)
Notice that there are 4 distinct conjugations: the infinitive/non-past tense, non-past participle/gerund, non-past third person singular tense, and past tense/participle. But all 4 of these conjugations can be derived directly from the present tense (for regular verbs ending in a vowel, the final vowel is removed before appending suffixes). Most English verbs are of this class (at least by number of verbs; by frequency of use or number of commonly used verbs it's a totally different story).
I call this a 1' conjugation because it has a single root: either the present tense directly, or the present tense with the final vowel removed.
There's one more type of 1' verb, which, as process of elimination would dictate, is part of the irregular verb superclass. This is the Single Present/Past/Participle conjugation class. As the name implies, this class is distinct in that the present tense (non-third-person singular), past tense, and past participle conjugations are all identical. For example:
Infinitive: to _ (to cast)
Non-past tense: _ (cast), _s (casts; third-person singular)
Non-past participle/gerund: _ing (casting)
Past tense: _ (cast)
Past participle: _ (cast)
In this case, there are three distinct conjugations, all derived directly from a single conjugation - the present tense.
The full list of non-archaic verbs in this class: bet, bid, cast, cost, cut, hit, hurt, knit, let, put, read (this one only belongs in this class if you're talking about how it's written; it's pronunciation differs from the rest of this class), rid, set, shed, shred, shut, slit, spit, split, spread, and thrust (and writing this list has made me decide that I will not being doing any more all-inclusive lists). Note that a couple of those are verbs that are in the middle of a transition to regular verbs (for example, knit) - both the Single Present/Past/Participle conjugation and regular verb conjugation patterns are considered grammatically correct for them.
I probably haven't given you enough data to see this last point, yet, so I'll just say it. Save for a handful of highly irregular verbs (ones that do not fit any of the conjugation patterns I have discussed or will discuss in this series), there are only 5 possible distinct conjugations for a given verb, from which all other grammatical conjugations draw - the non-past tense, the non-past third-person singular tense, the non-past participle, the past tense, and the past participle. Save for the truly irregular verbs, all the other tenses and gender/number combinations are drawn from those 5 in highly regular ways (for example, all perfect tenses are formed by adding a helper verb to the past participle).
As well, in all but the highly irregular verbs, there are no more than 3 roots for any given verb (usually 1 or 2), which may be derived to form the additional distinct conjugations (for example, the third-person singular non-past conjugation is always formed by adding -s to the present tense; as well, the non-past participle is always formed by adding -ing to the non-past tense).
Oh, and for the trivia value, as far as I know, be/being/am/are/is/was/were/been is the most complicated and highly irregular word in the English language, having 8 distinct conjugations and 6 roots.
Monday, August 07, 2006
Pop IT Quiz!
So today I wrote an e-mail address parser/validator based on RFC 3696. These are three e-mail addresses I threw at it to see if it was working correctly:
$q{_}i$|-|y\\ "f4t"@corp.goat.net
dorky.cat@corp.goat.net.
slinky-kitty@.corp.goat.net
Which one(s) of these is/are incorrect, without looking at an e-mail format reference?
$q{_}i$|-|y\\ "f4t"@corp.goat.net
dorky.cat@corp.goat.net.
slinky-kitty@.corp.goat.net
Which one(s) of these is/are incorrect, without looking at an e-mail format reference?
Thursday, July 20, 2006
& Lessons from the Morning Meeting
Thou shalt not play with a screwdriver like a sword without verifying that the bit is locked, lest ye nail your boss on the other side of the room in the face with a 4", extra-long screwdriver bit.
Sunday, July 16, 2006
The Animation Control Incident
So, I'm going about my business at work, working on my project. What I'm working on, generally, is a configuration wizard for the product we make. It tries to detect as much information as possible, and then let's the user review/change the setting before configuring/activating the program. One of the neat features it has (which I may blog about more in depth) is a mechanism of asynchronous data prefetch. As some of the detection methods can take several seconds (or even as long as 15 seconds, if a computer it's trying to reach on the network is offline), this hides that time by allowing the user to use the wizard while info is gathered in the background, ideally preventing the user from ever knowing how much time was spent gathering information.
Anyway, I needed a "please wait" dialog for when the user flips to a page whose data isn't loaded yet (and also to use for times when it has to spend time validating the user's input). The company has a nice little AVI to use for such occasions, so I threw it on a dialog with an animation control (the standard Windows common control). However, testing this dialog revealed something odd - once you told it to play with Animate_Play/ACM_PLAY, it would show the first frame for several seconds, until it finally began to play the animation.
A ridiculous amount of fidgeting with the parameters (and the source to the company's Animation control wrapper class) later, I was still unable to find anything I was doing wrong to cause this (although I did manage to observe that it wasn't just the first time - any time the window was completely obscured, this lag occurred). I asked Skywing about it, and about another weird thing I'd seen in the animation control class the company has. He said he'd seen the delay before, too, and had looked into it a bit, but was unable to locate the cause (and he said I should try and figure it out). He said that it seemed to be completely hiding the first iteration of the AVI.
So I looked at the control. It was creating a decoding thread, which looked like this:
.text:5D0AEC6D ; DWORD __stdcall PlayThread(LPVOID)
.text:5D0AEC6D _PlayThread@4 proc near
.text:5D0AEC6D
.text:5D0AEC6D arg_4 = dword ptr 8
.text:5D0AEC6D
.text:5D0AEC6D mov edi, edi
.text:5D0AEC6F push ebp
.text:5D0AEC70 mov ebp, esp
.text:5D0AEC72 push esi
.text:5D0AEC73 mov esi, [ebp+arg_4]
.text:5D0AEC76 push 1
.text:5D0AEC78 push esi
.text:5D0AEC79 call _DoNotify@8 ; DoNotify(x,x)
.text:5D0AEC7E push esi
.text:5D0AEC7F call _HandleTick@4 ; HandleTick(x)
.text:5D0AEC84 test eax, eax
.text:5D0AEC86 jz short loc_5D0AECB7
.text:5D0AEC88 push edi
.text:5D0AEC89 mov edi, 0FA0h
.text:5D0AEC8E mov ecx, [esi+5Ch]
.text:5D0AEC91 test ecx, ecx
.text:5D0AEC93 jz loc_5D0B8C48
.text:5D0AEC99 test eax, eax
.text:5D0AEC9B mov eax, [esi+44h]
.text:5D0AEC9E jl loc_5D0AF8BA
.text:5D0AECA4 push eax ; dwMilliseconds
.text:5D0AECA5 push ecx ; hHandle
.text:5D0AECA6 call ds:__imp__WaitForSingleObject@8 ; __declspec(dllimport) WaitForSingleObject(x,x)
.text:5D0AECAC push esi
.text:5D0AECAD call _HandleTick@4 ; HandleTick(x)
.text:5D0AECB2 test eax, eax
.text:5D0AECB4 jnz short loc_5D0AEC8E
.text:5D0AECB6 pop edi
.text:5D0AECB7 push 2
.text:5D0AECB9 push esi
.text:5D0AECBA call _DoNotify@8 ; DoNotify(x,x)
.text:5D0AECBF xor eax, eax
.text:5D0AECC1 pop esi
.text:5D0AECC2 pop ebp
.text:5D0AECC3 retn 4
.text:5D0AECC3 _PlayThread@4 endp
.text:5D0AF8BA add eax, edi
.text:5D0AF8BC jmp loc_5D0AECA4
HandleTick is what draws each frame (we'll get back to this in a minute). It was trivial to determine that the problem was due to WaitForSingleObject spending several seconds waiting before timing out. But that didn't explain why, or what it was waiting on.
By stepping through the loop I observed that the 5D0AEC9E-5D0AF8BA-5D0AF8BC-5D0AECA4 route was being taken. The value loaded from the struct was 100 ms, and it was getting 4000 ms added to it. I got out my cell phone (with built-in stopwatch) and verified that the drawing delay was exactly 4.1 seconds - not the 2.8 seconds Skywing predicted (the length of the animation). However, as best I could tell, it was doing this every single iteration. So why was there only a single gap in the animation?
As you can see in the disassembly, the 4 s delay path is only taken when HandleTick returns a negative number (which it was, in this case, returning -1). Looking at this function revealed the following of interest (I'm not pasting the whole function, here):
.text:5D0AECE7 push eax ; lpCriticalSection
.text:5D0AECE8 mov [ebp+lpCriticalSection], eax
.text:5D0AECEB call ds:__imp__EnterCriticalSection@4 ; __declspec(dllimport) EnterCriticalSection(x)
.text:5D0AECF1 push dword ptr [esi] ; hWnd
.text:5D0AECF3 call ds:__imp__GetDC@4 ; __declspec(dllimport) GetDC(x)
.text:5D0AECF9 mov ebx, eax
.text:5D0AECFB lea eax, [ebp+var_10]
.text:5D0AECFE push eax ; LPRECT
.text:5D0AECFF push ebx ; HDC
.text:5D0AED00 call ds:__imp__GetClipBox@8 ; __declspec(dllimport) GetClipBox(x,x)
.text:5D0AED06 cmp eax, 1
.text:5D0AED09 jz loc_5D0AF8A5
.text:5D0AED43 push ebx ; hDC
.text:5D0AED44 push dword ptr [esi] ; hWnd
.text:5D0AED46 mov edi, eax
.text:5D0AED48 call ds:__imp__ReleaseDC@8 ; __declspec(dllimport) ReleaseDC(x,x)
.text:5D0AED4E push [ebp+lpCriticalSection] ; lpCriticalSection
.text:5D0AED51 call ds:__imp__LeaveCriticalSection@4 ; __declspec(dllimport) LeaveCriticalSection(x)
.text:5D0AED57 pop ebx
.text:5D0AF8A5 mov eax, [esi+50h]
.text:5D0AF8A8 mov [esi+48h], eax
.text:5D0AF8AB xor eax, eax
.text:5D0AF8AD cmp [esi+4Ch], edi
.text:5D0AF8B0 setnz al
.text:5D0AF8B3 neg eax
.text:5D0AF8B5 jmp loc_5D0AED43
The jump at 5D0AED09 was being taken, resulting in eax getting set to -1 ([esi+4Ch]/-1 != edi/0). That one REALLY threw me. At first I thought that GetClipBox was succeeding, and as a result HandleTick was failing. But in fact GetClipBox has the following return values:
#define ERROR 0
#define NULLREGION 1
#define SIMPLEREGION 2
#define COMPLEXREGION 3
And everything becomes clear. If the animation's window is completely covered by another window, GetClipBox returns NULLREGION. If GetClipBox returns NULLREGION, HandleTick returns -1. If HandleTick returns -1, the timeout duration gets 4 s added to it.
Actually, there are two more pieces of information we still require to completely crack this case. The first was provided by Skywing and WinDbg - the event being waited on is actually a termination signal. When it's time for the animation control to stop playing, this event is set (among other things), short-circuiting the loop. This means that the value of [esi+44h] at 5D0AEC9B determines the rate at which frames are drawn. This is a bit of deviation from the most common use of events, where the event being set - not the timeout expiring - is the expected result.
It seems likely that the 4s addition is a backoff case. If the animation control window becomes completely obscured, there's no need to draw the frame, and the rendering thread stalls itself (excessively, if you ask me; I probably wouldn't have given more than a 1 second timeout).
So, now we know why the delay. That just leaves the question of why this timeout executes every time at the very beginning. After thinking about it a moment, the answer came to me: it's a consequence of how (or where) we're playing the animation - in the WM_CREATE (for windows) or WM_INITDIALOG (for dialogs) message handler. This is exactly where initialization that requires the window to already be created is supposed to go. Now, here's the trick: at this point, the window has been created - but it is still not visible (obviously - you want to do initialization BEFORE the window appears on screen). Since the rendering is done in a separate thread, this thread can execute concurrently with the UI thread. If the rendering thread gets to execute before the WM_CREATE/WM_INITDIALOG handler returns, and the window is shown, the rendering thread will go into timeout.
Anyway, I needed a "please wait" dialog for when the user flips to a page whose data isn't loaded yet (and also to use for times when it has to spend time validating the user's input). The company has a nice little AVI to use for such occasions, so I threw it on a dialog with an animation control (the standard Windows common control). However, testing this dialog revealed something odd - once you told it to play with Animate_Play/ACM_PLAY, it would show the first frame for several seconds, until it finally began to play the animation.
A ridiculous amount of fidgeting with the parameters (and the source to the company's Animation control wrapper class) later, I was still unable to find anything I was doing wrong to cause this (although I did manage to observe that it wasn't just the first time - any time the window was completely obscured, this lag occurred). I asked Skywing about it, and about another weird thing I'd seen in the animation control class the company has. He said he'd seen the delay before, too, and had looked into it a bit, but was unable to locate the cause (and he said I should try and figure it out). He said that it seemed to be completely hiding the first iteration of the AVI.
So I looked at the control. It was creating a decoding thread, which looked like this:
.text:5D0AEC6D ; DWORD __stdcall PlayThread(LPVOID)
.text:5D0AEC6D _PlayThread@4 proc near
.text:5D0AEC6D
.text:5D0AEC6D arg_4 = dword ptr 8
.text:5D0AEC6D
.text:5D0AEC6D mov edi, edi
.text:5D0AEC6F push ebp
.text:5D0AEC70 mov ebp, esp
.text:5D0AEC72 push esi
.text:5D0AEC73 mov esi, [ebp+arg_4]
.text:5D0AEC76 push 1
.text:5D0AEC78 push esi
.text:5D0AEC79 call _DoNotify@8 ; DoNotify(x,x)
.text:5D0AEC7E push esi
.text:5D0AEC7F call _HandleTick@4 ; HandleTick(x)
.text:5D0AEC84 test eax, eax
.text:5D0AEC86 jz short loc_5D0AECB7
.text:5D0AEC88 push edi
.text:5D0AEC89 mov edi, 0FA0h
.text:5D0AEC8E mov ecx, [esi+5Ch]
.text:5D0AEC91 test ecx, ecx
.text:5D0AEC93 jz loc_5D0B8C48
.text:5D0AEC99 test eax, eax
.text:5D0AEC9B mov eax, [esi+44h]
.text:5D0AEC9E jl loc_5D0AF8BA
.text:5D0AECA4 push eax ; dwMilliseconds
.text:5D0AECA5 push ecx ; hHandle
.text:5D0AECA6 call ds:__imp__WaitForSingleObject@8 ; __declspec(dllimport) WaitForSingleObject(x,x)
.text:5D0AECAC push esi
.text:5D0AECAD call _HandleTick@4 ; HandleTick(x)
.text:5D0AECB2 test eax, eax
.text:5D0AECB4 jnz short loc_5D0AEC8E
.text:5D0AECB6 pop edi
.text:5D0AECB7 push 2
.text:5D0AECB9 push esi
.text:5D0AECBA call _DoNotify@8 ; DoNotify(x,x)
.text:5D0AECBF xor eax, eax
.text:5D0AECC1 pop esi
.text:5D0AECC2 pop ebp
.text:5D0AECC3 retn 4
.text:5D0AECC3 _PlayThread@4 endp
.text:5D0AF8BA add eax, edi
.text:5D0AF8BC jmp loc_5D0AECA4
HandleTick is what draws each frame (we'll get back to this in a minute). It was trivial to determine that the problem was due to WaitForSingleObject spending several seconds waiting before timing out. But that didn't explain why, or what it was waiting on.
By stepping through the loop I observed that the 5D0AEC9E-5D0AF8BA-5D0AF8BC-5D0AECA4 route was being taken. The value loaded from the struct was 100 ms, and it was getting 4000 ms added to it. I got out my cell phone (with built-in stopwatch) and verified that the drawing delay was exactly 4.1 seconds - not the 2.8 seconds Skywing predicted (the length of the animation). However, as best I could tell, it was doing this every single iteration. So why was there only a single gap in the animation?
As you can see in the disassembly, the 4 s delay path is only taken when HandleTick returns a negative number (which it was, in this case, returning -1). Looking at this function revealed the following of interest (I'm not pasting the whole function, here):
.text:5D0AECE7 push eax ; lpCriticalSection
.text:5D0AECE8 mov [ebp+lpCriticalSection], eax
.text:5D0AECEB call ds:__imp__EnterCriticalSection@4 ; __declspec(dllimport) EnterCriticalSection(x)
.text:5D0AECF1 push dword ptr [esi] ; hWnd
.text:5D0AECF3 call ds:__imp__GetDC@4 ; __declspec(dllimport) GetDC(x)
.text:5D0AECF9 mov ebx, eax
.text:5D0AECFB lea eax, [ebp+var_10]
.text:5D0AECFE push eax ; LPRECT
.text:5D0AECFF push ebx ; HDC
.text:5D0AED00 call ds:__imp__GetClipBox@8 ; __declspec(dllimport) GetClipBox(x,x)
.text:5D0AED06 cmp eax, 1
.text:5D0AED09 jz loc_5D0AF8A5
.text:5D0AED43 push ebx ; hDC
.text:5D0AED44 push dword ptr [esi] ; hWnd
.text:5D0AED46 mov edi, eax
.text:5D0AED48 call ds:__imp__ReleaseDC@8 ; __declspec(dllimport) ReleaseDC(x,x)
.text:5D0AED4E push [ebp+lpCriticalSection] ; lpCriticalSection
.text:5D0AED51 call ds:__imp__LeaveCriticalSection@4 ; __declspec(dllimport) LeaveCriticalSection(x)
.text:5D0AED57 pop ebx
.text:5D0AF8A5 mov eax, [esi+50h]
.text:5D0AF8A8 mov [esi+48h], eax
.text:5D0AF8AB xor eax, eax
.text:5D0AF8AD cmp [esi+4Ch], edi
.text:5D0AF8B0 setnz al
.text:5D0AF8B3 neg eax
.text:5D0AF8B5 jmp loc_5D0AED43
The jump at 5D0AED09 was being taken, resulting in eax getting set to -1 ([esi+4Ch]/-1 != edi/0). That one REALLY threw me. At first I thought that GetClipBox was succeeding, and as a result HandleTick was failing. But in fact GetClipBox has the following return values:
#define ERROR 0
#define NULLREGION 1
#define SIMPLEREGION 2
#define COMPLEXREGION 3
And everything becomes clear. If the animation's window is completely covered by another window, GetClipBox returns NULLREGION. If GetClipBox returns NULLREGION, HandleTick returns -1. If HandleTick returns -1, the timeout duration gets 4 s added to it.
Actually, there are two more pieces of information we still require to completely crack this case. The first was provided by Skywing and WinDbg - the event being waited on is actually a termination signal. When it's time for the animation control to stop playing, this event is set (among other things), short-circuiting the loop. This means that the value of [esi+44h] at 5D0AEC9B determines the rate at which frames are drawn. This is a bit of deviation from the most common use of events, where the event being set - not the timeout expiring - is the expected result.
It seems likely that the 4s addition is a backoff case. If the animation control window becomes completely obscured, there's no need to draw the frame, and the rendering thread stalls itself (excessively, if you ask me; I probably wouldn't have given more than a 1 second timeout).
So, now we know why the delay. That just leaves the question of why this timeout executes every time at the very beginning. After thinking about it a moment, the answer came to me: it's a consequence of how (or where) we're playing the animation - in the WM_CREATE (for windows) or WM_INITDIALOG (for dialogs) message handler. This is exactly where initialization that requires the window to already be created is supposed to go. Now, here's the trick: at this point, the window has been created - but it is still not visible (obviously - you want to do initialization BEFORE the window appears on screen). Since the rendering is done in a separate thread, this thread can execute concurrently with the UI thread. If the rendering thread gets to execute before the WM_CREATE/WM_INITDIALOG handler returns, and the window is shown, the rendering thread will go into timeout.
Thursday, July 13, 2006
& Poor Electrical Layout
We have a quote database set up, here at work. We enter humorous quotes various people in the company have said at one point or another, and Bugzilla shows a random quote on every page. This one just hit the database, during the cubicle reorganization today:
"That explains why that's so fucking hot all the time!" - Wayne, referring to his power strip at the end of five power strips daisy-chained together, with a total load of 14 computers, 10 monitors, and various network routing equipment (in other words, the entire developer area) plugged into a single 20-amp wall socket
Monday, July 10, 2006
Another One for the Blacklist
So, I was running IE to use the web-page-based version of our product (our product is actually pretty useful, although some of the horribly buggy internal testing tools we have to use give me nightmares, and because of such problems I can no longer run the standalone version of the program). Anyway, when I finished using IE and closed it, WinDbg popped up and notified me that IE just blew up.
However, the way in which it blew up was rather unusual: it ran out of stack space, before which it threw about 1200 exceptions. In fact, it seemed apparent that it was throwing exceptions from the exception handler, as the stack revealed an equal number of KiUserExceptionDispatcher stack frames, one on top of the next.
Consulting with Skywing revealed that this was the case, as the exception it was throwing repeatedly was STATUS_NONCONTINUABLE_EXCEPTION, indicating that the exception handler was trying to continue execution following a noncontinuable exception, resulting in another exception, which tries to continue execution, and so on, until the thread runs out of stack and goes boom.
However, looking waaaaaay back in the log, we can see that the original exception thrown is some unusual (not built-in) exception 0x0eedfade. As well, it appears that the original exception was thrown by RaiseException, which was called from comcasttoolbar.dll, meaning it was probably intentionally thrown, as a C++-style exception.
So, what exactly went wrong? Well, let's start by looking at the immediate cause: the exception handler that caught the exception.
00f4179d xor eax,eax
00f4179f push ebp
00f417a0 push 0xf418b8
00f417a5 push dword ptr fs:[eax]
00f417a8 mov fs:[eax],esp
That's the one, right there - 0xf418b8. However, looking in this function, it always returns ExceptionContinueSearch before the program goes boom (and in fact it stops getting called well before that); that's pretty much a positive indication that this isn't the exception handler we're looking for.
Okay, well, that wasn't quite what I was expecting (was expecting the immediate cause to be as idiotic and immediately obvious as the ultimate cause). Anyway, moving on up [the exception handler chain]... Breakpointing on the call to the handler in NTDLL reveals that the next handler is 0xf24515, which is... also not what we're looking for. Okay... fast forward a bit (9 exception handlers, to be precise)... and we come to 0xf24c64, which returns ExceptionContinueExecution; that's the one we're looking for. Let's have a look...
00f24c64 mov eax,[esp+0x4]
00f24c68 test dword ptr [eax+0x4],0x6
00f24c6f jne COMCAS_1+0x4cfe (00f24cfe)
00f24c75 cmp byte ptr [COMCAS_1!DllUnregisterServer+0xc76c8 (0108c028)],0x0
00f24c7c ja COMCAS_1+0x4c8d (00f24c8d)
00f24c7e lea eax,[esp+0x4]
00f24c82 push eax
00f24c83 call UnhandledExceptionFilter (00f21340)
00f24c88 cmp eax,0x0
00f24c8b jz COMCAS_1+0x4cfe (00f24cfe)
...do a bunch of stuff that checks for exception code 0x0eedfade, and results in the program being terminated with an error message...
00f24cfe xor eax,eax
00f24d00 ret
The branch at 00f24c8b gets taken, resulting in eax (the return value) getting set to 0 (ExceptionContinueExecution), causing Windows to attempt to continue execution. If I intercept that branch and cause it to not be taken, a message box that says "Runtime error 217 at 00F4182E" appears, and clicking on OK results in IE terminating relatively normally.
What this code is doing is checking what the default exception handler behavior is. UnhandledExceptionFilter returns EXCEPTION_EXECUTE_HANDLER if Windows has displayed an exception dialog. This is the default behavior most of the time; but when there is a just-in-time debugger installed (like on my computer), UnhandledExceptionFilter starts up the debugger and returns EXCEPTION_CONTINUE_SEARCH. In response to this, the exception handler is supposed to return ExceptionContinueSearch, so that the exception will be rethrown and caught by the debugger. But this function isn't returning ExceptionContinueSearch - it's returning ExceptionContinueExecution. Why? Well, let's take a look at what _except_handler returns:
typedef enum _EXCEPTION_DISPOSITION {
ExceptionContinueExecution = 0,
ExceptionContinueSearch = 1,
ExceptionNestedException = 2,
ExceptionCollidedUnwind = 3
} EXCEPTION_DISPOSITION;
And here's what UnhandledExceptionFilter returns:
#define EXCEPTION_EXECUTE_HANDLER 1
#define EXCEPTION_CONTINUE_SEARCH 0
#define EXCEPTION_CONTINUE_EXECUTION -1
It sure looks like the coder of this exception handler got the two mixed up, and returned ExceptionContinueExecution when they thought they were returning EXCEPTION_CONTINUE_SEARCH. However, that'd be a bit weird, as you normally do not code _except_handler functions at all - the compiler builds them for you you, based on the Windows __try/__except/__finally syntax or C++ try/catch syntax.
Doing some looking at the DLL in a hex editor suggests that it was written in Delphi (either that or Borland C++ Builder). Looking at other exception handlers, I'm really unsure whether or not this exception handler is kosher. There are three other exception handlers that call UnhandledException filter. They all start out with the following basic logic:
.text:00404A3C mov eax, [esp+4]
.text:00404A40 test dword ptr [eax+4], 6
.text:00404A47 jnz loc_404AF8
.text:00404A4D cmp dword ptr [eax], 0EEDFADEh
.text:00404A53 cld
.text:00404A54 call @System@_16542 ; System::_16542
.text:00404A59 jz short loc_404A82
...one of the handlers has some extra logic here...
.text:00404A5B cmp byte_56C02C, 0
.text:00404A62 jbe short loc_404A82
.text:00404A64 cmp byte_56C028, 0
.text:00404A6B ja short loc_404A82
.text:00404A6D lea eax, [esp+4]
.text:00404A71 push eax
.text:00404A72 call UnhandledExceptionFilter
.text:00404A77 cmp eax, 0
.text:00404A7A jz short loc_404AF8
.text:00404A7C mov eax, [esp+4]
.text:00404A80 jmp short loc_404A94
...handle Delphi exceptions here...
.text:00404AF8 mov eax, 1
.text:00404AFD retn
Notice what it's doing. It first checks the exception flags. If neither flag is set, it returns ExceptionContinueSearch; otherwise, it prepares to execute the handler (that's what the CLD and call to System::_16542 are), tries to crack the exception (with special care taken to looking for the 0xEEDFADE code), and calls UnhandledExceptionFilter only if it doesn't think it's one of the Delphi exceptions. Not only that, but they all return ExceptionContinueSearch as the default return value. Now compare all of that behavior with our misbehaving handler encountered earlier.
So, in the end we end up not knowing much. Our misbehaving handler in some ways resembles the other handlers, but in other ways not. That's the evidence, but it's not enough to conclusively determine whether this was generated by the compiler or by a person. In either case, I'm fairly confident that it's wrong.
*ahem* Moving on... what do you suppose that exception was, and who threw it, anyway? Here's who (421829, to be precise):
.text:004217D1 mov ecx, eax
.text:004217D3 xor edx, edx
.text:004217D5 mov eax, ebx
.text:004217D7 call unknown_libname_85
.text:004217DC cmp dword ptr [ebx+4], 0
.text:004217E0 jge loc_421893
.text:004217E6 lea edx, [ebp+var_18]
.text:004217E9 mov eax, esi
.text:004217EB call @Sysutils@ExpandFileName$qqrx17System@AnsiString ; Sysutils::ExpandFileName(System::AnsiString)
.text:004217F0 mov eax, [ebp+var_18]
.text:004217F3 mov [ebp+var_14], eax
.text:004217F6 mov [ebp+var_10], 0Bh
.text:004217FA call GetLastError_0
.text:004217FF lea edx, [ebp+var_1C]
.text:00421802 call sub_40E28C
.text:00421807 mov eax, [ebp+var_1C]
.text:0042180A mov [ebp+var_C], eax
.text:0042180D mov [ebp+var_8], 0Bh
.text:00421811 lea eax, [ebp+var_14]
.text:00421814 push eax
.text:00421815 push 1
.text:00421817 mov ecx, off_56ED00
.text:0042181D mov dl, 1
.text:0042181F mov eax, ds:off_41B358
.text:00421824 call @Sysutils@Exception@$bctr$qqrp20System@TResStringRecpx14System@TVarRecxi ; Sysutils::Exception::Exception(System::TResStringRec *,System::TVarRec *,int)
.text:00421829 call sub_404B00
.text:0042182E jmp short loc_421893
The branch at 4217DC seems to be not taken. Looks like unknown_libname_85 (among other things) stores its ecx param in its [eax+4], the latter being what gets checked at the compare in this block. This value comes from just above the previous block:
.text:004217B2 push 0
.text:004217B4 push 80h
.text:004217B9 push 2
.text:004217BB push 0
.text:004217BD push 0
.text:004217BF push 0C0000000h
.text:004217C4 mov eax, esi
.text:004217C6 call @System@@LStrToPChar$qqrv ; System::__linkproc__ LStrToPChar(void)
.text:004217CB push eax
.text:004217CC call CreateFileA_0
So... we have an exception getting thrown when CreateFile fails, where CreateFile tries to open the file for both reading and writing. Are you pondering what I'm pondering? Let's take a peek at what file it's failing to open, and find out if I'm right. Step into ExpandFileName and... "C:\Program Files\COMCASTTOOLBAR\Cache\COMBOSEARCH.acs". The shock is enough to kill you - it's a directory that limited users can only read from, and I'm a limited user.
So, in the end it turns out that we are indeed dealing with an idiot (or maybe more than one). Yeah, I know I never got around to the series on writing limited user-friendly programs (it's still on the todo list), but here's the gist of it: don't write outside the box, and Program Files sure isn't in your box (although I suppose that's not quite as bad as one guy at work I nailed for writing some temporary files in the Windows directory).
That leaves just one more question to answer (at least, one more to answer that we actually can answer): have they fixed this, yet? This Comcast toolbar was installed on this laptop when I got it from work. I have no idea how recent it may be. So let's see about downloading the latest version of the Comcast toolbar, and checking if it plays nicely, this time.
My version of the toolbar is 4.0.2.201. The most recent version is... 4.0.2.201. But just to make sure, let's run IE one last time, after intalling the newest version. It looks like the toolbar failed to even start up, staying in some kind of "loading..." mode (though at least it didn't crash). I bet that's due to exactly the same problem, where it's trying to write to the Program Files folder the first time it's run after installation. Running it once as admin confirms this. And running it one more time as a limited user confirms that the obnoxious crash indeed remains in the latest version.
So, I give it a D+ for limited user compatibility.
However, the way in which it blew up was rather unusual: it ran out of stack space, before which it threw about 1200 exceptions. In fact, it seemed apparent that it was throwing exceptions from the exception handler, as the stack revealed an equal number of KiUserExceptionDispatcher stack frames, one on top of the next.
Consulting with Skywing revealed that this was the case, as the exception it was throwing repeatedly was STATUS_NONCONTINUABLE_EXCEPTION, indicating that the exception handler was trying to continue execution following a noncontinuable exception, resulting in another exception, which tries to continue execution, and so on, until the thread runs out of stack and goes boom.
However, looking waaaaaay back in the log, we can see that the original exception thrown is some unusual (not built-in) exception 0x0eedfade. As well, it appears that the original exception was thrown by RaiseException, which was called from comcasttoolbar.dll, meaning it was probably intentionally thrown, as a C++-style exception.
So, what exactly went wrong? Well, let's start by looking at the immediate cause: the exception handler that caught the exception.
00f4179d xor eax,eax
00f4179f push ebp
00f417a0 push 0xf418b8
00f417a5 push dword ptr fs:[eax]
00f417a8 mov fs:[eax],esp
That's the one, right there - 0xf418b8. However, looking in this function, it always returns ExceptionContinueSearch before the program goes boom (and in fact it stops getting called well before that); that's pretty much a positive indication that this isn't the exception handler we're looking for.
Okay, well, that wasn't quite what I was expecting (was expecting the immediate cause to be as idiotic and immediately obvious as the ultimate cause). Anyway, moving on up [the exception handler chain]... Breakpointing on the call to the handler in NTDLL reveals that the next handler is 0xf24515, which is... also not what we're looking for. Okay... fast forward a bit (9 exception handlers, to be precise)... and we come to 0xf24c64, which returns ExceptionContinueExecution; that's the one we're looking for. Let's have a look...
00f24c64 mov eax,[esp+0x4]
00f24c68 test dword ptr [eax+0x4],0x6
00f24c6f jne COMCAS_1+0x4cfe (00f24cfe)
00f24c75 cmp byte ptr [COMCAS_1!DllUnregisterServer+0xc76c8 (0108c028)],0x0
00f24c7c ja COMCAS_1+0x4c8d (00f24c8d)
00f24c7e lea eax,[esp+0x4]
00f24c82 push eax
00f24c83 call UnhandledExceptionFilter (00f21340)
00f24c88 cmp eax,0x0
00f24c8b jz COMCAS_1+0x4cfe (00f24cfe)
...do a bunch of stuff that checks for exception code 0x0eedfade, and results in the program being terminated with an error message...
00f24cfe xor eax,eax
00f24d00 ret
The branch at 00f24c8b gets taken, resulting in eax (the return value) getting set to 0 (ExceptionContinueExecution), causing Windows to attempt to continue execution. If I intercept that branch and cause it to not be taken, a message box that says "Runtime error 217 at 00F4182E" appears, and clicking on OK results in IE terminating relatively normally.
What this code is doing is checking what the default exception handler behavior is. UnhandledExceptionFilter returns EXCEPTION_EXECUTE_HANDLER if Windows has displayed an exception dialog. This is the default behavior most of the time; but when there is a just-in-time debugger installed (like on my computer), UnhandledExceptionFilter starts up the debugger and returns EXCEPTION_CONTINUE_SEARCH. In response to this, the exception handler is supposed to return ExceptionContinueSearch, so that the exception will be rethrown and caught by the debugger. But this function isn't returning ExceptionContinueSearch - it's returning ExceptionContinueExecution. Why? Well, let's take a look at what _except_handler returns:
typedef enum _EXCEPTION_DISPOSITION {
ExceptionContinueExecution = 0,
ExceptionContinueSearch = 1,
ExceptionNestedException = 2,
ExceptionCollidedUnwind = 3
} EXCEPTION_DISPOSITION;
And here's what UnhandledExceptionFilter returns:
#define EXCEPTION_EXECUTE_HANDLER 1
#define EXCEPTION_CONTINUE_SEARCH 0
#define EXCEPTION_CONTINUE_EXECUTION -1
It sure looks like the coder of this exception handler got the two mixed up, and returned ExceptionContinueExecution when they thought they were returning EXCEPTION_CONTINUE_SEARCH. However, that'd be a bit weird, as you normally do not code _except_handler functions at all - the compiler builds them for you you, based on the Windows __try/__except/__finally syntax or C++ try/catch syntax.
Doing some looking at the DLL in a hex editor suggests that it was written in Delphi (either that or Borland C++ Builder). Looking at other exception handlers, I'm really unsure whether or not this exception handler is kosher. There are three other exception handlers that call UnhandledException filter. They all start out with the following basic logic:
.text:00404A3C mov eax, [esp+4]
.text:00404A40 test dword ptr [eax+4], 6
.text:00404A47 jnz loc_404AF8
.text:00404A4D cmp dword ptr [eax], 0EEDFADEh
.text:00404A53 cld
.text:00404A54 call @System@_16542 ; System::_16542
.text:00404A59 jz short loc_404A82
...one of the handlers has some extra logic here...
.text:00404A5B cmp byte_56C02C, 0
.text:00404A62 jbe short loc_404A82
.text:00404A64 cmp byte_56C028, 0
.text:00404A6B ja short loc_404A82
.text:00404A6D lea eax, [esp+4]
.text:00404A71 push eax
.text:00404A72 call UnhandledExceptionFilter
.text:00404A77 cmp eax, 0
.text:00404A7A jz short loc_404AF8
.text:00404A7C mov eax, [esp+4]
.text:00404A80 jmp short loc_404A94
...handle Delphi exceptions here...
.text:00404AF8 mov eax, 1
.text:00404AFD retn
Notice what it's doing. It first checks the exception flags. If neither flag is set, it returns ExceptionContinueSearch; otherwise, it prepares to execute the handler (that's what the CLD and call to System::_16542 are), tries to crack the exception (with special care taken to looking for the 0xEEDFADE code), and calls UnhandledExceptionFilter only if it doesn't think it's one of the Delphi exceptions. Not only that, but they all return ExceptionContinueSearch as the default return value. Now compare all of that behavior with our misbehaving handler encountered earlier.
So, in the end we end up not knowing much. Our misbehaving handler in some ways resembles the other handlers, but in other ways not. That's the evidence, but it's not enough to conclusively determine whether this was generated by the compiler or by a person. In either case, I'm fairly confident that it's wrong.
*ahem* Moving on... what do you suppose that exception was, and who threw it, anyway? Here's who (421829, to be precise):
.text:004217D1 mov ecx, eax
.text:004217D3 xor edx, edx
.text:004217D5 mov eax, ebx
.text:004217D7 call unknown_libname_85
.text:004217DC cmp dword ptr [ebx+4], 0
.text:004217E0 jge loc_421893
.text:004217E6 lea edx, [ebp+var_18]
.text:004217E9 mov eax, esi
.text:004217EB call @Sysutils@ExpandFileName$qqrx17System@AnsiString ; Sysutils::ExpandFileName(System::AnsiString)
.text:004217F0 mov eax, [ebp+var_18]
.text:004217F3 mov [ebp+var_14], eax
.text:004217F6 mov [ebp+var_10], 0Bh
.text:004217FA call GetLastError_0
.text:004217FF lea edx, [ebp+var_1C]
.text:00421802 call sub_40E28C
.text:00421807 mov eax, [ebp+var_1C]
.text:0042180A mov [ebp+var_C], eax
.text:0042180D mov [ebp+var_8], 0Bh
.text:00421811 lea eax, [ebp+var_14]
.text:00421814 push eax
.text:00421815 push 1
.text:00421817 mov ecx, off_56ED00
.text:0042181D mov dl, 1
.text:0042181F mov eax, ds:off_41B358
.text:00421824 call @Sysutils@Exception@$bctr$qqrp20System@TResStringRecpx14System@TVarRecxi ; Sysutils::Exception::Exception(System::TResStringRec *,System::TVarRec *,int)
.text:00421829 call sub_404B00
.text:0042182E jmp short loc_421893
The branch at 4217DC seems to be not taken. Looks like unknown_libname_85 (among other things) stores its ecx param in its [eax+4], the latter being what gets checked at the compare in this block. This value comes from just above the previous block:
.text:004217B2 push 0
.text:004217B4 push 80h
.text:004217B9 push 2
.text:004217BB push 0
.text:004217BD push 0
.text:004217BF push 0C0000000h
.text:004217C4 mov eax, esi
.text:004217C6 call @System@@LStrToPChar$qqrv ; System::__linkproc__ LStrToPChar(void)
.text:004217CB push eax
.text:004217CC call CreateFileA_0
So... we have an exception getting thrown when CreateFile fails, where CreateFile tries to open the file for both reading and writing. Are you pondering what I'm pondering? Let's take a peek at what file it's failing to open, and find out if I'm right. Step into ExpandFileName and... "C:\Program Files\COMCASTTOOLBAR\Cache\COMBOSEARCH.acs". The shock is enough to kill you - it's a directory that limited users can only read from, and I'm a limited user.
So, in the end it turns out that we are indeed dealing with an idiot (or maybe more than one). Yeah, I know I never got around to the series on writing limited user-friendly programs (it's still on the todo list), but here's the gist of it: don't write outside the box, and Program Files sure isn't in your box (although I suppose that's not quite as bad as one guy at work I nailed for writing some temporary files in the Windows directory).
That leaves just one more question to answer (at least, one more to answer that we actually can answer): have they fixed this, yet? This Comcast toolbar was installed on this laptop when I got it from work. I have no idea how recent it may be. So let's see about downloading the latest version of the Comcast toolbar, and checking if it plays nicely, this time.
My version of the toolbar is 4.0.2.201. The most recent version is... 4.0.2.201. But just to make sure, let's run IE one last time, after intalling the newest version. It looks like the toolbar failed to even start up, staying in some kind of "loading..." mode (though at least it didn't crash). I bet that's due to exactly the same problem, where it's trying to write to the Program Files folder the first time it's run after installation. Running it once as admin confirms this. And running it one more time as a limited user confirms that the obnoxious crash indeed remains in the latest version.
So, I give it a D+ for limited user compatibility.
Sunday, July 09, 2006
Limited User Compatibility Grade
For a while now (a minute or two here or there) I've been thinking about how to make a limited user compatibility grade scale, based on how well programs run under a limited (non-admin) account. Here's what I'm thinking at the moment:
A - program works perfectly (after installation)
B - program has tolerable bugs (bugs that can be worked around or ignored) in minor features
C - program has blocking bugs (bugs that pretty much prevent use of a feature) in minor features, or tolerable bugs in major features
D - program runs to some extent, but has blocking bugs in some major features
F - program does not run at all
Comments/ideas?
A - program works perfectly (after installation)
B - program has tolerable bugs (bugs that can be worked around or ignored) in minor features
C - program has blocking bugs (bugs that pretty much prevent use of a feature) in minor features, or tolerable bugs in major features
D - program runs to some extent, but has blocking bugs in some major features
F - program does not run at all
Comments/ideas?
Saturday, July 08, 2006
& Backlog
Man, looking at some of the stuff I started on this block, I've got a buttload of stuff I need to post. At least four series I started but never finished, and it's been aeons since I posted anything on LibQ (heck, it's been a few months since I've even worked on LibQ). I also have a couple of recent stories from work and some of the stuff I've done on my days off. As well, I might still post a few more case analyses of languages that weren't initially in the list, such as Chinese (Cantonese, to be specific) and a couple of extra-special mystery languages.
Also, I just thought I'd list some of the other blogs I read but aren't on the links to the left (not that I read all of those; some are just because they belong to friends), to go with the blogs I mentioned in the last post.
- Neo-neocon - an intellectual blog that often covers politics, and was known for having interesting (and lengthy) debates between those two agree and those that don't agree with the neocon perspective. It's been pretty boring since they banned all the "trolls" a week or so back, but a couple opponents have shown up the last day or two, and at least one thread has broken out into debate.
- Musings of a Palestinian Princess - life in the hot zone (the West Bank). Can be interesting when debates between Israelis and Palestinians (and their supporters) get into debates.
- Baghdad Burning - life in the other hot zone. A bit on the cynical side. Unfortunately, no commenting allowed, although if you read a bit, you can probably guess why.
- Narges - life in the "axis of evil" (Iran; noticing a theme, here?). This one's not like the others in that she is a programmer who is going for her masters' degree, and doing research on machine translation.
- Informed Comment - the blow by blow(-up) in Iraq. Middle-eastern news from a rather depressing, yet informative perspective.
As this is kind of a grab bag post, you shouldn't be surprised to see other things pop up on it, as I remember other things.
Also, I just thought I'd list some of the other blogs I read but aren't on the links to the left (not that I read all of those; some are just because they belong to friends), to go with the blogs I mentioned in the last post.
- Neo-neocon - an intellectual blog that often covers politics, and was known for having interesting (and lengthy) debates between those two agree and those that don't agree with the neocon perspective. It's been pretty boring since they banned all the "trolls" a week or so back, but a couple opponents have shown up the last day or two, and at least one thread has broken out into debate.
- Musings of a Palestinian Princess - life in the hot zone (the West Bank). Can be interesting when debates between Israelis and Palestinians (and their supporters) get into debates.
- Baghdad Burning - life in the other hot zone. A bit on the cynical side. Unfortunately, no commenting allowed, although if you read a bit, you can probably guess why.
- Narges - life in the "axis of evil" (Iran; noticing a theme, here?). This one's not like the others in that she is a programmer who is going for her masters' degree, and doing research on machine translation.
- Informed Comment - the blow by blow(-up) in Iraq. Middle-eastern news from a rather depressing, yet informative perspective.
As this is kind of a grab bag post, you shouldn't be surprised to see other things pop up on it, as I remember other things.
And Then There Were... Shoot, I've Lost Count
Skywing just created a blog, after much prodding by me and my boss. Unfortunately, he didn't join me on this blog, like I suggested (him and one other person I was looking to acquire). Also, my boss has had a blog for quite a while, although for some reason the contents don't interest me as much as some other blogs (or maybe I just like to write more than I like to read). Also, Ryan Govostes, one of the people I know on MSN, and who reads my blog, has had a blog for a while. I haven't looked at that one too much, but this most recent post (from a month ago) looks interesting. Too bad the blog sucks. And by that I mean he was too lazy to make any kind of a listing of recent posts or archive of old posts, and leaves you with "previous" and "next" on each post to navigate the posts.
While we're kinda-sorta on the topic of my job, here's a fact for you: 14% of all of the MS driver development MVPs in the world work at the company, and 50% of the people in the world who have gotten the award more than once.
While we're kinda-sorta on the topic of my job, here's a fact for you: 14% of all of the MS driver development MVPs in the world work at the company, and 50% of the people in the world who have gotten the award more than once.
Windows Structured Exception Handling
This post is a bit of a backgrounder for another post I've already written most of (but haven't posted yet). That post deals almost entirely with Windows Structured Exception Handling (SEH). As at least half of the people I know who read my blog are from inferior operating systems like Unix (half kidding) I thought I should start out by describing SEH.
C++ provides fairly robust error handling mechanisms. For example, you could do the following:
This would allow you to catch the out of memory exception and handle the condition. Of course, in C++ you could just as easily do:
Windows provides a dramatically superior method of handling hardware exceptions, and that is SEH. SEH is very similar to the C++ exception model: when a faulting instruction is executed, an exception is thrown, and the program searches for a suitable exception handler. If such a handler can't be found in the function that threw the exception, the calling function is checked; if not the calling function, the caller's calling function; and so on. Eventually either a suitable exception handler is found or the default handler is used; in either case, the stack is "unwound", destructing classes for each function, and executing cleanup code in each function in which a handler wasn't found, and the exception handler is ultimately executed, with the machine in a state as if the function containing the handler had jumped directly into the handler.
The syntax of SEH exceptions (shown above) is almost identical to that of C++ exceptions, and, as a matter of fact, Windows C++ compilers use Windows SEH to implement C++ exceptions. One of the definitive guides on how SEH works is by (*shock and awe*) Matt Pietrek; but I'll give a brief summary of the process.
Each thread maintains a stack of exception handler records called EXCEPTION_REGISTRATIONs. This is a singly linked list of EXCEPTION_REGISTRATION structures constructed on the stack, where the head pointer is contained in an important thread-local storage structure called the Thread Environment Block (TEB). One of these exception handler records is created by the __try statement, and destroyed after the __except block. Each of the links contains a pointer to an _except_handler function - the exception handler for that block.
When an exception occurs, it is caught by the Windows kernel exception trap. Windows checks for certain types of exceptions, such as accessing a page of memory that is allocated, but currently paged to disk, and may handle the exception right then (in that example, Windows would respond by reading the page off disk, then retrying the instruction that caused the exception).
If it's not one of the special case exceptions, Windows transitions to user mode, and starts walking the list of exception handlers for the thread, calling each one with detailed information about the exception, looking for one that will handle the particular exception. The return value of the _except_handler tells Windows what to do next. ExceptionContinueSearch tells Windows that the exception handler does not want to handle the exception, and that Window should keep looking for a handler. ExceptionContinueExecution tells Windows to resume execution of the thread; this may or may not be at the same place that caused the exception, as the exception handler can alter the registers and memory of the thread.
A third option is that the exception handler calls the Windows RtlUnwind function. This function unwinds the stack to get to the desired stack frame - the stack frame of the function with the __except block that is going to get executed. Once this process is completed, the exception handler can JMP to the code in the desired __except block. Unwinding works by walking the exception handler stack from the top, calling each handler with the STATUS_UNWIND "exception code". This instructs the exception handler to destruct any stack variables that require destruction, or cleanup code that should be executed (think how C++ exceptions can be rethrown after doing some cleanup work). This allows Windows to ensure that the stack is cleaned up, without ever knowing anything about what's on the stack or how to clean it up. This also implies that "exception handler" functions aren't just to catch exceptions - there must also be such a function for every function that has destructible variables and in which an exception can be thrown (there is a VC++ project setting which tells the compiler to assume every function can throw SEH exceptions, or to assume only C++ exceptions can be thrown by some functions).
If no exception handler in the program handles the exception, the outermost exception handler will. This handler is located in the thread/process start stub in Kernel32.dll, where Windows wraps the call to your thread/process start function in a __try block. The __except block simply calls UnhandledExceptionFilter, which, by default, displays the "this program has performed an illegal operation" dialog you've no doubt seen before, and terminates the program.
Lastly, SEH exceptions are not strictly compatible with C++ exceptions. You cannot catch SEH exceptions with a C++ catch block (and in fact you can use SEH exception handling in a vanilla C app), although you can catch C++ exceptions with an __except block using certain compiler settings. I don't know about other compilers, but VC++ allows you to set a function the compiler's generated exception handlers will call to convert SEH exceptions to true C++ exceptions, however, which may be caught with C++ catch blocks. I haven't actually used this before, but that sounds pretty sweet.
C++ provides fairly robust error handling mechanisms. For example, you could do the following:
try
{
int *pInt = new int[some_number];
}
catch (bad_alloc)
{
cout << "Out of memory" << endl;
}
This would allow you to catch the out of memory exception and handle the condition. Of course, in C++ you could just as easily do:
int *pInt = (int *)malloc(some_number * sizeof(int));In this case, you have options - you can either use the old C functions that indicate errors with special return values, or use the new C++ exception handling. However, there exists another class of exceptions - hardware exceptions. These include things like divide by zero, access violations, attempts to execute invalid instructions, etc. But neither C nor C++ provide facilities for handling these. POSIX provides a primitive method for handling these exceptions - when such an exception occurs, the OS transfers the thread in which the exception occurred to an exception handler function. This handler function can then display an error message and terminate the thread/program or attempt to recover using the tricky setjump/longjump.
if (pInt == NULL) printf("Out of memory\r\n");
Windows provides a dramatically superior method of handling hardware exceptions, and that is SEH. SEH is very similar to the C++ exception model: when a faulting instruction is executed, an exception is thrown, and the program searches for a suitable exception handler. If such a handler can't be found in the function that threw the exception, the calling function is checked; if not the calling function, the caller's calling function; and so on. Eventually either a suitable exception handler is found or the default handler is used; in either case, the stack is "unwound", destructing classes for each function, and executing cleanup code in each function in which a handler wasn't found, and the exception handler is ultimately executed, with the machine in a state as if the function containing the handler had jumped directly into the handler.
__try {
int *pInt = NULL;
*pInt = 0; // Boom
}
__except (EXCEPTION_EXECUTE_HANDLER)
{
printf("Access violation");
}The syntax of SEH exceptions (shown above) is almost identical to that of C++ exceptions, and, as a matter of fact, Windows C++ compilers use Windows SEH to implement C++ exceptions. One of the definitive guides on how SEH works is by (*shock and awe*) Matt Pietrek; but I'll give a brief summary of the process.
Each thread maintains a stack of exception handler records called EXCEPTION_REGISTRATIONs. This is a singly linked list of EXCEPTION_REGISTRATION structures constructed on the stack, where the head pointer is contained in an important thread-local storage structure called the Thread Environment Block (TEB). One of these exception handler records is created by the __try statement, and destroyed after the __except block. Each of the links contains a pointer to an _except_handler function - the exception handler for that block.
When an exception occurs, it is caught by the Windows kernel exception trap. Windows checks for certain types of exceptions, such as accessing a page of memory that is allocated, but currently paged to disk, and may handle the exception right then (in that example, Windows would respond by reading the page off disk, then retrying the instruction that caused the exception).
If it's not one of the special case exceptions, Windows transitions to user mode, and starts walking the list of exception handlers for the thread, calling each one with detailed information about the exception, looking for one that will handle the particular exception. The return value of the _except_handler tells Windows what to do next. ExceptionContinueSearch tells Windows that the exception handler does not want to handle the exception, and that Window should keep looking for a handler. ExceptionContinueExecution tells Windows to resume execution of the thread; this may or may not be at the same place that caused the exception, as the exception handler can alter the registers and memory of the thread.
A third option is that the exception handler calls the Windows RtlUnwind function. This function unwinds the stack to get to the desired stack frame - the stack frame of the function with the __except block that is going to get executed. Once this process is completed, the exception handler can JMP to the code in the desired __except block. Unwinding works by walking the exception handler stack from the top, calling each handler with the STATUS_UNWIND "exception code". This instructs the exception handler to destruct any stack variables that require destruction, or cleanup code that should be executed (think how C++ exceptions can be rethrown after doing some cleanup work). This allows Windows to ensure that the stack is cleaned up, without ever knowing anything about what's on the stack or how to clean it up. This also implies that "exception handler" functions aren't just to catch exceptions - there must also be such a function for every function that has destructible variables and in which an exception can be thrown (there is a VC++ project setting which tells the compiler to assume every function can throw SEH exceptions, or to assume only C++ exceptions can be thrown by some functions).
If no exception handler in the program handles the exception, the outermost exception handler will. This handler is located in the thread/process start stub in Kernel32.dll, where Windows wraps the call to your thread/process start function in a __try block. The __except block simply calls UnhandledExceptionFilter, which, by default, displays the "this program has performed an illegal operation" dialog you've no doubt seen before, and terminates the program.
Lastly, SEH exceptions are not strictly compatible with C++ exceptions. You cannot catch SEH exceptions with a C++ catch block (and in fact you can use SEH exception handling in a vanilla C app), although you can catch C++ exceptions with an __except block using certain compiler settings. I don't know about other compilers, but VC++ allows you to set a function the compiler's generated exception handlers will call to convert SEH exceptions to true C++ exceptions, however, which may be caught with C++ catch blocks. I haven't actually used this before, but that sounds pretty sweet.
Tuesday, July 04, 2006
Letters, Words, and Big Numbers, Oh My!
So, I was bored and... decided to play around with license keys some. Everybody hates license keys, right? Especially in cases like Neverwinter Nights, where they have 35 alphanumeric characters (!). We're currently in the process of making some changes to how the system works at work, and one of the results is that we'll now be using license keys for something. So, what can we do to make them more friendly?
Let's apply some basic psychology to the problem: the brain only has so many registers (bits of information that it can hold readily available without requiring effort to memorize the information; I think the exact number is like 5), with each one able to hold a symbol (remember that the brain's processing abilities are highly symbolic). For a random alphanumeric string, each character must be stored in a separate register (if you think that's dehumanizing, you should see the occasional debates me, DB, and BZ - all of us programmers, but all of us also interested in biology - have on the topic of reproduction and evolutionary psychology; and yes, I am aware that "me" isn't technically a subjective pronoun). For a string of, say, numbers where a pattern is evident, the brain can apply compression to the string, and store a larger number of numbers in its registers than it would be able to if there was no pattern.
So, my idea is simply this: use symbols larger than letters and numbers in the license key. This one dictionary I picked for this purpose has 16,100 English words of 7 characters or less (a somewhat arbitrary limitation I established), and that's not even including conjugations of most verbs.
Let's see how well this works. If we take the NWN key, the maximum number of theoretically possible keys is about 3*10^54 (36^35; quiz: how many bits is that?). I can remember about 5 characters at a time, meaning I will have to look at the key 7 times to type it in, if I don't type as I'm reading it (which is reasonable for people who aren't secretaries or programmers). It would take 13 words to represent this key (log(36^35) / log (16,100)). I can remember about 4 of these words at a time, meaning I can type them in 3-4 groups, almost half as many as for the string of random characters.
However, there's one more thing to consider, which is actually a facet of something already mentioned: most people aren't secretaries or programmers. They probably can't type even half as quickly as I can. In addition to the previously stated implications, this also means that they're going to have at least twice as long as I do to remember the words/characters, and 13 words would be a total of 75 characters (average word length of 5.75 letters). And unlike registers in a CPU, the brain's registers lose the information they were holding fairly quickly. Unfortunately, I don't really have any way of quantifying this effect, like I was able to benchmark how much I could remember and type in, so this really remains an unknown.
Let's apply some basic psychology to the problem: the brain only has so many registers (bits of information that it can hold readily available without requiring effort to memorize the information; I think the exact number is like 5), with each one able to hold a symbol (remember that the brain's processing abilities are highly symbolic). For a random alphanumeric string, each character must be stored in a separate register (if you think that's dehumanizing, you should see the occasional debates me, DB, and BZ - all of us programmers, but all of us also interested in biology - have on the topic of reproduction and evolutionary psychology; and yes, I am aware that "me" isn't technically a subjective pronoun). For a string of, say, numbers where a pattern is evident, the brain can apply compression to the string, and store a larger number of numbers in its registers than it would be able to if there was no pattern.
So, my idea is simply this: use symbols larger than letters and numbers in the license key. This one dictionary I picked for this purpose has 16,100 English words of 7 characters or less (a somewhat arbitrary limitation I established), and that's not even including conjugations of most verbs.
Let's see how well this works. If we take the NWN key, the maximum number of theoretically possible keys is about 3*10^54 (36^35; quiz: how many bits is that?). I can remember about 5 characters at a time, meaning I will have to look at the key 7 times to type it in, if I don't type as I'm reading it (which is reasonable for people who aren't secretaries or programmers). It would take 13 words to represent this key (log(36^35) / log (16,100)). I can remember about 4 of these words at a time, meaning I can type them in 3-4 groups, almost half as many as for the string of random characters.
However, there's one more thing to consider, which is actually a facet of something already mentioned: most people aren't secretaries or programmers. They probably can't type even half as quickly as I can. In addition to the previously stated implications, this also means that they're going to have at least twice as long as I do to remember the words/characters, and 13 words would be a total of 75 characters (average word length of 5.75 letters). And unlike registers in a CPU, the brain's registers lose the information they were holding fairly quickly. Unfortunately, I don't really have any way of quantifying this effect, like I was able to benchmark how much I could remember and type in, so this really remains an unknown.
Sunday, July 02, 2006
& Linguistics - Case - Japanese 2
Anyway, getting back to the topic of the series, Japanese is unusual in (at least) one more way: it does not use case at all. Well, not technically, anyway. Instead, Japanese has about ten half-cases indicated by postposition (the opposite of prepositions) particles.
The emphatic nominative case (my name for it) is indicated by the postposition "ga", as in "anata wa watashi ga doko nimo inai to omotteru" ("You think that I don't exist"; you can get additional meaning out of this sentence after reading the next paragraph). This is like the nominative case, but it carries an additional property - it serves to emphasize the subject as opposed to the predicate (this is not clearly illustrated in the example).
The referential case (also my name; sometimes called the absolute case) is indicated by "wa". The referential case can be used in several ways. It can be used for the subject of the sentence, where the predicate is more important than the subject; kind of a "non-emphatic nominative" case. But it can also be used to set the point of reference of the sentence, which might not be the same as the subject; this would be translated as "with regard to" or "as for". This distinction is beautifully illustrated by "anata wa kodoku ga koko kara kieru to omotteru" ("I think that the loneliness [that] you [feel] will disappear from now on"; more literally, "for you, [the] loneliness will disappear from now on, [I] think").
"no" indicates the genitive case. Fully understanding the Japanese genitive case requires a small shift in paradigm. The genitive case conveys the general thought of "of", in its various meanings. This can either be in terms of possession (e.g. "hoshi no michibiki" - "star's guidance"), origin (e.g. "hontou no watashi" - "real me" or "me of reality") or distinguishing quality (e.g. "mizuiro no lute" - "light blue lute" or "lute of light blue"), reason or benefactor (e.g. "oya no mo" - "mourning for parents" or "mourning of parents"). The first three are nothing we haven't seen before in other common languages, but the last two (known as the benefactive or causative cases in other languages) are not like the genitive of previous languages.
The accusative case is indicated by "wo" (or "o"). This is trivial, and exactly like what we've seen previously (e.g. "tamashii no hanashi wo kikasete yo" - "Tell [me] the story of your soul"; "yo" indicates a request). However, when translating between English and Japanese, this can be a bit tricky, because we are used to some English verbs being intransitive and requiring a preposition, where the corresponding verbs are transitive in Japanese, and do not require a postposition.
"ni" indicates the locative case. This case represents the idea of being at some general position in space or time - either at, in, on, or around. This has a couple meanings. With verbs of existence, the meaning of position is used (e.g. "sora ni aru tobira" - "door [that is] in the sky").
This idea of position is applied in a similar but slightly different manner to yield the second meaning - that of recipient. In English we have the concept of having something on you - that is, possessing something; Japanese does, as well. In Japanese, "ni" is also used to indicate the target of a verb of transfer of possession. Think about it like this: in Japanese, you don't give something to someone - you put it on someone. In other words, the locative case is used where other languages would use the dative case (e.g. "kodomo ni yaru" - "give to [the] child").
(part 2 of 3)
The emphatic nominative case (my name for it) is indicated by the postposition "ga", as in "anata wa watashi ga doko nimo inai to omotteru" ("You think that I don't exist"; you can get additional meaning out of this sentence after reading the next paragraph). This is like the nominative case, but it carries an additional property - it serves to emphasize the subject as opposed to the predicate (this is not clearly illustrated in the example).
The referential case (also my name; sometimes called the absolute case) is indicated by "wa". The referential case can be used in several ways. It can be used for the subject of the sentence, where the predicate is more important than the subject; kind of a "non-emphatic nominative" case. But it can also be used to set the point of reference of the sentence, which might not be the same as the subject; this would be translated as "with regard to" or "as for". This distinction is beautifully illustrated by "anata wa kodoku ga koko kara kieru to omotteru" ("I think that the loneliness [that] you [feel] will disappear from now on"; more literally, "for you, [the] loneliness will disappear from now on, [I] think").
"no" indicates the genitive case. Fully understanding the Japanese genitive case requires a small shift in paradigm. The genitive case conveys the general thought of "of", in its various meanings. This can either be in terms of possession (e.g. "hoshi no michibiki" - "star's guidance"), origin (e.g. "hontou no watashi" - "real me" or "me of reality") or distinguishing quality (e.g. "mizuiro no lute" - "light blue lute" or "lute of light blue"), reason or benefactor (e.g. "oya no mo" - "mourning for parents" or "mourning of parents"). The first three are nothing we haven't seen before in other common languages, but the last two (known as the benefactive or causative cases in other languages) are not like the genitive of previous languages.
The accusative case is indicated by "wo" (or "o"). This is trivial, and exactly like what we've seen previously (e.g. "tamashii no hanashi wo kikasete yo" - "Tell [me] the story of your soul"; "yo" indicates a request). However, when translating between English and Japanese, this can be a bit tricky, because we are used to some English verbs being intransitive and requiring a preposition, where the corresponding verbs are transitive in Japanese, and do not require a postposition.
"ni" indicates the locative case. This case represents the idea of being at some general position in space or time - either at, in, on, or around. This has a couple meanings. With verbs of existence, the meaning of position is used (e.g. "sora ni aru tobira" - "door [that is] in the sky").
This idea of position is applied in a similar but slightly different manner to yield the second meaning - that of recipient. In English we have the concept of having something on you - that is, possessing something; Japanese does, as well. In Japanese, "ni" is also used to indicate the target of a verb of transfer of possession. Think about it like this: in Japanese, you don't give something to someone - you put it on someone. In other words, the locative case is used where other languages would use the dative case (e.g. "kodomo ni yaru" - "give to [the] child").
(part 2 of 3)
& Linguistics - Case - Japanese 1 (UPDATED)
So, last post I discussed Finnish, a language unusual in that it has an overabundance of grammatical cases (far too many, as far as I'm concerned). This time I'm going to discuss an all-around unusual language (at least to us English/romance-language speakers): Japanese.
Japanese does a great many things notably differently than the languages common on this hemisphere. For example, unlike English, where every clause (save for imperative sentences) must have a subject, in Japanese it is perfectly acceptable (if not likely) for a sentence to lack a subject. Nor is it like romance languages, where the subject is implied in the verb, as the verb is inflected (it is written/spoken differently in different circumstances - declension is one type of inflection) for what pronoun the sentence refers to; no, Japanese sentences can totally and completely lack a subject, leaving listeners to deduce the subject from other sentences.
Japanese sentences are usually written/spoken in reverse-Polish (henceforth known as "Japanese") notation. If you picture a sentence as a syntax tree, child nodes are usually written preceding their parents in the tree, with the sentence ending with the verb and any sentence suffix, such as "ka" (indicating a question). For example, "mienai basho made hashiru nara" - "If you run to the unseen place" - literally "[you] not-seen place to run if".
Japanese completely lacks any dedicated personal pronouns. There are no words like "he", "she", etc. Instead, it commandeers a number of common nouns for this purpose, some examples being "watashi" ("selfishness") and "boku" ("servant" - used specifically by males) for the first person, or "kimi" ("prince") and "anata" ("over there" - something of a literal translation of "Hey, you!" although not as rude) for the second person.
Japanese also lacks grammatical gender and number. That is, it does not inflect its nouns, adjectives, or verbs based on the gender or number of the noun. For comparison, romance languages inflect nouns, adjectives, and verbs based on both gender and number; English, however, only inflects its nouns and verbs by number.
Japanese completely lacks articles, like Latin (but unlike English, Spanish, or Portuguese). But perhaps the oddest quality is that adjectives are half-verbs. It's possible to conjugate adjectives like verbs - complete with tense - and they are able to completely take the place of verbs in a sentence.
Japanese does a great many things notably differently than the languages common on this hemisphere. For example, unlike English, where every clause (save for imperative sentences) must have a subject, in Japanese it is perfectly acceptable (if not likely) for a sentence to lack a subject. Nor is it like romance languages, where the subject is implied in the verb, as the verb is inflected (it is written/spoken differently in different circumstances - declension is one type of inflection) for what pronoun the sentence refers to; no, Japanese sentences can totally and completely lack a subject, leaving listeners to deduce the subject from other sentences.
Japanese sentences are usually written/spoken in reverse-Polish (henceforth known as "Japanese") notation. If you picture a sentence as a syntax tree, child nodes are usually written preceding their parents in the tree, with the sentence ending with the verb and any sentence suffix, such as "ka" (indicating a question). For example, "mienai basho made hashiru nara" - "If you run to the unseen place" - literally "[you] not-seen place to run if".
Japanese completely lacks any dedicated personal pronouns. There are no words like "he", "she", etc. Instead, it commandeers a number of common nouns for this purpose, some examples being "watashi" ("selfishness") and "boku" ("servant" - used specifically by males) for the first person, or "kimi" ("prince") and "anata" ("over there" - something of a literal translation of "Hey, you!" although not as rude) for the second person.
Japanese also lacks grammatical gender and number. That is, it does not inflect its nouns, adjectives, or verbs based on the gender or number of the noun. For comparison, romance languages inflect nouns, adjectives, and verbs based on both gender and number; English, however, only inflects its nouns and verbs by number.
Japanese completely lacks articles, like Latin (but unlike English, Spanish, or Portuguese). But perhaps the oddest quality is that adjectives are half-verbs. It's possible to conjugate adjectives like verbs - complete with tense - and they are able to completely take the place of verbs in a sentence.
Saturday, June 24, 2006
& Linguistcs - Case - Finnish
So, for the last two posts in this series, I've got a couple languages unlike the ones already discussed (at least with respect to case). This post's topic is Finnish, a language different in that it relies much less on prepositions than any of the languages mentioned so far. This is possible due to a large number of cases that fill the role that would otherwise be filled using prepositions.
Finnish declines its nouns, pronouns and adjectives, and a number of disputed cases exist, where it is debatable whether they are actual cases, or merely forms of creating adverbs from adjectives or nouns.
The definitive cases in Finnish are *takes a deep breath*: nominative, genitive, accusative, partitive, inessive, elative, illative, adessive, ablative, allative, essive, translative, translative, abessive, and comitative.
The accusative case is slightly different in meaning than the accusative of the other languages we have examined. In Finnish, the accusative case refers to the direct object, where the entirety of the direct object is involved in the action. This is in contrast to the partitive case, which refers either to a portion of a single object, to a number of objects which are a portion of a greater number of objects, or to an incomplete action.
The inessive case of an object (or even a point in time) refers to something else being contained inside that object (think of "in"; or "at" or "on", with respect to a point in time). Similarly but distinctly, the adessive case refers to existence near some object, such as "on", "near", or "around".
The elative case implies movement out of an object or a point in time (think of "out of", "from", or "since"). The illative indicates just the opposite: movement into an object or a point in time (such as "into" or "until").
Similarly, the ablative case conveys movement off the surface of an object, such as "off of" or "from". The allative is the opposite, indicating movement onto an object, such as "onto", "to", and "for". Both may be used to also indicate a change in possession.
The essive case seems to indicate a temporary state, or partition of time in which some action occurs (think "as", "when", "on", "in", etc.); looking at some examples of the essive case, it is not wholly clear to me how this differs from some of the other cases. The translative case indicates a change in state, property, or composition, corresponding to "into" or "to". The abessive case seems to be dying out in the language, and indicates the lack of something (essentially "without"). Finally, the instructive case indicates a means of action, such as "with", "by", or "using".
15 in all. Man, that's way too many cases. I'm tired out just from writing about them :P Note also that I've tried to give a description of the cases in an intuitive manner, reducing each to a single concept, perhaps applied in different ways. But some cases also have uses that aren't intuitive (at least not to me).
Friday, June 23, 2006
& Linguistics - Case - Spanish/Portuguese
Last post we looked at the decline of the English language (pun intended, I'm afraid); this post we'll look at the decline of the Latin language. What exactly do I mean by 'decline'? Well, exactly what I mentioned at the end of the last post: the simplification of grammar in languages over time.
Now, Latin is a dead language, but its derivatives live on. The flavor of the day: Portuguese and Spanish. Very much like English, Spanish and Portuguese have almost entirely given up the system of declension. Adjectives have completely lost the system of declension (although, unlike English, adjectives are still inflected based on gender and number of the noun they modify), as have nouns (an even more radical decline than English, which retains two distinct cases for nouns).
Spanish and Portuguese pronouns come in six cases: nominative (e.g. yo/eu), genitive (e.g. mi/meu), accusative (e.g. me/me), dative (e.g. me/me), ablative (e.g. mí/mim), and comitative (e.g. migo/migo). The first five are roughly equivalent to the same cases in Latin (the ablative is only different in that it can't imply pronouns as the ablative case in Latin can), but the last one is a bit more interesting.
That's the accepted explanation, anyway; and perhaps the correct one. But while I was doing my research, I came across something very interesting. The comitative case also exists in Estonian, an east-European language. In Estonian, the comitative case is formed by adding the suffix -ga to either the genitive or the partitive case. Maybe that's just coincidence, but you've got to admit the probability of two languages using very similar form for the same function by pure chance is rather low; enough to be intriguing.
Freakin' Awesome
Saw this on Slashdot earlier today:
Researchers led by the Institute of Cognitive Science and Technology in Italy are developing robots that evolve their own language, bypassing the limits of imposing human rule-based communication.
...The most important aspect is how it learns to communicate and interact. Whereas we humans use the word ‘ball’ to refer to a ball, the AIBO dogs start from scratch to develop common agreement on a word to use to refer the ball. They also develop the language structures to express, for instance, that the ball is rolling to the left. The researchers achieved this through instilling their robots with a sense of ‘curiosity.’
Initially programmed to merely recognise stimuli from their sensors, the AIBOs learnt to distinguish between objects and how to interact with them over the course of several hours or days. The curiosity system, or ‘metabrain,’ continually forced the AIBOs to look for new and more challenging tasks, and to give up on activities that did not appear to lead anywhere. This in turn led them to learn how to perform more complex tasks, an indication of an open-ended learning capability much like that of human children.
Also like children, the AIBOs initially started babbling aimlessly until two or more settled on a sound to describe an object or aspect of their environment, gradually building a lexicon and grammatical rules through which to communicate.
That is absolutely godly. I want a litter of those.
Tuesday, June 20, 2006
& Linguistics - Case - English
English is near the opposite end of the spectrum, compared to Latin, having only remnants of a previously existing case system.
Pronouns are the most vivid artifact of old English declension, having three cases: subjective, objective, and possessive. The subjective, corresponding to the Latin nominative, refers to the subject of the sentence (e.g. "I still believe that you can call out my name"); the possessive, corresponding to the Latin genitive, refers to the possessor of some other noun (e.g. "in my dearest memories"); finally, the objective, corresponding to the Latin accusative, dative, and ablative, refers to anything not a part of the other two cases (e.g. "I see you reaching out to me"). If you think about it for a minute, you'll realize that some distinct cases of the same pronoun are identical (e.g. the subjective and objective forms of "you").
For nouns, the subjective and objective cases are identical (e.g. "Kaity"). The possessive case, however, remains distinct (e.g. "Kaity's).
Interestingly, Old English used to have five cases: nominative, accusative, dative, genitive, and instrumental; as well, not only pronouns and common nouns, but also adjectives were declined. The instrumental case refers to the means by which the action of the sentence is performed. If Latin had had an instrumental case, "with burning truth" would probably have used it (but not "until the fated day", despite the fact that both use the ablative case in Latin). Interestingly, Old English lacked an ablative case; presumably the reason for this is that it relied on propositions to fill this role, as does modern English.
And for a few tangentially related bonus topics. I looked it up today, and vizzini (who is actually my boss) is right: proper nouns are declined in Latin. Also, I just had a question pop into my head: if we're evolving from simple to complex, why are languages evolving in the exact opposite way - English, Greek, etc.?
Pronouns are the most vivid artifact of old English declension, having three cases: subjective, objective, and possessive. The subjective, corresponding to the Latin nominative, refers to the subject of the sentence (e.g. "I still believe that you can call out my name"); the possessive, corresponding to the Latin genitive, refers to the possessor of some other noun (e.g. "in my dearest memories"); finally, the objective, corresponding to the Latin accusative, dative, and ablative, refers to anything not a part of the other two cases (e.g. "I see you reaching out to me"). If you think about it for a minute, you'll realize that some distinct cases of the same pronoun are identical (e.g. the subjective and objective forms of "you").
For nouns, the subjective and objective cases are identical (e.g. "Kaity"). The possessive case, however, remains distinct (e.g. "Kaity's).
Interestingly, Old English used to have five cases: nominative, accusative, dative, genitive, and instrumental; as well, not only pronouns and common nouns, but also adjectives were declined. The instrumental case refers to the means by which the action of the sentence is performed. If Latin had had an instrumental case, "with burning truth" would probably have used it (but not "until the fated day", despite the fact that both use the ablative case in Latin). Interestingly, Old English lacked an ablative case; presumably the reason for this is that it relied on propositions to fill this role, as does modern English.
And for a few tangentially related bonus topics. I looked it up today, and vizzini (who is actually my boss) is right: proper nouns are declined in Latin. Also, I just had a question pop into my head: if we're evolving from simple to complex, why are languages evolving in the exact opposite way - English, Greek, etc.?
Monday, June 19, 2006
& Linguistics - Case - Latin
Today I'm going to go into a bit of a different topic - linguistics. Why? Because I feel like it. Specifically, I'm going to talk about case *ahem*
Case refers to alterations ("declension") of nouns and possibly adjectives, based not on what the nouns/adjectives refer to (though they usually do that, too), but in what manner they are used in the sentence in which they appear (phrased differently, what grammatical role they play).
The stereotypical declined language is Latin. All common (as opposed to proper) nouns and adjectives are declined - the exact word used depends on the case, in addition to other things like gender and number. Latin has six distinct cases: nominative, genitive, accusative, dative, ablative, and vocative. The nominative case refers to the subject of the sentence ("somnus non est" - "the sleep is no more"); the genitive case refers to the possessive ("invenite hortum veritatis" - "find the garden of truth"); the accusative case refers to the direct object ("urite mala mundi") "burn the evil of this world"); the dative case refers to the indirect object (e.g. "dona nobis pacem" - "give us peace" *); the ablative case being like the object of a preposition ("ardente veritate" - "with burning truth"); finally, the vocative case is used when speaking to someone ("exitate vos e somno, liberi fatali" - "arise from your sleep, fated children"). There's also a locative case, but that's rare, and sometimes omitted from dictionaries (and, more importantly, I'm not familiar with it).
If you were particularly alert, you might have noticed some things in those examples. Like the difference between "veritatis" and "veritate", "somnus" and "somno" (different cases of the same nouns); or the similarity between "ardente" and "veritate", "liberi" and "fatali" (paired adjectives and nouns in the same case). Or you might have even noticed in "ardente veritate" or "diebus fatalibus" ("until the fated day" - not shown previously), examples of the ablative case, that there is no proposition at all ("with" and "until", in English).
The use of a moderate set of cases in Latin (and the fact that nouns and adjectives are declined) make it a language that lends itself to poetry. Similar suffixes provide natural rhyming of similar thought patterns; the fact that sentence structure is determined by word form rather than word order allows free arranging of words in a sentence (within reason) while retaining meaning. The ablative case lends itself to poetic use, as well, but not in an immediately obvious manner. As the use of the ablative can imply the existence of a preposition without ever stating it (though there are also prepositions which may be explicitly used), it serves to reduce the precision of the language (as it's possible that more than one preposition would be appropriate in a given context), and lends itself to poetic metaphorical constructs.
* Sorry, there is no use of the dative case in Liberi Fatali, so I had to borrow one from Salva Nos
Thursday, June 08, 2006
Day One
So, day one is officially over. Despite the fact that I have yet to be assigned any actual work, I managed to be halfway productive. During the second meeting for the three n00bs of us, something one of the guys said made me think he worked on Boost. So, after the meeting, I asked him if he did (he actually didn't, he just used it), and told him about LibQ (a "competing product"). He said I should send him a link, and he'd check it out.
10 or 15 minutes later, back at my computer, I decide to venture into the company's product. Double-click and... it fails to start with some vague error message. I call over Skywing, who spends half an hour or so debugging it and looking through the debug logs, to locate the cause. His first attempt to debug it used some debugger I'm not familiar with ("SD"). This resulted in the debugger crashing... repeatedly. Highly amused (it was pretty funny), Skywing ran over to the boss to tell him "Hey, Justin crashed SD!" The boss responded with something along the lines of "He what?!". "I'm not touching your LibQ!" followed closely, from another cubicle.
Despite the fact that he was joking (and it was actually pretty funny), LibQ ended up having the last laugh. Later in the day, I was randomly looking through the source code for their program (I figured that would be helpful when I, you know, actually have some work to do). After not too long, I found a piece of code that immediately set off red lights in my head. While it apparently works on Linux (that's what their server platform is), it will break on some versions of Unix (like OS X), should they ever decide to offer the program for other Unixes (which our boss, who's half coder, is actually working on, in whatever time he doesn't spend doing managerish stuff). So I filed my first bug report, in which I explained the problem, and referred them to the solution I used in LibQ (yes, I actually mentioned LibQ in the bug report).
10 or 15 minutes later, back at my computer, I decide to venture into the company's product. Double-click and... it fails to start with some vague error message. I call over Skywing, who spends half an hour or so debugging it and looking through the debug logs, to locate the cause. His first attempt to debug it used some debugger I'm not familiar with ("SD"). This resulted in the debugger crashing... repeatedly. Highly amused (it was pretty funny), Skywing ran over to the boss to tell him "Hey, Justin crashed SD!" The boss responded with something along the lines of "He what?!". "I'm not touching your LibQ!" followed closely, from another cubicle.
Despite the fact that he was joking (and it was actually pretty funny), LibQ ended up having the last laugh. Later in the day, I was randomly looking through the source code for their program (I figured that would be helpful when I, you know, actually have some work to do). After not too long, I found a piece of code that immediately set off red lights in my head. While it apparently works on Linux (that's what their server platform is), it will break on some versions of Unix (like OS X), should they ever decide to offer the program for other Unixes (which our boss, who's half coder, is actually working on, in whatever time he doesn't spend doing managerish stuff). So I filed my first bug report, in which I explained the problem, and referred them to the solution I used in LibQ (yes, I actually mentioned LibQ in the bug report).
Ding dong, the witch is dead!
Abu Musab al-Zarqawi, the al-Qaida leader in Iraq who waged a bloody campaign ofhttp://msnbc.msn.com/id/13195017/
suicide bombings and beheadings of hostages, has been killed in a precision
airstrike, U.S. and Iraqi officials said Thursday. It was a long-sought victory
in the war in Iraq.
Wednesday, June 07, 2006
Toto, I've a feeling we're not in California, anymore
And this is Q, reporting live from Kansas. Squid and I are here at a motel after a remarkably long day beginning with a 4 AM wakeup time, and including a 2400 mile flight taking 7 hours. Amusingly, Squid's carry-on bag set off the bomb detector, although that was resolved after a bit. I'm here for an internship at the company Skywing works for; Squid was just bored, and figured that out of state travel would be amusing.
Anyway, I'm too sleepy to think straight, and these phantom flight sensations are getting on my nerves. I think it's time for bed.
...and this laptop they're letting me borrow just started making an odd noise.
Anyway, I'm too sleepy to think straight, and these phantom flight sensations are getting on my nerves. I think it's time for bed.
...and this laptop they're letting me borrow just started making an odd noise.
Sunday, June 04, 2006
So I Was Bored and...
...looking through articles on lock-free data structures. Amusingly, one that looked interesting was by the author of Hoard - Quantifying the Performance of Garbage Collection vs. Explicit Memory Management. I didn't actually read the whole thing, but the conclusions were rather striking:
Comparing runtime, space consumption, and virtual memory footprints over a range of benchmarks, we show that the runtime performance of the best-performing garbage collector is competitive with explicit memory management when given enough memory. In particular, when garbage collection has five times as much memory as required, its runtime performance matches or slightly exceeds that of explicit memory management. However, garbage collection’s performance degrades substantially when it must use smaller heaps. With three times as much memory, it runs 17% slower on average, and with twice as much memory, it runs 70% slower. Garbage collection also is more susceptible to paging when physical memory is scarce. In such conditions, all of the garbage collectors we examine here suffer order-of-magnitude performance penalties relative to explicit memory management.
So, garbage collection doesn't sound so good for practical applications. Interestingly, this apparently debunks my belief that garbage collection was the optimal memory allocation strategy to use for embedded systems that are very tight on memory. Well, maybe, maybe not. I was thinking in terms of memory usage. Garbage collection allows blocks to be relocated in memory, allowing new allocations of arbitrary size to get around fragmentation problems (assuming there's enough free memory, period). But this report shows that doing so would come at a hefty performance cost, which may or may not be tolerable.
GNUPlot Update
It looks like, although even the most recent release version of GNUPlot behaves the same way I described, with regard to loading files, the development version in the CVS now uses exponential vector growth. Unfortunately, if you want to use that version, you'll have to download the source from CVS and compile it yourself, which may not be any easier than using the version with the vector flaw :P
Saturday, June 03, 2006
Another Random Factoid
Yeah, that's more or less how the LFH works, with one key difference: the LFH is mostly lock-free. It's actually similar to but a bit simpler than the one I was going to implement. They also cheat a little: the list of partially filled reserve blocks is protected by a mutex. The allocator I was going to write didn't use a mutex there, because it used some tricky lock-free voodoo. I'm not sure whether or not the lock-free voodoo is worth the trouble - it will be slower when there's no contention, but faster when multiple threads are trying to access the same list. I'm not sure exactly how common an event that will be, though, since most allocations will come out of the current block, and the partial block list is only used when the current block gets full (essentially two threads would have to try to allocate a block from the same zone at the same time, when the current block is full).
Random Factoid
So, today I wondered what type of memory allocator OS X uses. So I looked around the XNU source code a bit, and found that it uses a zone allocator: there are 16 different memory pools (zones), each storing equal-sized blocks. Memory allocations are rounded up to a zone size, and a slot is popped off the corresponding zone like a stack. Each zone is protected by its own mutex. In other words, it's nearly identical to the allocator I want to implement, only it's semi-multi-processor friendly (due to the locks for each zone), as opposed to mine being completely lock-free (and thus full multi-processor friendly).
I suspect the Windows Low-Fragmentation Heap also functions like this, as well. Sometime I should reverse-engineer it to see if it's lock-free or has multiple locks (MSDN says it's multi-processor friendly, so it must at least have multiple zone locks).
I suspect the Windows Low-Fragmentation Heap also functions like this, as well. Sometime I should reverse-engineer it to see if it's lock-free or has multiple locks (MSDN says it's multi-processor friendly, so it must at least have multiple zone locks).
On Vectors and Lists
So, a brief follow-up post to the one about the flaw in GNUPlot: data structures 101. Well, not all data structures, just vectors and lists. I wrote a simple implementation of a vector and a linked list, then benchmarked them while adding a large (the definition of "large" varies by structure) number of items.
Your basic list is very simple: each item is allocated from the heap, and does not require copying of any existing data items at any time. Insertions take O(1), and a string of insertions take O(N), as illustrated by this benchmark:
A vector is an array that gets resized whenever it gets full. When items are merely added to the end of an existing array, additions are O(1), and a series of additions are O(N). However, the process of resizing the array, which requires all existing items be copied, is O(N). This means that if you resize an array after a constant number of additions, additions to a vector will take O(N), and a string of additions will take O(N^2), as illustrated by this benchmark (the two series represent how much additional space was allocated each time the array was resized; 10 is the actual number GNUPlot uses when it reallocates its data array during file loading):
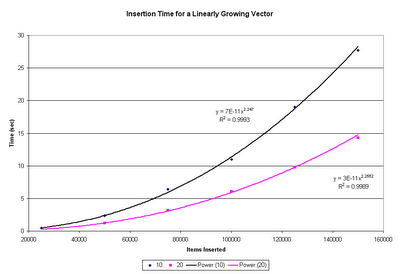
This is the WRONG way to use a vector. The correct way is to increase the size of the vector exponentially. In my benchmark I used a factor of 2 - every time the array became filled, its size was doubled. Since it's growing exponentially, the number of allocations that must be done (each taking O(N)) will be O(1/2^N); O(N * 1/2^N) = 0. Thus the time to reallocate the array is negligible, and the complexity is determined strictly by the time to add each new elements to the already allocated array: O(1) per element, and O(N) for a series of elements. This is shown in the following graph:
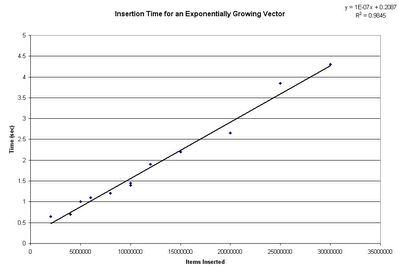
Your basic list is very simple: each item is allocated from the heap, and does not require copying of any existing data items at any time. Insertions take O(1), and a string of insertions take O(N), as illustrated by this benchmark:
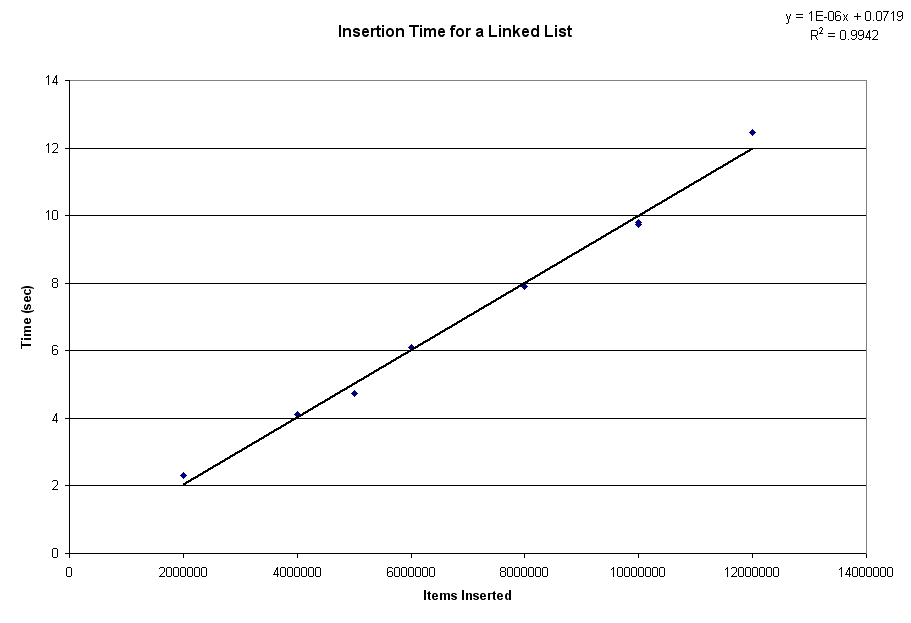
A vector is an array that gets resized whenever it gets full. When items are merely added to the end of an existing array, additions are O(1), and a series of additions are O(N). However, the process of resizing the array, which requires all existing items be copied, is O(N). This means that if you resize an array after a constant number of additions, additions to a vector will take O(N), and a string of additions will take O(N^2), as illustrated by this benchmark (the two series represent how much additional space was allocated each time the array was resized; 10 is the actual number GNUPlot uses when it reallocates its data array during file loading):

This is the WRONG way to use a vector. The correct way is to increase the size of the vector exponentially. In my benchmark I used a factor of 2 - every time the array became filled, its size was doubled. Since it's growing exponentially, the number of allocations that must be done (each taking O(N)) will be O(1/2^N); O(N * 1/2^N) = 0. Thus the time to reallocate the array is negligible, and the complexity is determined strictly by the time to add each new elements to the already allocated array: O(1) per element, and O(N) for a series of elements. This is shown in the following graph:
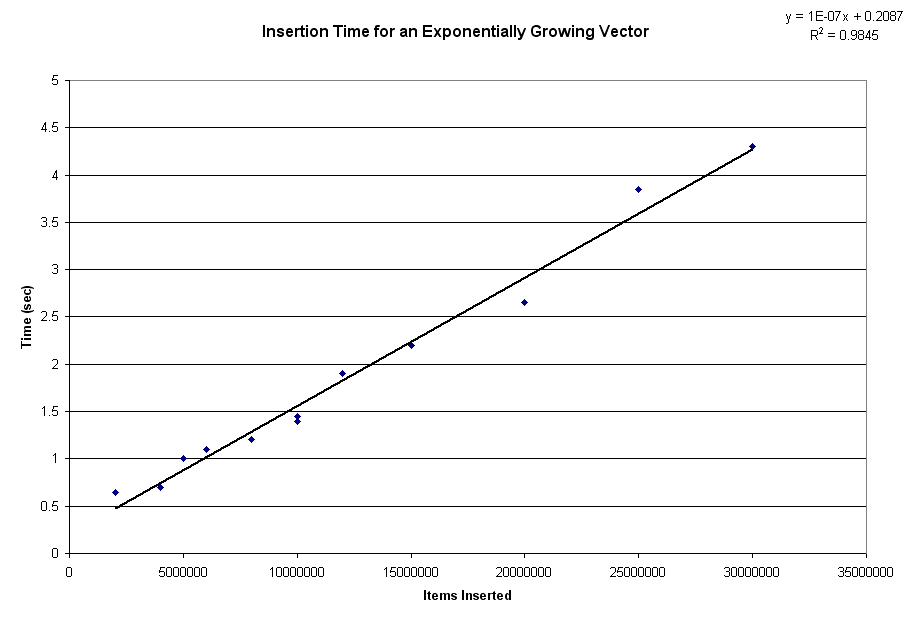
Thursday, June 01, 2006
Regression: The Storm Strikes Back
Well, after messing with GNUPlot for most of the day, I believe I've obtained one of the results I sought: the regression equations for the different allocators. I cut off data points above 100,000 cycles based on looking at a couple plots; nearly all of the points were below 100,000 cycles, but some were significantly above that, and I wanted to minimize skewing due to outlier points. Nevertheless, there was a very large amount of variance in the data set (especially in the case of SMem), so you can expect a fair margin of imprecision. As well, I used the non-linear least-squares algorithm supplied in GNUPlot, which is somewhat susceptible to outlier points; at some point I may try recomputing the regression values using a robust regression method (something less susceptible to outlier points).
I suppose I should be getting used to the results of various experiments in this project surprising me, but I'm not; and this set of data came as one of the biggest surprises, after all the previously collected data. All regressions were performed using the general form m*(N^xp) + b, where m, xp, and b were solved for by the regression algorithm. I performed the graphs of the regression lines as log-log to maximize visibility of differences over the greatest range of points; you should not mistake these for linear graphs (for example, every single regression line was O(N^x), where x was less than 1, usually around 0.5; the log-log graphs, however, seem to suggest x is always greater than 1).
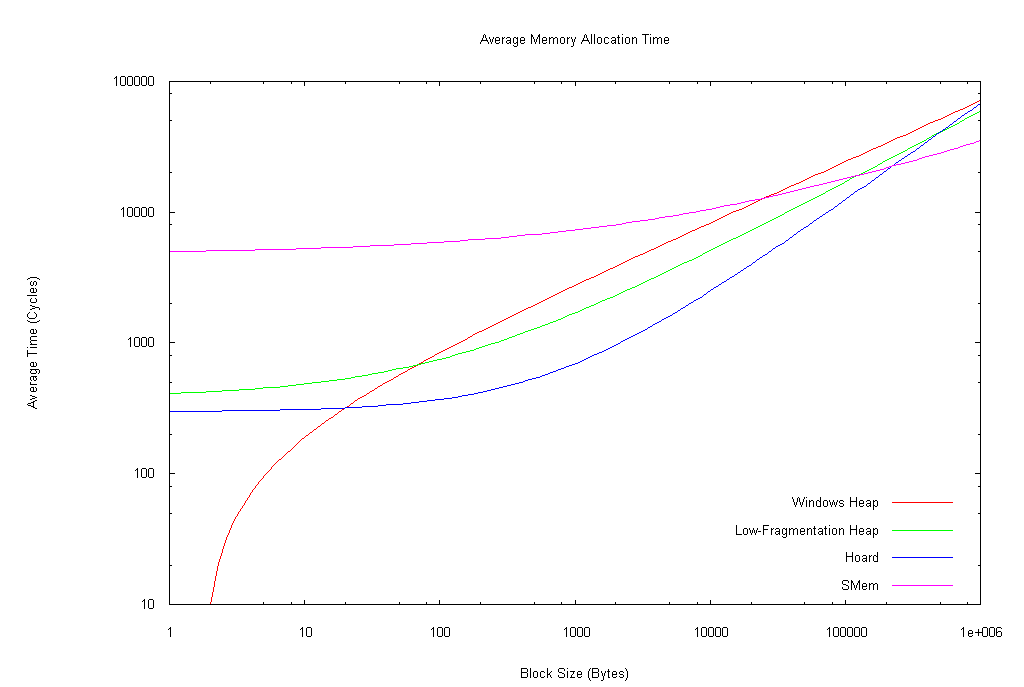
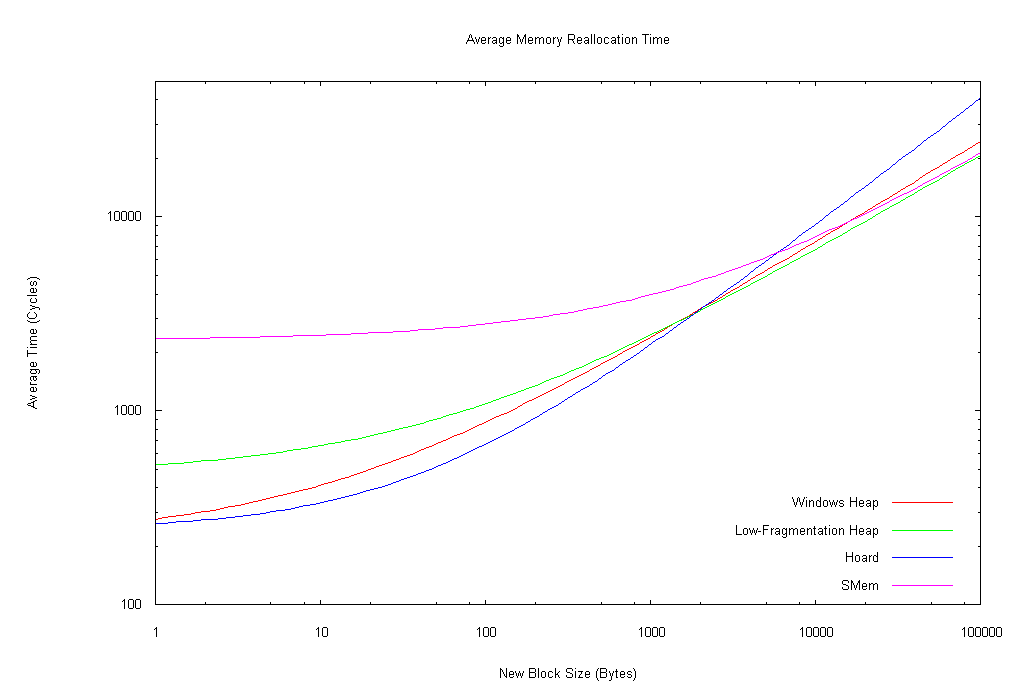
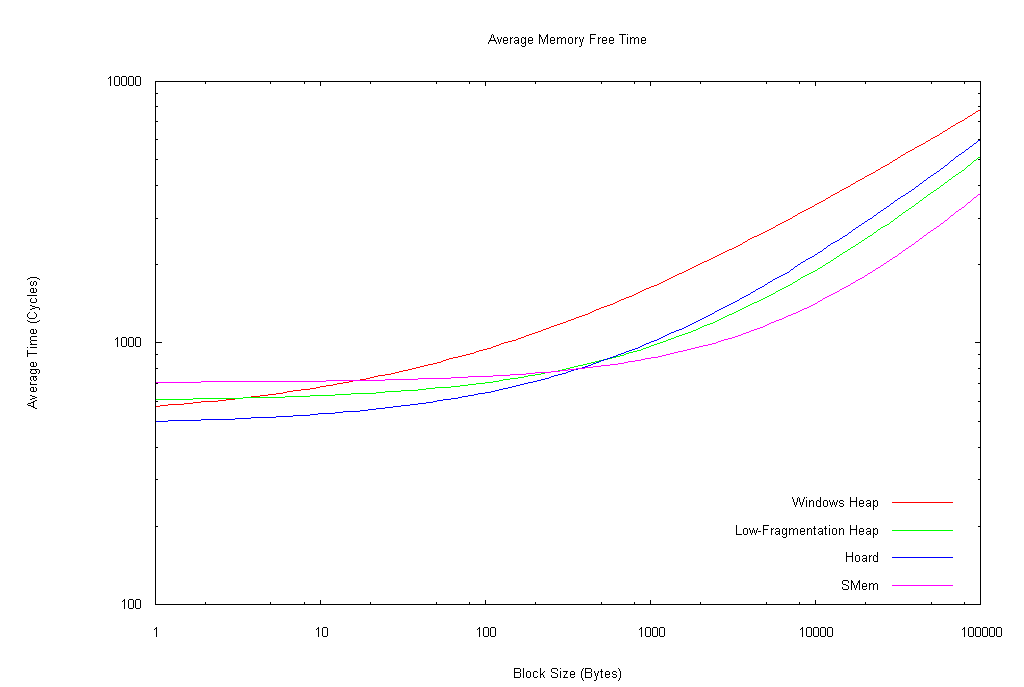
Most notably, SMem (Storm) takes a substantial lead at upper block sizes for allocations and frees (above 220 KB and 371 bytes, respectively); as well, it's not significantly worse than the other heaps at reallocations above about 5 KB. And no, the Windows heap doesn't really get down to negative cycles for allocations approaching 0 bytes; that's just an artifact of the regression calculation.
So, why did Storm perform so poorly in the bar charts? Well, that's relatively easy to offer an explanation for: it's probably because most of the allocations were smaller than Storm is optimal for. Though this does make me think that I should do some real-world tests, like replace all of SMem in Warcraft III with the other allocators, and see how long things like starting up, loading a map, and completing a map take (in other words, looking at clusters of operations that naturally occur together, which my benchmark is unable to take into consideration).
GNUPlot Fun
So, I'm trying to actually graph the full data sets. I believe I mentioned previously that I liked GNUPlot better than some of the others. However, it ended up being obscenely slow - it took 66 minutes to graph the realloc data set, which is about 60 megs large, and contains about 3.3 million data points (don't recall if I mentioned that). This absolutely confounded me. I couldn't conceive of any method that could possibly be that slow. I wrote a little program that used STL streams and extraction to see how long it would take to parse the file myself (keep in mind that STL streams are horribly slow): 2 minutes and 15 seconds.
So, I tried repeating the graph, telling it to graph every 20th data point, to see if the graph quality would be acceptable, while rendering in a reasonable amount of time (66 minutes / 20 = 3 minutes and 18 seconds, right?), using the handy stopwatch on my cell phone. This took 15 seconds. After a brief "OMGWTFBBQ" moment, the solution came to me: it was executing in exponential time. Gathering a few more times (1/17, 1/15, 1/12, 1/10, 1/8, and 1/5) confirmed this hypothesis: it was executing in O(N^2) time.

I can think of one "good" reason why it might be doing that: it's probably storing the data in a vector - a dynamically resizing array. Every time it gets resized, it has to copy the entire data set (which is almost 500 megs, by the end). This would produce the observed O(N^2) time. It also explains an odd behavior I observed while watching the GNUPlot execute in task manager. While loading the file, the memory usage increases over time. But the physical memory usage was ping-ponging all over the freakin place, varying at times by hundreds of megs (up and down) from second to second. I couldn't figure that one out, either; it was way too fast to be due to paging (my first thought). But it makes perfect sense if it's continually reallocating its buffer, copying the contents, and then freeing the old buffer.
*sigh* It seems like lately every program I've used I've needed to debug some catastrophic flaw in it. I have enough to do with debugging my own programs; you people need to leave me alone :P
So, I tried repeating the graph, telling it to graph every 20th data point, to see if the graph quality would be acceptable, while rendering in a reasonable amount of time (66 minutes / 20 = 3 minutes and 18 seconds, right?), using the handy stopwatch on my cell phone. This took 15 seconds. After a brief "OMGWTFBBQ" moment, the solution came to me: it was executing in exponential time. Gathering a few more times (1/17, 1/15, 1/12, 1/10, 1/8, and 1/5) confirmed this hypothesis: it was executing in O(N^2) time.
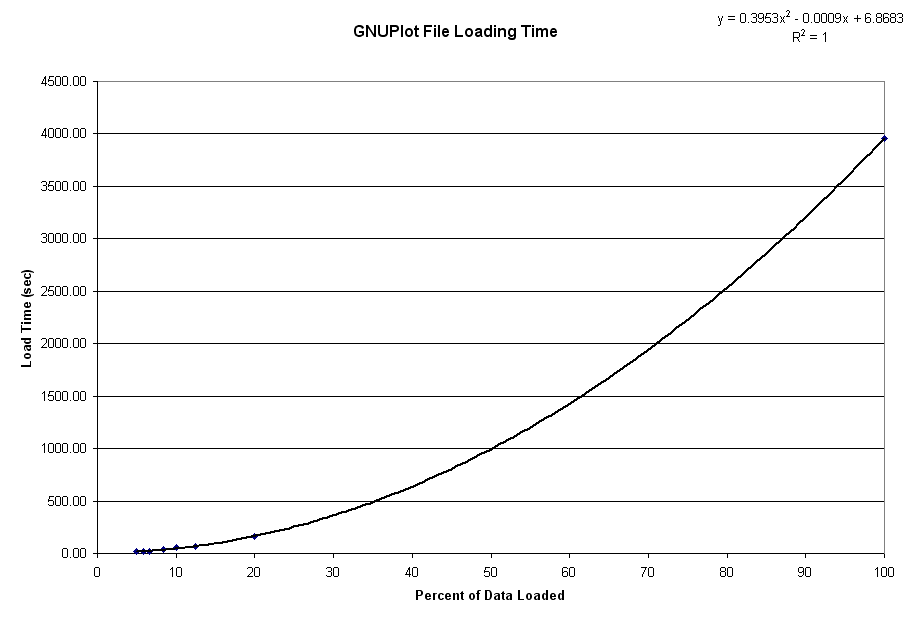
I can think of one "good" reason why it might be doing that: it's probably storing the data in a vector - a dynamically resizing array. Every time it gets resized, it has to copy the entire data set (which is almost 500 megs, by the end). This would produce the observed O(N^2) time. It also explains an odd behavior I observed while watching the GNUPlot execute in task manager. While loading the file, the memory usage increases over time. But the physical memory usage was ping-ponging all over the freakin place, varying at times by hundreds of megs (up and down) from second to second. I couldn't figure that one out, either; it was way too fast to be due to paging (my first thought). But it makes perfect sense if it's continually reallocating its buffer, copying the contents, and then freeing the old buffer.
*sigh* It seems like lately every program I've used I've needed to debug some catastrophic flaw in it. I have enough to do with debugging my own programs; you people need to leave me alone :P
Subscribe to:
Posts (Atom)

